本文主要是介绍Mamba:使用选择性状态空间的线性时间序列建模,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文主要是关于mamba论文的详解~
论文:Mamba: Linear-Time Sequence Modeling with Selective State Spaces
论文地址:https://arxiv.org/ftp/arxiv/papers/2312/2312.00752.pdf
代码:state-spaces/mamba (github.com)
Demo:state-spaces (State Space Models) (huggingface.co)
概述
Mamba 是一种新的状态空间模型架构,适用于信息密集型数据,例如语言建模。它基于结构化的状态空间模型,具有高效的硬件感知设计和实现。
Mamba是对长数据序列进行建模的新型神经网络.这些是新的选择性状态空间模型(SSM),旨在克服传统序列模型(尤其是Transformers)的局限性。该模型是循环神经网络 (RNN) 和卷积神经网络 (CNN) 的组合,灵感来自经典状态空间模型。
Mamba模型介绍
Mamba 根据输入专注于或忽略特定信息。它根据输入参数化选择性状态空间模型 (SSM) 权重,允许模型过滤掉不相关的信息并无限期地保留相关数据。
Mamba 还使用硬件感知算法以递归方式而不是卷积来计算模型。这种方法比传统方法更快、更高效,因为它不会实现拉伸状态,并避免了 GPU 内存层之间的 I/O 访问。
能够处理长序列
传统的转换器模型存在计算复杂度随着序列长度的增加而以平方形式增加的问题。在处理长序列时,这是低效且资源密集型的。Mamba 解决了这个问题,在序列的长度上线性缩放。因此,曼巴蛇可以有效地处理长序列,并具有重要的应用潜力,特别是在语言、音频和基因组学等领域。
计算效率和速度
与 Transformer 相比,Mamba 具有更快的推理速率和更低的内存要求。这意味着 Mamba 在实际应用中效率更高,并节省了训练和推理大规模模型所需的计算资源。
选择性状态空间
Mamba 根据输入对 SSM 参数进行参数化。这允许模型过滤掉不相关的信息,并无限期地保留它需要的信息。这种选择机制允许曼巴只关注相关数据,从而提高数据处理效率。
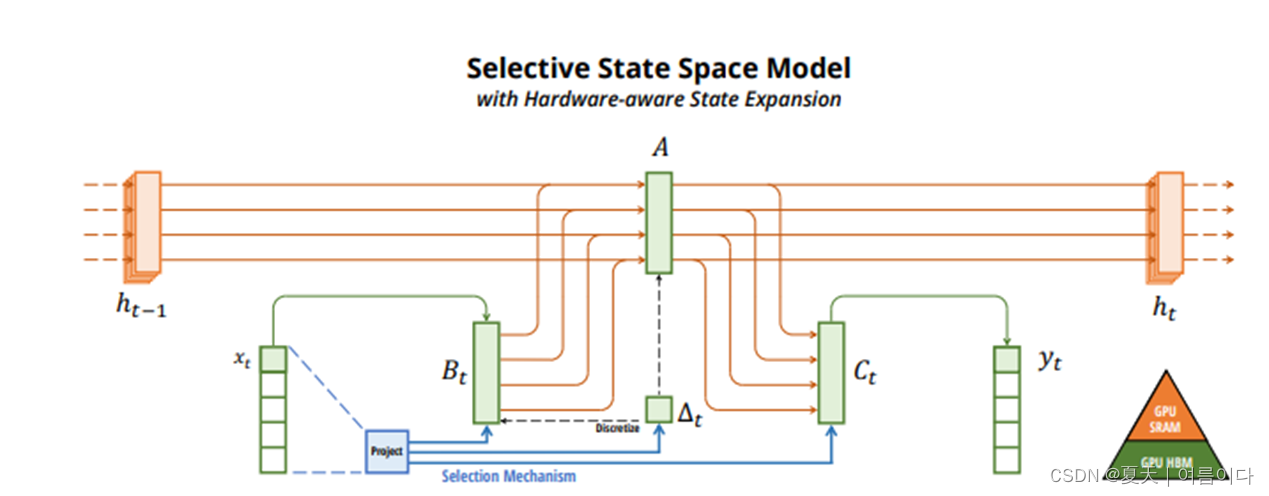
硬件感知算法
Mamba 使用一种硬件感知算法,该算法以递归方式而不是卷积进行计算。这会阻止 GPU 内存层之间的 IO 访问,并且不会实现扩展状态。因此,无论是在理论上(与序列长度线性缩放)还是在现代硬件上(例如,在 A100 GPU 上速度提高 3 倍),这种实现都比以前的方法更快。
简化架构
Mamba 将之前的 SSM 架构与 Transformer 的 MLP 模块组合成一个模块,提供更简单、更高效的架构。这使得 Mamba 更易于实现和扩展,适用于广泛的应用。
SSM的基本概念
SSM 是一种模型,旨在对序列数据(例如,随时间变化的数据)进行建模。这些模型结合了传统递归神经网络 (RNN) 和卷积神经网络 (CNN) 的特征,并受到经典状态空间模型的启发。
SSM能够处理长序列,并可应用于各种类型的序列数据。这些功能可以与各种架构相结合,以应用于新形式的序列建模任务。
Mamba的构架
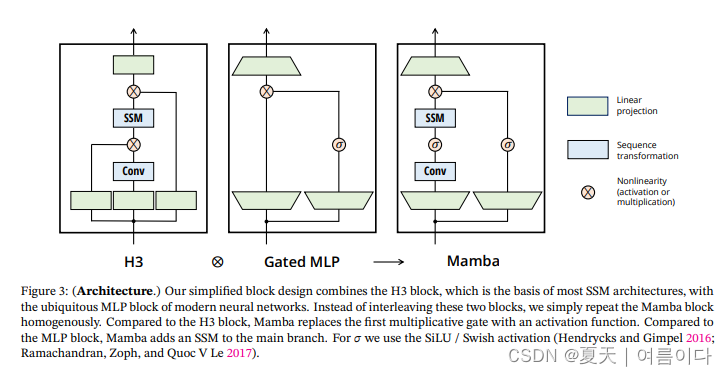
正在更新。。。
参考文献
[1]Mamba Explained (thegradient.pub)
[2]Mamba: The Easy Way (jackcook.com)
[3]Mamba architecture : A Leap Forward in Sequence Modeling | by Puneet Hegde | Medium
[4]Mamba Simplified - Part 2 - S4 and Mamba (premai.io)
这篇关于Mamba:使用选择性状态空间的线性时间序列建模的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




