本文主要是介绍51-42 NÜWA:女娲,统一的多模态预训练模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
21年11月,微软、北大联合发布了NUWA模型,一个统一的多模态预训练模型,在 8 个下游任务上效果惊艳。目前该项目已经发展成为一系列工作,而且都公开了源代码。

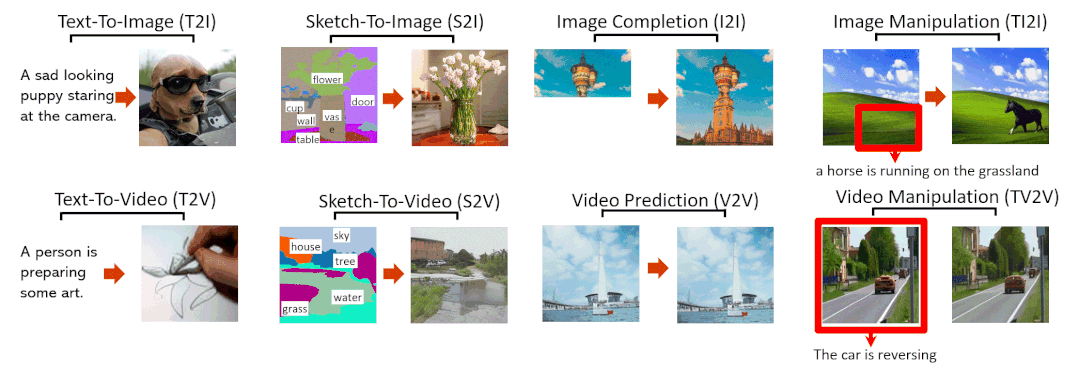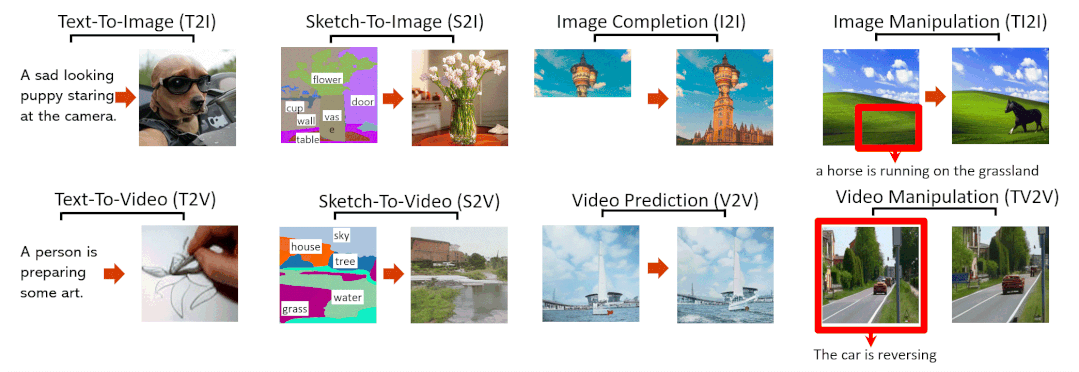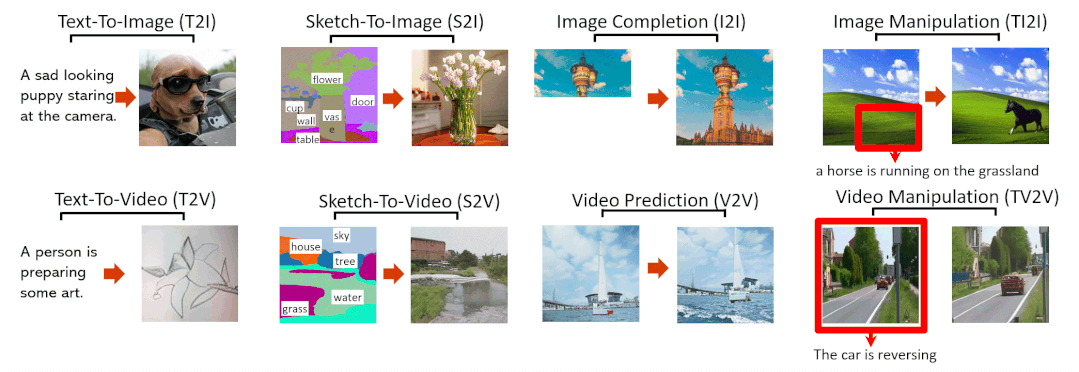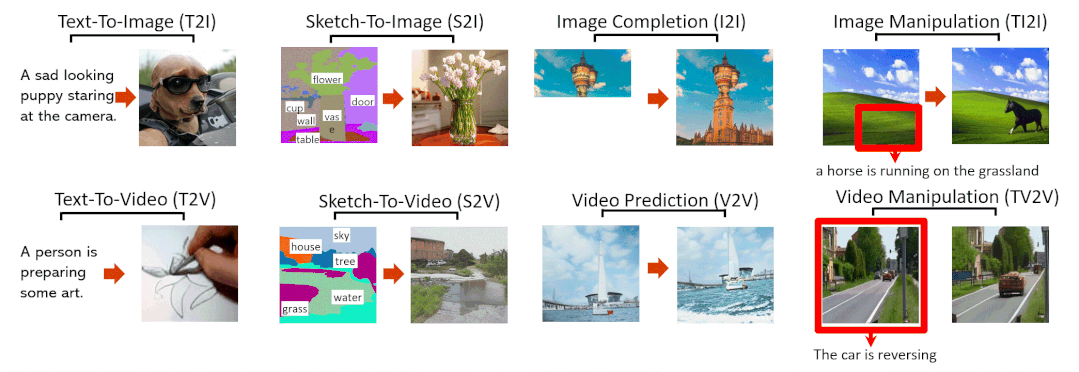
Abstract
本文提出了一种统一的多模态预训练模型N̈UWA,该模型可以实现各种视觉合成任务,包括生成新的或操作现有的视觉数据(即图像和视频)。为了同时处理不同场景的语言、图像和视频,本文设计了一个 3D transformer 编码器-解码器框架,它不仅可以将视频作为 3D 数据处理,还可以适配文本和图像作为 1D 和 2D 数据。考虑视觉数据的性质并降低计算复杂度,本文还提出了一种 3D Nearby Attention(3DNA)邻域自注意机制。我们在 8 个下游任务上评估了 N̈UWA,与几个强基线相比,N̈UWA在文生图像、文生视频、视频预测等方面取得了最先进的结果。此外,它还显示出在文本引导图像和视频操作任务上惊人的zero-shot能力。
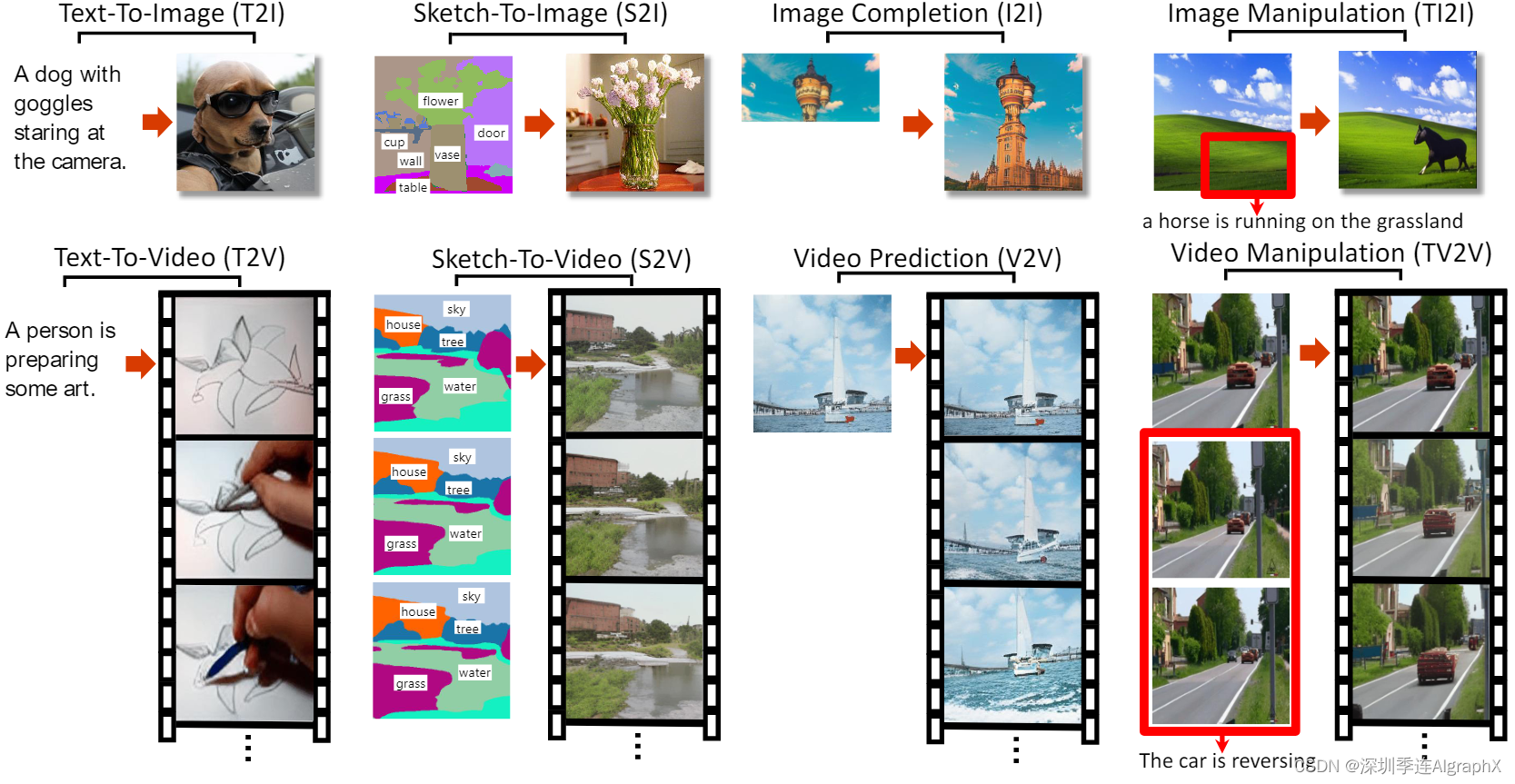
Figure 1, Examples of 8 typical visual generation and manipulation tasks supported by the NN̈WA model.
1. Introduction
如今,WEB比以往任何时候都更加视觉,因为图像和视频已经成为新的信息载体,并已被用于许多实际应用。在此背景下,构建可以为各种视觉场景生成新的或操纵现有视觉数据(即图像和视频)的模型,正在成为一个越来越流行的研究课题。
与GANs相比,自回归模型Auto-regressive在视觉合成任务中扮演着重要的角色,因为它们的显式密度建模和稳定的训练优势。早期的视觉自回归模型,如PixelCNN、PixelRNN、Image Transformer、iGPT和Video Transformer,以“逐像素”的方式执行视觉合成。然而,由于其对高维视觉数据的高计算成本,这种方法只能应用于低分辨率图像或视频,难以扩大规模。
最近,随着VQ-VAE作为一种离散视觉token化方法的出现,高效和大规模的预训练可以应用于图像(如DALL-E和CogView)和视频(如GODIVA)的合成任务。尽管这取得了巨大的成功,但这些解决方案仍然存在局限性——它们分开处理图像和视频,并专注于生成其中之一。这限制了模型从图像和视频数据中受益。
在本文中,我们提出了N̈UWA,一个统一的多模态预训练模型,旨在支持图像和视频的视觉合成任务,并对 8个下游任务进行了实验,如图 1 所示。
本工作有三个主要贡献:
- 提出了N̈UWA,一个通用的3D transformer编码器-解码器框架,它同时针对不同的视觉合成任务,覆盖语言、图像和视频。它由一个自适应编码器,该编码器将文本或视觉草图作为输入,以及一个由 8 个视觉合成任务共享的解码器组成。
- 提出了一种 3D Nearby Attention (3DNA) 邻域自注意机制,综合考虑空间和时间轴的局部特征。3DNA不仅降低了计算复杂度,而且提高了生成视觉任务质量。
- 与几个强基线相比,N̈UWA在文生图、文生视频、视频预测等方面取得了最先进的结果。此外,N̈UWA不仅在文本引导的图像处理上表现出良好的零样本能力,而且在文本引导的视频操作方面也表现出了令人惊讶的zero-shot能力。
2. Related Works
2.1. Visual Auto-Regressive Models
本文提出的方法遵循基于自回归模型的图像合成研究路线。早期的视觉自回归模型以“逐像素”的方式执行视觉合成。然而,由于高维数据建模时的计算成本较高,这种方法只能应用于低分辨率图像或视频,难以扩大规模。
最近,基于VQ-VAE的视觉自回归模型被提出用于视觉合成任务。通过将图像转换为离散的视觉token,这些方法可以对文本到图像生成(如DALL-E和CogView)、文本到视频生成(如GODIVA)和视频预测(如LVT和VideoGPT)进行高效和大规模的预训练,生成的图像或视频的分辨率更高。然而,这些模型都没有由图像和视频一起训练。但直觉告诉我们,这些任务可以从两种类型的视觉数据中受益。
与这些工作相比,N̈UWA是一个统一的自回归视觉合成模型,涵盖图像和视频的视觉数据,可以支持下游各种任务。我们还在 4.3 节中验证了不同预训练任务的有效性。NUWA 在视觉token化方面使用的是 VQ-GAN [ Taming Transformers for High-Resolution lmage Synthesis ] ,而不是 VQ-VAE ,根据我们的实验,这可以带来更好的生成质量。
备注:AE、VAE、VQ-VAE和VQ-GAN的简要比较,参见博文。
51-33 LDM 潜在扩散模型论文精读 + DDPM 扩散模型代码实现_ldm论文复现-CSDN博客
2.2. Visual Sparse Self-Attention
如何处理自注意带来的二次复杂性是另一个挑战,特别是对于高分辨率图像合成或视频合成等任务。
与 NLP 类似,已经探索了稀疏注意力机制来缓解这个问题以进行视觉合成。有些工作将视觉数据分成不同的部分(或块),然后对合成任务进行按块稀疏注意。
- Latent Video Transformer
- Scaling Autoregressive Video Models
然而,这些方法分别处理不同的块,并没有对其关系进行建模。有些工作提出在视觉合成任务中使用轴向稀疏注意,该任务沿着视觉数据表示轴进行稀疏注意。这种机制使训练非常高效,对DALL-E、CogView和GODIVA等大规模预训练模型友好。
- Axial Attention in Multidimensional Transformers
- Zero-Shot Text-to-lmage Generation
- GODIVA: Generating Open-Domaln Videos from nAtural Descriptions
然而,由于自注意中使用的上下文有限,生成的视觉内容质量可能会受到伤害。有些工作提出在视觉合成任务中使用局部稀疏注意力,这允许模型看到更多的上下文。但是这些作品仅适用于图像。
- Generating Long Sequences with Sparse Transformers
- Image transformer
- Stand-Alone Self-Attention in Vision Models
与这些工作相比,N̈UWA提出了一种3D Nearby Attention邻域自注意机制,将局部稀疏注意扩展到图像和视频。我们还在第4.3节中验证了局部稀疏注意,对于视觉生成优于轴向稀疏注意。
3. Method
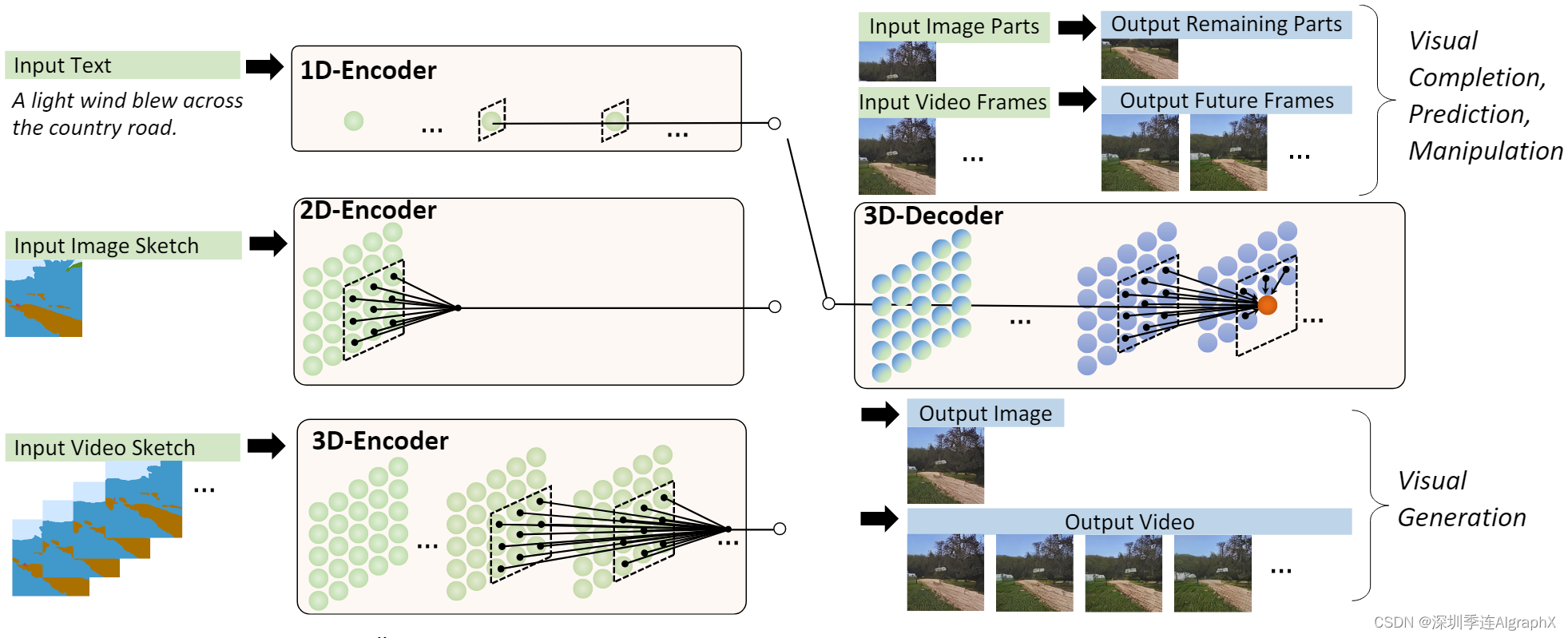
图 2,N̈UWA整体架构。它包含一个支持多种条件的 adaptive 编码器和一个预训练的解码器,能够同时使图像和视频的信息。对于图像补全、视频预测、图像处理和视频操作任务,将输入的部分图像或视频直接送入解码器即可。
编码解码器都是基于3DNA建立,该机制可以同时考虑空间和时间轴的上局部特性。
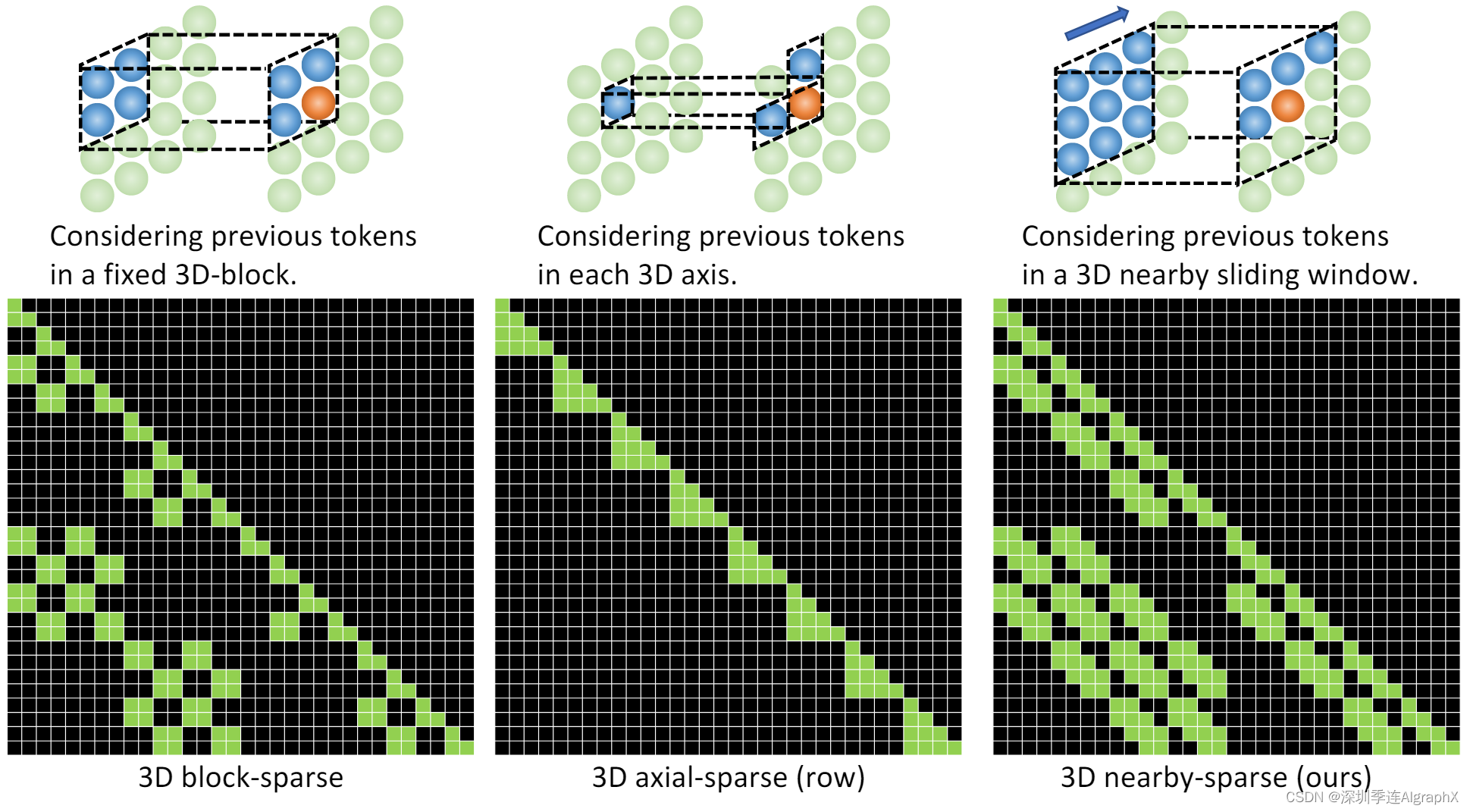
图 10,不同 3D 稀疏注意力之间的比较。所有样本都假设输入 3D 数据的大小为 4 × 4 × 2 = 32。上半部分的插图显示需要关注哪些tokens(蓝色)来生成目标tokens(橙色)。下半部分大小为 32 × 32 的矩阵显示了稀疏注意力中的注意掩码(黑色表示掩码tokens)。
3.1. 3D Data Representation
为了涵盖所有文本、图像和视频或它们的草图,我们将所有文本视为tokens,并定义一个统一的 3D 符号 X ∈ R h×w×s×d,其中 h 和 w 分别表示空间轴上的tokens数(高度和宽度),s 表示时间轴中的tokens数,d 是每个token的维度。接下来,我们将介绍如何获得不同模态的统一表示。
文本自然是离散的,使用 Transformer,我们使用小写字节对编码 (byte pair encoding,BPE) 将它们token化并嵌入到 R1×1×s×d 中。使用占位符 1,因为文本没有空间维度。
图像自然是连续的像素。输入高度为H、宽度W和通道C的原始图像 I∈R h×w ×c,VQ-VAE训练一个可学习的码本,在原始连续像素和离散token之间建立桥梁,如式(1) ~(2)所示:

其中 E 是一个编码器,它将 I 编码为 h × w 网格特征 E(I) ∈ R h×w×dB , B ∈ R N ×dB 是一个具有 N 个视觉token的可学习码本,搜索 E(I) 的每个网格以找到最近的token。搜索的结果 z ∈ {0, 1,..., N − 1} h×w 由 B 嵌入并由解码器 G 重构回 ^I。VQ-VAE 的训练损失可以写成方程式(3)。
![]()
其中 ||I − ^I|| 严格约束 I 和 ^I 之间精确像素匹配,这限制了模型的泛化能力。
最近,VQ-GAN 通过添加感知损失和 GAN 损失来增强 VQ-VAE 训练,以简化 I 和 ^I 之间的精确约束,并专注于高级语义匹配,如等式 (4)∼(5)所示:
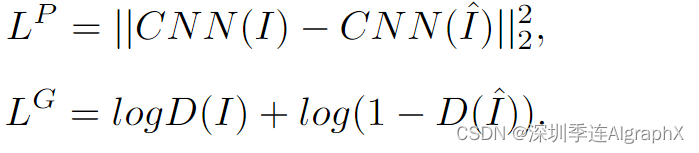
VQ-GAN训练后,使用 B[z]∈R h×w×1×d 作为图像的表示。我们使用占位符 1,因为图像没有时间维度。
视频可以被视为图像的时间扩展,最近的工作如VideoGPT和VideoGen将VQ-VAE编码器中的卷积从2D扩展到3D,并训练视频特定的表示。然而,这种方法无法为图像和视频共享一个通用的码本。
本文中,简单地使用 2D VQ-GAN 对视频的每一帧进行编码,也可以生成时间一致性的连贯视频,同时受益于图像和视频数据。生成的视频表示为 R h×w×s×d,其中 s 表示帧数。
对于图像草图,我们将它们视为具有特殊通道的图像。一个图像分割矩阵Rh×w,每个值表示像素类的值,可以以 one-hot 方式 R h×w×c 查看,其中 c 是分割类的数量。
通过训练一个用于图像草图的额外VQ-GAN,最终得到图像嵌入表示R h×w×1×d。类似地,对于视频速写,嵌入表示为 R h×w×s×d。
3.2. 3D Nearby Self-Attention

3.3. 3D Encoder-Decoder

3.4. Training Objective
我们在文本到图像 (T2I)、视频预测 (V2V) 和文本到视频 (T2V) 三个任务上训练模型。这三个任务的训练目标是交叉熵,分别表示为方程(16)中的三部分:
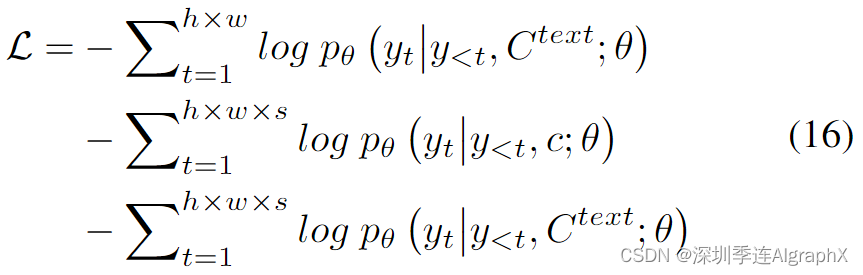
对于 T2I 和 T2V 任务, 表示文本条件。对于 V2V 任务,由于没有文本输入,我们改为一个特殊单词“None”的恒定 3D 表示 c。θ 表示模型参数。
4. Experiments
基于3.4节,我们首先在三个数据集上预训练 N̈UWA:
- Conceptual Captions,用于文本到图像 T2I 生成任务,包括 2.9M 文本图像对。
- Moments in Time Dataset,用于视频预测 V2V 任务,包括 727K 视频。
- VATEX 数据集,用于文本到视频 T2V 生成,包括 241K 文本-视频对。
4.1. Implementation Details
此部分略,请主要关注消融实验。
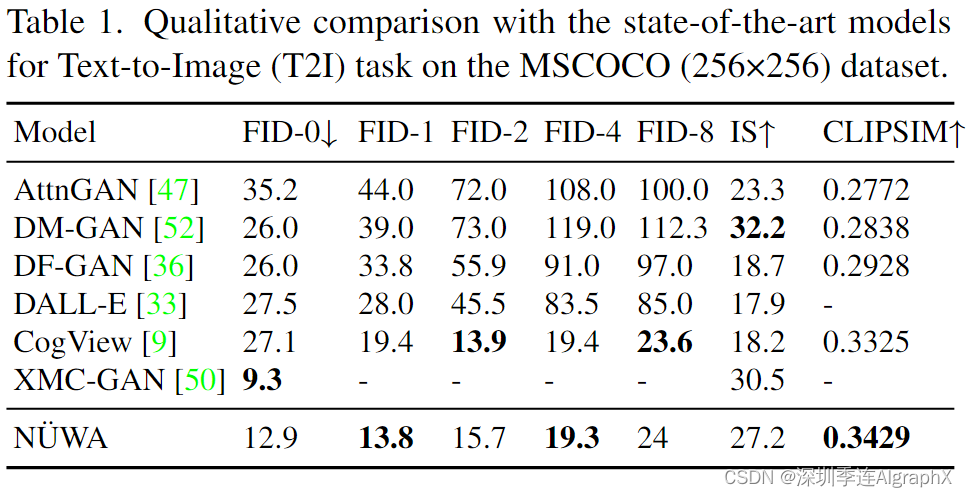
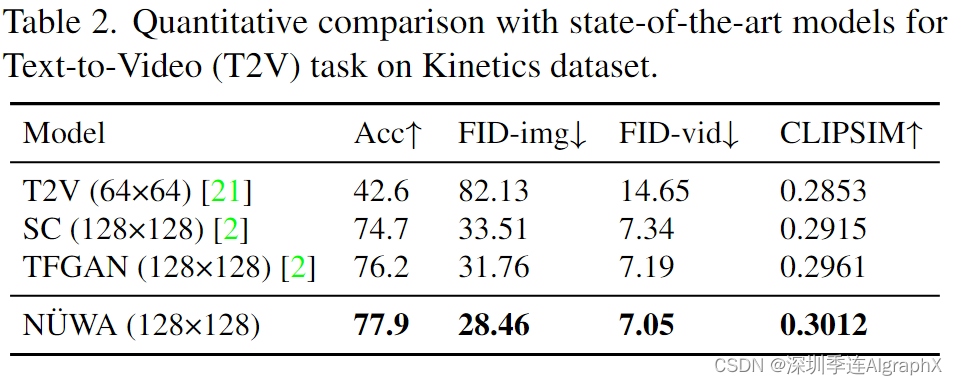
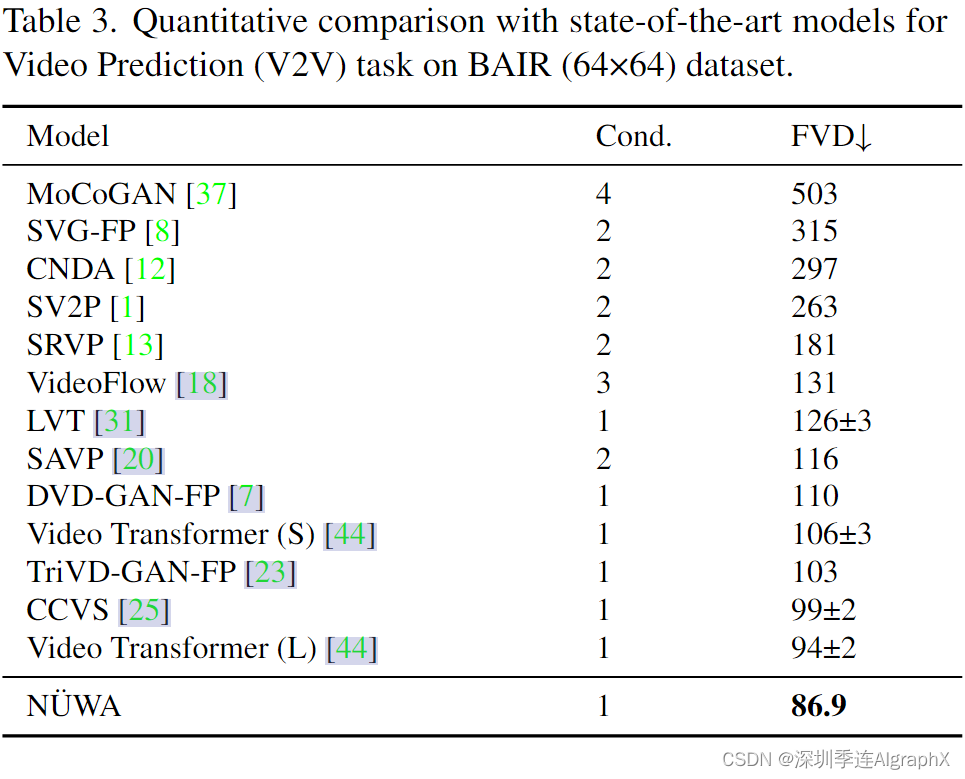
4.2. Comparison with state-of-the-art
八大任务包括文生图、文生视频、视频预测、草图到图、图像补全、文本引导的图像操作、草图到视频、文本引导的视频操作。
- Text-to-Image (T2I) fine-tuning
- Text-to-Video (T2V) fine-tuning
- Video Prediction (V2V) fine-tuning
- Sketch-to-Image (S2I) fine-tuning
- Image Completion (I2I) zero-shot evaluation

- Text-Guided Image Manipulation (TI2I) zero-shot evaluation

- Sketch-to-Video (S2V) fine-tuning
- Text-Guided Video Manipulation (TV2V) zero-shot evaluation
据我们所知,开放域 S2V 和 TV2V 是本文首次提出的任务。由于没有比较,我们改为在 4.3 节中的消融研究中排列它们。
4.3. Ablation Study
表 4 上半部分显示了不同 VQ-VAE (VQ-GAN) 设置的有效性。
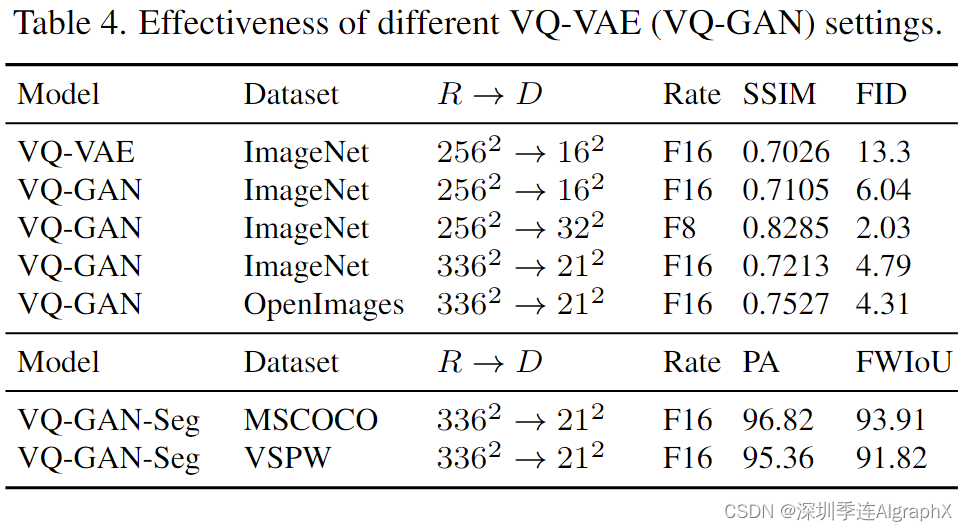
我们在ImageNet和OpenImages上进行了实验。R 表示原始分辨率,D 表示离散token的数量。VQ-GAN显示出比VQ-VAE更好的Fŕechet初始距离(FID)和结构相似性矩阵(SSIM)分数。
因此,重要的是我们不仅压缩原始图像了多少,还有多少离散token用于表示图像。这与认知逻辑一致,仅用一个token来表示人脸太模糊了。实际上,我们发现 16^2 个离散token通常会导致性能不佳,尤其是对于人脸,32^2 个标记表现出最佳性能。然而,更多的离散token意味着更多的计算,特别是对于视频。最后,我们使用权衡版本进行我们的预训练:21^2 个token。
通过对Open Images数据集进行训练,我们进一步将21^2版本的FID评分从4.79提高到4.31。
Tab 4 的下半部分显示了 VQGAN 对草图的性能。在MSCOCO上,VQ-GAN-Seg针对Sketch-to-Image (S2I)任务进行训练。在VSPW上,VQ-GAN-Seg针对Sketch-to-Video (S2V)任务进行训练。上述所有主干网络在像素精度 (PA) 和频率加权交集联合 (FWIoU) 方面表现出良好的性能,这显示了模型使用 3D 草图表示的良好质量。图 8 还显示了 336×336 图像和草图的一些重建样本。
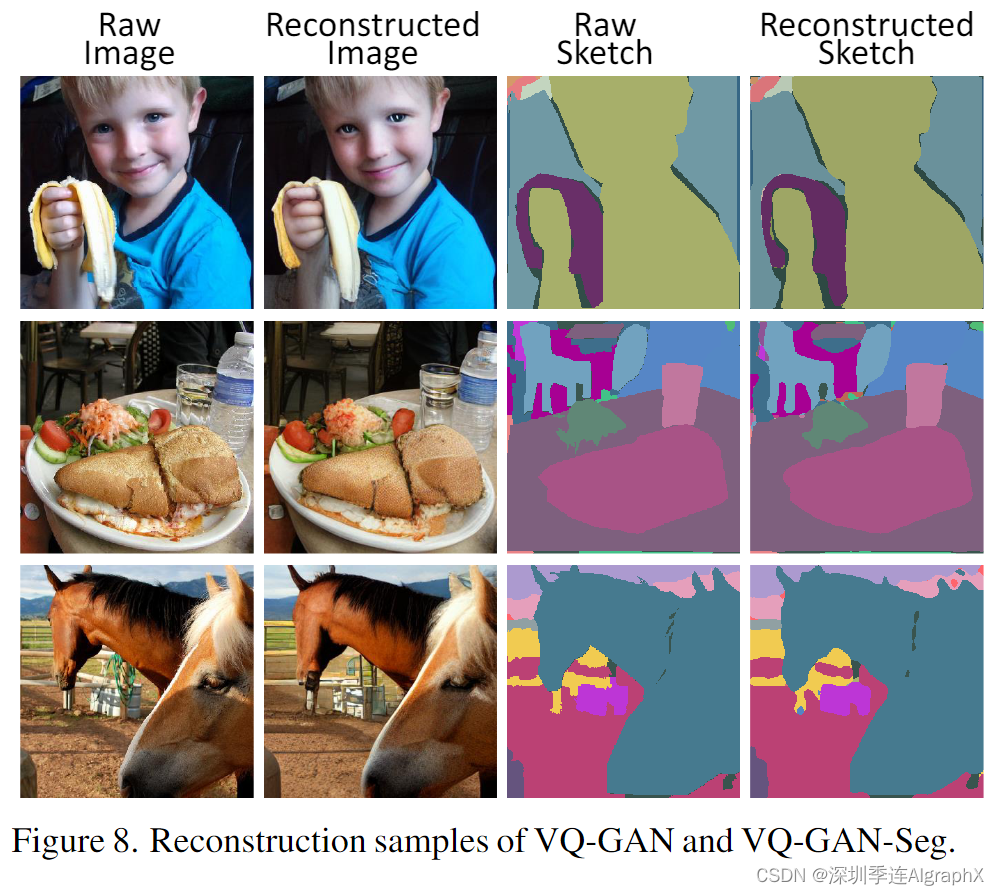
表 5 显示了多任务预训练对文本到视频 (T2V) 生成任务的有效性。我们研究了一个具有挑战性的数据集MSR-VTT,具有自然描述和真实世界的视频。与仅在单个 T2V 任务(第 1 行)上进行训练相比,T2V 和 T2I(第 2 行)的训练将 CLIPSIM 从 0.2314 提高到 0.2379。这是因为 T2I 有助于在文本和图像之间建立连接,从而有助于 T2V 任务的语义一致性。相比之下,T2V 和 V2V(第 3 行)的训练将 FVD 分数从 52.98 提高到 51.81。这是因为 V2V 有助于学习一个通用的无条件视频模式,因此有助于 T2V 任务的视觉质量。作为 N̈UWA 的默认设置,在所有三个任务上的训练都取得了最好的性能。
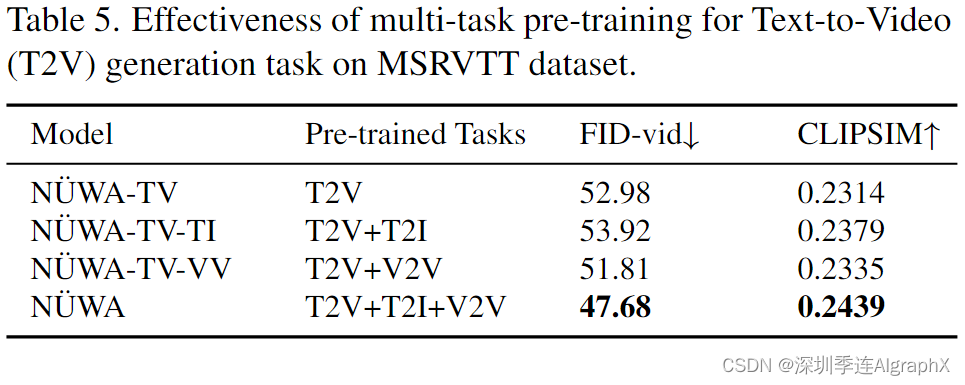
表 7 显示了 VSPW 据集上 Sketch-to-Video (S2V) 任务的 3D 邻域注意力的有效性。我们研究了 S2V 任务,因为该任务的编码器和解码器都带有 3D 视频数据。为了评估 S2V 的语义一致性,我们提出了一种新的度量,称为 Detected PA,它使用语义分割模型来分割生成视频的每一帧,然后计算生成的片段和输入视频草图之间的像素精度。最后一行的默认 N̈UWA 设置中,具有邻域编码器和邻域解码器,实现了最佳的 FID-vid 和 Detected PA。如果编码器或解码器之一被完全自注意full attention 替换,性能会下降,这表明attention邻域条件和邻域生成结果比简单地考虑所有信息要好。我们在两个方面比较了邻域稀疏和轴向稀疏注意。
- 首先,附近稀疏的计算复杂度为O ((hws) (
)),轴稀疏注意为O ((hws) (h + w + s))。为了生成长视频(更长的 s),邻域稀疏在计算上更有效。
- 其次,在视觉识别任务中,邻域稀疏比轴向稀疏具有更好的性能,这是因为邻域稀疏关注包含空间和时间轴之间相互作用的“邻域”位置,而轴向稀疏分别处理不同的轴,只考虑同一轴上的交互。
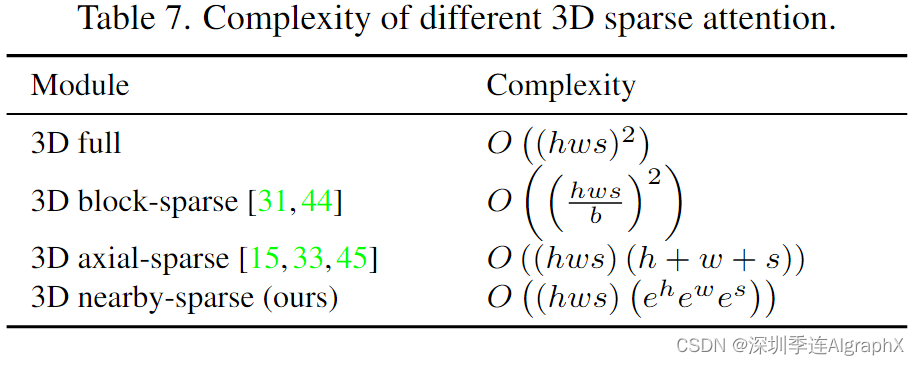
图 9 显示了本文提出的一项新任务,我们称之为“文本引导视频操作 (TV2V)”。TV2V 旨在改变视频的未来,从文本引导的选定帧开始。所有样本都开始从第二帧改变视频的未来。第一行显示了原始视频帧,其中潜水员在潜水。在将“潜水员游泳到表面”输入 N̈UWA 的编码器并提供第一个视频帧后,N̈UWA 成功地提供了潜水员游泳到第二行表面的视频。第三行显示了另一个成功的样本,让潜水员游泳到底部。如果我们希望潜水员飞到天空。第四行显示 N̈UWA 也可以使其向上飞行,就像火箭一样。


5. Conclusion
在本文中,我们提出了N̈UWA作为一个统一的预训练模型,可以生成新的或操纵现有的图像和视频,用于8个视觉合成任务。本文一些贡献包括: (1) 一个通用的 3D 编码器解码器框架,同时覆盖文本、图像和视频; (2) 考虑了空间和时间轴邻近域特征的稀疏注意机制; (3) 对 8 个合成任务的综合实验。这是我们构建 AI 平台的第一步,旨在实现视觉世界的创造,并帮助内容创作者。
N̈UWA系列信息:
-
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion. (ECCV 2022)
-
NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis. (NeurIPS 2022)
-
NUWA-LIP: Language Guided Image Inpainting with Defect-free VQGAN. (CVPR 2023)
-
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation. (ACL 2023)
-
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory https://arxiv.org/pdf/2308.08089.pdf.
这篇关于51-42 NÜWA:女娲,统一的多模态预训练模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








