本文主要是介绍解锁多智能体路径规划新境界:结合启发式搜索提升ML本地策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言:多智能体路径寻找(MAPF)问题的重要性与挑战
在现代自动化和机器人技术迅速发展的背景下,多智能体路径寻找(Multi-agent path finding,简称MAPF)问题的研究变得日益重要。MAPF问题涉及为一组智能体(如机器人或软件代理)寻找无碰撞的路径,以便它们能够安全、高效地到达目标位置。这一问题在许多实际应用中都有广泛的应用,例如快速搜索与救援、火星探索、高效的仓库管理等。在这些场景中,可能需要数百个机器人移动物品或执行任务,而每个机器人都可能是廉价且相对简单的,但整个系统需要具备可扩展性,并能够实现复杂的目标。
然而,MAPF问题也带来了一系列挑战。在多智能体系统中,如何精确地控制每个智能体的移动至关重要。如果没有仔细考虑,智能体之间可能会发生冲突,导致死锁,即多个智能体互相阻碍,无法向目标前进。传统的MAPF解决方案通常采用启发式搜索方法,这些方法能够为数百个智能体找到解决方案,但它们通常是集中式的,并且在短时间内难以扩展。此外,机器学习(ML)方法通过为每个智能体学习策略,提供了一种吸引人的替代方案,因为这些方法可以支持去中心化系统,同时在保持良好解决方案质量的同时具有良好的可扩展性。但是,现有的ML方法在长期规划和低错误情况下通常表现不佳,这在MAPF中至关重要,因为它要求跨越许多智能体进行长期规划,并且几乎没有容错空间,这可能会导致碰撞或死锁。
因此,研究如何提高ML方法在MAPF问题中的性能,尤其是在高拥挤场景下的性能,成为了一个重要的研究方向。本文的主要贡献在于展示了如何通过将启发式搜索与学习到的策略相结合,显著提高了策略的成功率和可扩展性。我们的实验表明,这是ML方法首次在高拥挤场景(例如20%的智能体密度)中扩展到与传统启发式搜索方法相似的规模。
论文概览:标题、作者、机构、论文链接
标题: Improving Learnt Local MAPF Policies with Heuristic Search
作者: Rishi Veerapaneni*, Qian Wang*, Kevin Ren*, Arthur Jakobsson*, Jiaoyang Li, Maxim Likhachev
机构: Carnegie Mellon University, University of Southern California
论文链接:2403.20300.pdf (arxiv.org)
MAPF问题的定义与现状
1. MAPF问题的基本概念
多智能体路径规划(Multi-agent path finding, MAPF)问题涉及为一组智能体寻找无碰撞路径,以便它们能够安全、有效地到达目标位置。在经典的二维单次射击(single-shot)MAPF中,我们得到一个已知的网格世界,其中包含自由空间和障碍物,以及每个智能体的起始位置和目标位置。每个智能体可以在四个基本方向上移动或等待,共有五种不同的动作。我们的目标是为所有智能体找到一组无碰撞路径,使它们能够在不与障碍物、其他智能体的顶点(同一位置)或边缘(连续时间步中的位置交换)发生碰撞的情况下到达目标,并希望找到高效的路径,以最小化总流程时间(即所有智能体到达目标位置的路径长度之和)。
2. 传统启发式搜索方法的局限性
启发式搜索方法旨在通过智能地利用智能体的半独立性来解决搜索空间指数级增长的问题。例如,基于冲突的搜索(Conflict-Based Search)是一种流行的、完备且最优的MAPF解决框架,它为每个智能体单独规划,然后通过施加约束和重新规划来迭代解决冲突。这些方法通常具有良好的解决方案质量,但随着智能体数量的增加,计算规模会急剧增长。此外,这些方法通常需要一个集中式规划器,这在分布式系统中可能不太实用。
机器学习方法的兴起与挑战
1. 机器学习在MAPF中的应用初探
机器学习(ML)方法通过为每个智能体学习策略,能够实现去中心化系统,同时在保持良好解决方案质量的同时具有良好的可扩展性。当前的ML方法开始探索这种潜力,它们学习“局部”策略,这些策略仅考虑单个时间步的局部观察,并输出一步动作分布。然而,ML方法通常在长期规划和低错误情况下存在挑战,这两者在MAPF中至关重要,因为它要求跨多个智能体进行长期规划,并且几乎没有错误的余地,否则可能会导致碰撞或死锁。因此,现有的ML方法在实际应用中成功率和可扩展性较差。
2. 学习局部策略的问题:短视与死锁
大多数ML方法突出了智能体之间死锁的问题。例如,PRIMAL的结果显示,当智能体在目标位置停留时,死锁很常见。PRIMAL2专门旨在学习减少迷宫结构中死锁的约定。SCRIMP使用它们学习的状态值(除了局部策略之外的模型的另一个输出)来计算智能体的优先级,用于优先处理死锁中的智能体,并显示这比简单的碰撞防护提高了性能。我们的洞察是,我们可以使用启发式搜索方法,结合学习到的策略预测来解决局部死锁。
理论上,这些技术应该能够很好地扩展到越来越多的智能体,因为神经网络的推理时间应该大致保持不变,无论智能体的数量如何。然而,现有的ML方法执行一步策略,由于缺乏全局规划并且没有理论上的完备性保证,因此在智能体拥挤的场景中容易陷入死锁/活锁,从而在实践中导致成功率和可扩展性较差。
提出的解决方案:结合启发式搜索的机器学习方法
在多智能体路径规划(MAPF)问题中,我们面临的挑战是为一组智能体找到无碰撞的路径,以便它们能够安全、高效地到达目标位置。传统的启发式搜索方法虽然在解决问题上具有优势,但在计算时间和中心化规划方面存在局限性。而机器学习(ML)方法,尤其是学习每个智能体的策略,因其能够实现去中心化系统并具有良好的扩展性而备受关注。然而,现有的ML方法在长期规划和低错误情况下通常表现不佳,这在MAPF中是至关重要的。因此,我们提出了一种新的解决方案,即将启发式搜索与学习策略相结合,以提高成功率和可扩展性。
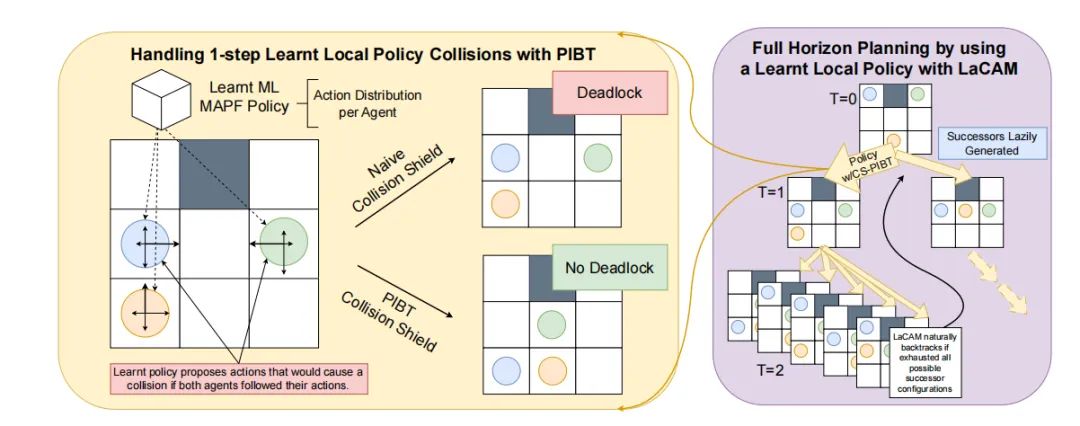
1. 利用PIBT作为智能碰撞防护
PIBT(Priority Inheritance with Backtracking)是一种贪婪的启发式搜索方法,通过优先级和回溯机制来避免碰撞。我们提出使用PIBT作为智能碰撞防护,它不仅处理单步决策中的碰撞,还考虑了智能体的整个行动概率分布,从而有效地解决了由于碰撞导致的死锁问题。
2. 通过LaCAM实现全视野规划
LaCAM(Lazy Constraints Addition search for MAPF)是一种基于PIBT的搜索方法,它在联合配置空间中进行深度优先搜索(DFS),通过懒惰添加约束的方式生成后继状态。我们观察到,将学习到的MAPF策略与LaCAM结合,可以作为有效的配置生成器。这种方法在保持理论上的完整性的同时,通过全视野规划显著提高了成功率。
3. 结合启发式搜索与学习策略的多种方式
我们还探索了将启发式搜索与学习策略相结合的其他变体,例如通过权衡启发式搜索和学习策略的偏好来优化智能体的行动选择。这种方法可以在保持碰撞自由的同时,提供更优化的路径选择。
实验验证与分析
1. 实验设置与评估指标
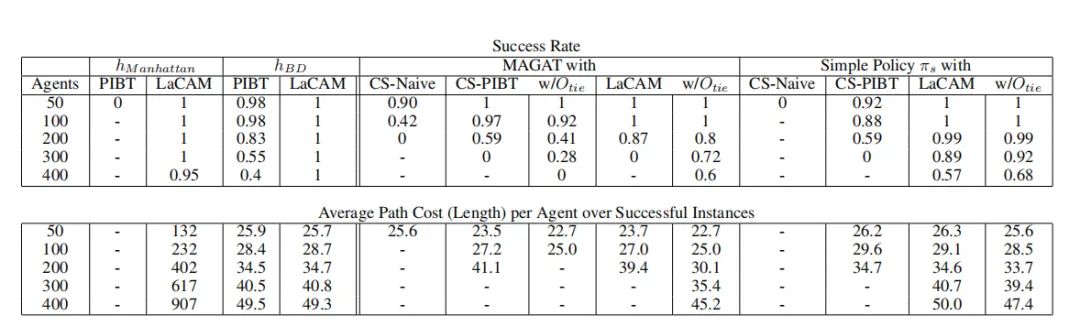
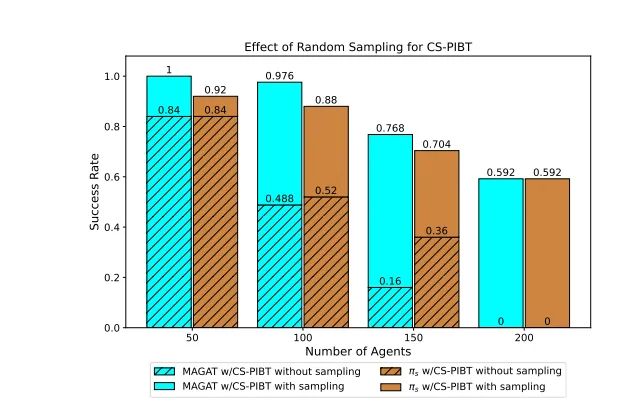
我们的实验设置包括标准的随机32x32x10地图,评估指标为成功率和平均路径成本。我们比较了使用不同碰撞防护方法(CS-Naive和CS-PIBT)的MAGAT模型,以及将学习策略与LaCAM结合使用的效果。
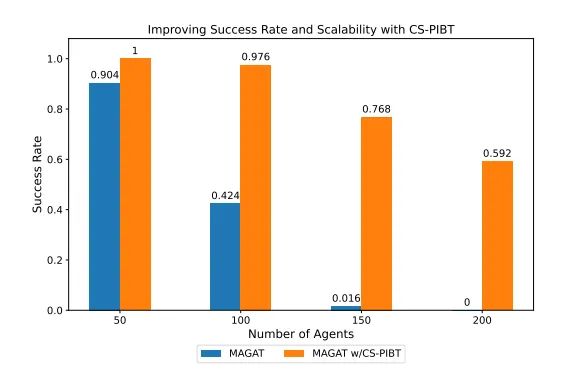
2. 成功率与可扩展性的提升
实验结果表明,使用CS-PIBT和LaCAM可以显著提高成功率和可扩展性。例如,使用CS-PIBT的MAGAT模型在200个智能体的情况下仍能保持较高的成功率,而简单的学习策略在结合LaCAM后,能够处理高达300个智能体的情况。
3. 路径成本与解决方案质量的分析
我们还分析了路径成本与解决方案质量。使用Otie方法结合启发式搜索和学习策略的MAGAT模型在路径成本上比单独使用启发式搜索或学习策略的方法有所改善。这表明,通过合理地结合启发式搜索和学习策略,我们可以在保证成功率的同时,进一步优化路径成本。
讨论:学习策略与启发式搜索的结合优势
1. 在高拥挤场景下的表现
在高拥挤的多智能体路径寻找(MAPF)场景中,传统的启发式搜索方法在处理大量智能体时面临着可扩展性的挑战。然而,机器学习(ML)方法通过为每个智能体学习策略,提供了一种可行的去中心化解决方案,理论上能够在保持良好解决方案质量的同时实现良好的扩展性。然而,现有的ML方法在长期规划和低错误情况下通常表现不佳,这在MAPF中是至关重要的,因为它要求跨多个智能体进行长期规划,并且几乎没有错误的余地,否则可能会导致碰撞或僵局。
本研究的主要思想是通过将学习到的ML局部策略与启发式搜索方法结合使用,可以改善ML局部策略。当学习到的策略预测的行动导致智能体发生碰撞时,现有的ML方法通常使用一种简单的“碰撞盾牌”来代替碰撞,但这通常会导致僵局。相比之下,我们展示了如何使用PIBT(优先级继承与回溯)作为智能碰撞盾牌在执行过程中使用。我们证明了这种方法可以提升性能,而不仅仅是单独使用学习到的策略。此外,我们还展示了如何将学习到的MAPF策略与LaCAM(懒惰约束添加搜索)更紧密地结合以进一步提高性能。我们探索了将学习到的策略与PIBT和LaCAM结合的其他变体,并显示出相对于单独的学习策略,在成功率和成本方面有显著的改进。
2. 对未来机器学习方法在MAPF中应用的启示
本研究的实验结果表明,结合学习策略和启发式搜索可以显著提高成功率和可扩展性,这为未来的ML方法在MAPF中的应用提供了启示。特别是在高拥挤场景中,这种结合方法已经证明可以处理高达20%的智能体密度。这表明,通过整合启发式搜索,ML方法可以在MAPF中实现与传统启发式搜索方法相似的智能体密度,这为未来的研究方向提供了新的可能性。
总结与未来展望
1. 本文贡献的总结
本文的主要贡献在于提出了几种模型无关的方法,通过启发式搜索改进了学习到的局部MAPF策略。首先,我们引入了使用PIBT作为碰撞盾牌的CS-PIBT,它接受策略的1步概率分布并输出有效的无碰撞步骤。我们证明了这种方法可以显著提高拥挤场景中的可扩展性和成功率,而无需更改模型。然后,我们展示了如何使用LaCAM框架与学习模型结合,以实现具有理论完整性的全视野规划,并在实践中进一步提高成功率和可扩展性。我们还首次展示了学习到的MAPF策略(结合搜索)可以扩展到与传统启发式搜索方法相似的智能体密度(20%以上)。
2. 对未来研究方向的展望
未来的研究可以在多个方向上进行扩展。首先,可以探索如何进一步整合ML方法和启发式搜索,以提高在更复杂环境中的性能,例如部分可观测的MAPF或频繁变化目标的极端终身MAPF。其次,研究可以扩展到更高维度的状态空间问题,这对于更现实的机器人模型至关重要。例如,现实中的仓库智能体可以沿非单位速度的角度移动,这就需要至少解决4维问题(x,y,θ,速度)。在这些情况下,计算完美的启发式或其他启发式可能是不可能的,而学习到的MAPF策略,结合CS-PIBT或LaCAM,将在这些情况下显示出前景。最后,未来的研究可以探索如何利用这些方法来帮助ML从业者学习更简单的模型,而不是现有的更大的模型,这可能带来潜在的计算优势。
这篇关于解锁多智能体路径规划新境界:结合启发式搜索提升ML本地策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



