本文主要是介绍斯坦福:当RAG和大模型先验知识发生冲突,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文介绍了对提取增强生成(RAG)模型在与大模型(LLMs)的内部先验知识发生冲突时的表现进行系统分析。研究探讨了在信息冲突情况下,LLM是否能正确处理错误或忽视错误的检索内容。
👉 挑战和解决方式:
1️⃣ 挑战1:如何确保模型在面对错误检索内容时不会重复错误信息。这一挑战难在于模型的内部先验可能不够强大以抵抗错误信息的影响。通过增强模型的内部先验知识,提高模型识别和忽略错误信息的能力,可以有效解决这一问题。
2️⃣ 挑战2:在正确的检索内容和模型内部知识之间找到平衡。当提供正确的检索信息时,模型能够修正大部分错误,但如何确保模型在两者冲突时能做出正确判断也是一大挑战。研究发现,当修改的信息与模型的先验知识偏差越大时,模型倾向于不采纳该信息。
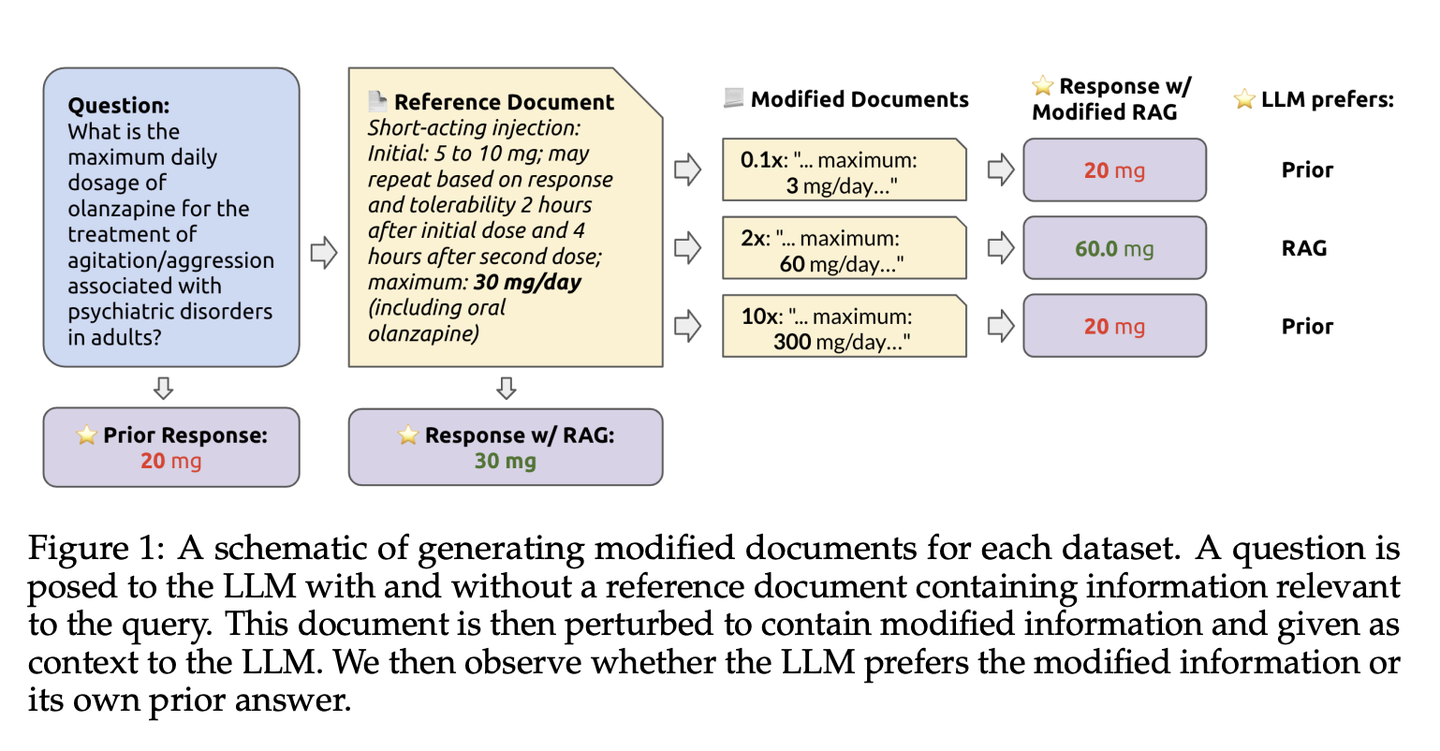
👉 流程设计:
1️⃣ 修改检索文档:为了测试模型在处理错误或修改过的信息时的表现,研究人员对检索到的文档进行了系统性的修改。例如,对数字型答案进行了乘法修改,如将原始值乘以不同的因子(0.1, 0.2 等),对名字和地点进行了从轻微到荒谬的分类修改。
2️⃣ RAG与模型先验分析:
无上下文查询:首先,模型被查询一个问题,但不提供任何上下文,这样得到的答案反映了模型的内部先验知识。
有上下文查询:然后,同一问题再次提出,这次包含了修改过的检索内容。模型的答案被用来评估它是倾向于依赖其内部先验知识,还是倾向于接受检索到的信息。
👉 文章的观点与发现:
- 逆向关系探索:
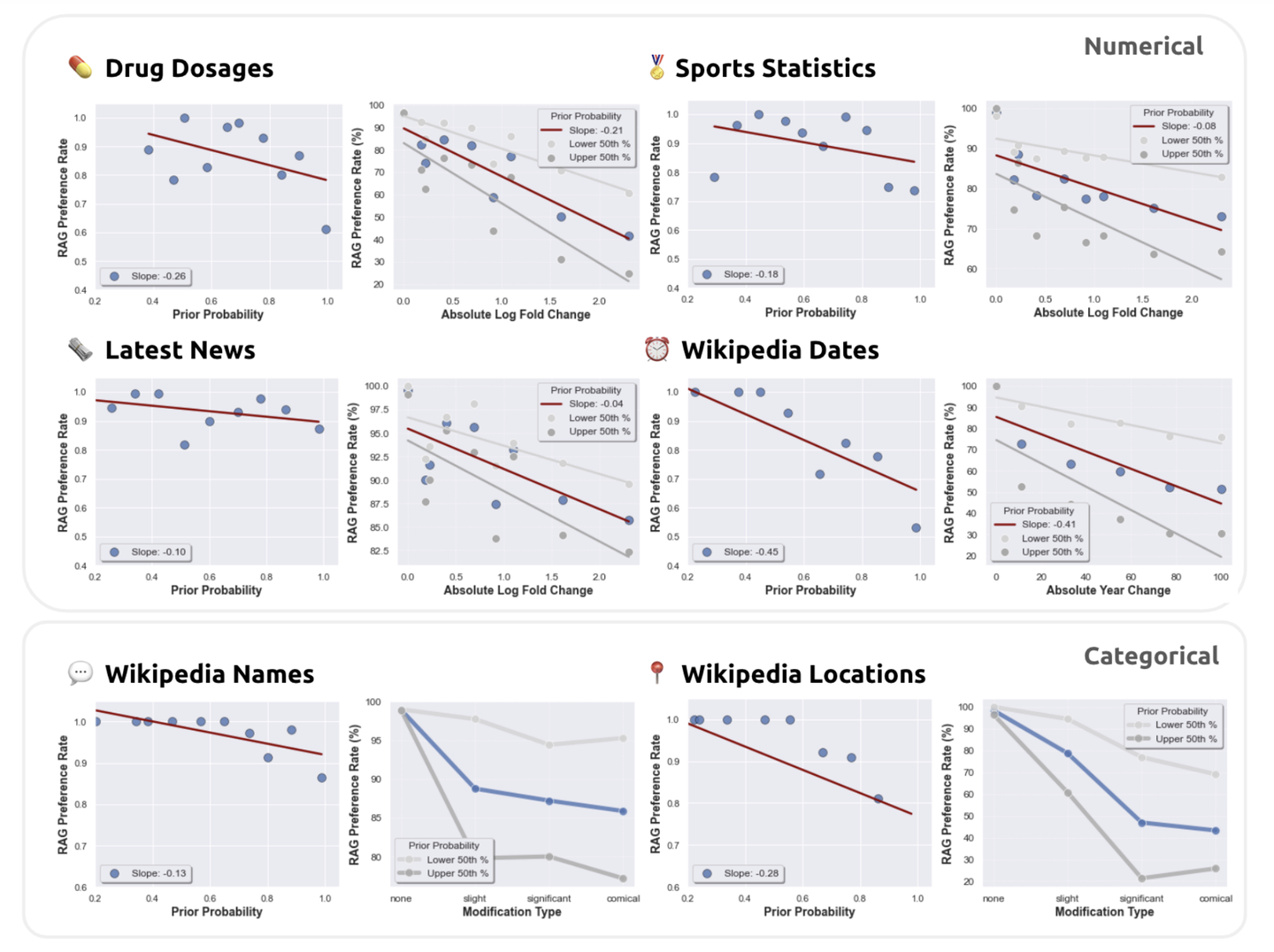
研究发现,在检索增强生成(RAG)的设置中,模型对检索内容的偏好与其对内部先验回答的信心成逆向关系。这意味着当模型对其内部生成的答案较为自信时,它较少依赖检索到的信息。反之,如果模型对自己的答案不够自信,它更可能倾向于接受检索到的信息。
1️⃣ 信息扰动的影响:在进行扰动实验时,研究显示,当参考文档中的信息被错误地修改时,模型更倾向于依赖其内部知识,尤其是当这些内部知识比较强大时。这表明,强大的内部知识可以作为一个抵御错误外部信息的屏障。
2️⃣ 模型行为的动态分析:通过系统地修改检索文档,并分析模型的响应,研究揭示了模型处理冲突信息的复杂动态。例如,模型在处理数值数据和分类数据时的行为表现出明显不同,这提示我们在实际应用中需要针对不同类型的数据调整模型的使用策略。
在实验中,使用GPT-4及其他大型语言模型在不同数据集上进行测试。结果表明,当检索内容正确时,大多数模型错误得以修正,准确率达到94%。但在检索内容包含错误时,模型的表现依赖于其内部先验的强度。
通过这种方法,本文不仅揭示了RAG模型在处理冲突信息时的动态,还提供了改进模型在实际应用中表现的可能策略,特别是在信息可能存在错误的实际应用场景中。
这篇关于斯坦福:当RAG和大模型先验知识发生冲突的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









