本文主要是介绍7D性能项目日记5:性能分析是查找瓶颈证据链的过程,而不是罗列数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、前言
- 二、性能分析工程师要有产出
- 三、性能瓶颈要有明确的证据链
- 四、看到现象就蒙原因
一、前言
在性能项目中,性能分析部分是最为复杂,也是最能体现价值的地方。
二、性能分析工程师要有产出
在我们这个项目中,我设置了专门做性能分析的人。
专职性能分析,就是在性能场景执行起来之后,在场景运行的过程中分析出性能瓶颈点在哪里。
有人说,这样的要求是不是太高了,一个系统涉及到那么多的技术栈,一个人如果不能覆盖所有,怎么分析出来瓶颈呢。在我看来,如果分析不了全部,那至少可以分析部分,如果任一部分都给不出明确的结论,那就不具备分析能力。
但是,性能分析工程师不能没有性能分析的产出,也就是我在项目中定义的一个产出物“性能分析调优报告”。
我是要求每个性能分析工程师只要有场景执行就要有分析过程的产出的。即使没有最终的瓶颈分析出来,那也要把分析的过程记录下来,因为我要看这个分析的逻辑是不是对的。
如果逻辑是对的,但是由于技能不足导致了没有结果,那这时候我可以支持你继续分析下去。在关键点上,没有思路了,告诉我,我来告诉你怎么往下走。
如果瓶颈结论没有分析出来,分析的过程也没记录,那谁知道你的价值是什么呢?
三、性能瓶颈要有明确的证据链
在项目中,我一直强调一句话:所有性能场景都有瓶颈。而性能分析工程师要做的是把这些瓶颈找到,并且把证据链列出来。
这里的证据链是什么呢?
不是“CPU使用率高”、“DISK中bi/bo过多”、“CS很高”这样模糊的描述,高是多少?要给出具体的值。
那你说,我改成这样的描述是不是就可以?“CPU总体使用率达到100%”、“DISK bi/bo每秒超过2万”、“CS每秒超过10万次”,这总有数值了吧。但是这样的描述可不可以做为结论来描述呢?
当然是不行的,因为这样的数值也只是瓶颈分析过程中的起点,它也只是瓶颈的现象,离瓶颈点还远。
也就是我们还要回答下一个问题:这个值是不是瓶颈?要想回答这个问题,就没那么简单了。
比如说:DISK bi/bo每秒超过2万,这个值合理还是不合理呢?我们首先要做出的是判断,对于性能来说,就两个关键字:快、慢。
我们在场景执行过程中首先看的是场景数据,场景中有响应时间的趋势图,如果响应时间的趋势仅和DISK IO的趋势相关,而通过响应时间的拆分判断发现,只要DISK IO高,响应时间就必然会高,同时在其他所有的计数器上都没有发现问题,这样可以判定为DISK IO影响了响应时间,这时候就是不合理的,就是瓶颈点;如果没有这样的关系,那就不是瓶颈点。
举个具体的例子:
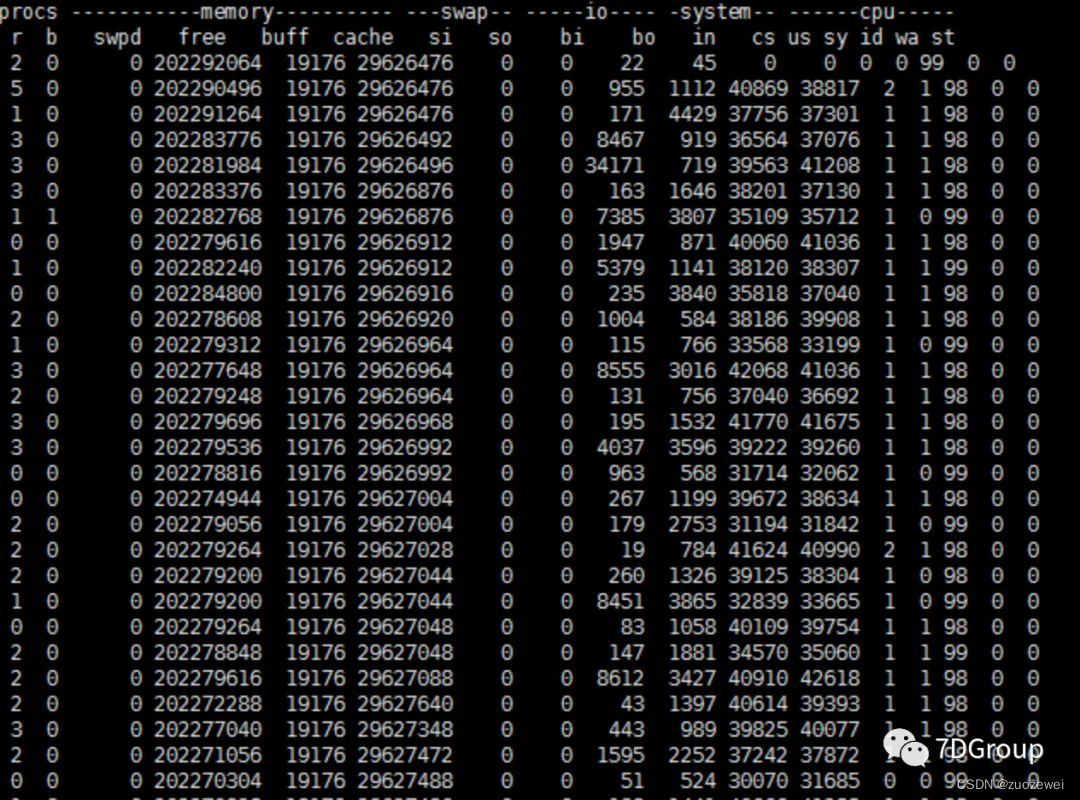
在看到这个图时,项目中有小同学说这个bi/bo是个瓶颈点,因为这里的值上上下下的,显然不规律嘛。并且也有挺高的时候,达到 3 万以上。那这个判断对不对呢?我们详细拆解一下。
从bi/bo两列来看,确实一直都是有值的。那这个值是不是我们的瓶颈点呢?在判断是不是瓶颈点之前,我们先算一下,这个值到底大不大。
如果你不清楚 bo 是什么,就先看一下命令的帮助,其中这样写到:

可见 bi、bo 是指的每秒读写的 block 个数。所以这个值不是字节,那既然不是字节,就要查一下block是多大。怎么查 block 是多大呢?先得看一下磁盘的格式。有很多种手段看磁盘的格式,这里我用 df -TH 来看。
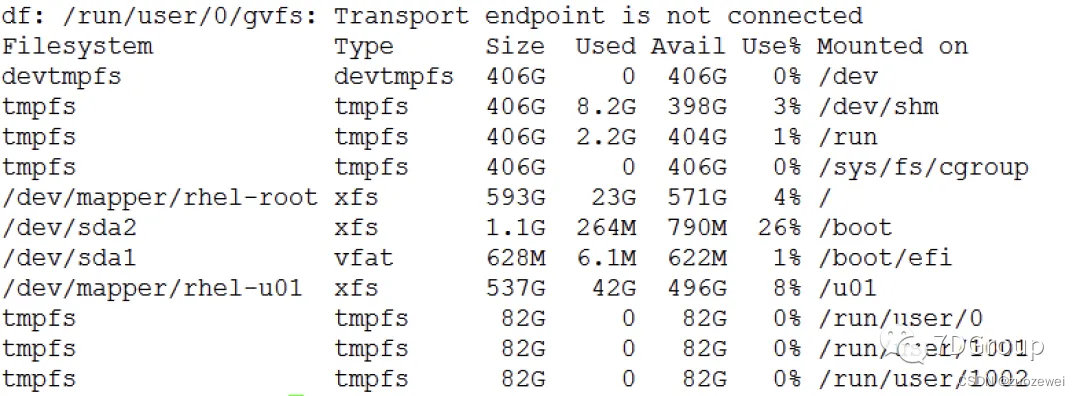
从Type一列来看,/dev/sda1用的是vfat,/dev/sda2用的是vfs,vdev/mapper/rhel-u01用的是xfs。文件类型有很多种,像cramfs,ext2,ext3,ext4,fat,msdos,xfs,btrfs,minix,vfat这些。 为什么这里我要查一下文件格式呢,因为不同的文件格式要用不同的命令来看block大小。
在这里,我们的文件是在 /u01 这个挂载点上的,所以格式就是 xfs,这里我用 xfs_info 来看磁盘的信息。

从上图中可以看到,bsize 是 4096 字节,如果你不理解这个输出,也可以看 xfs_info 的帮助中有一句:
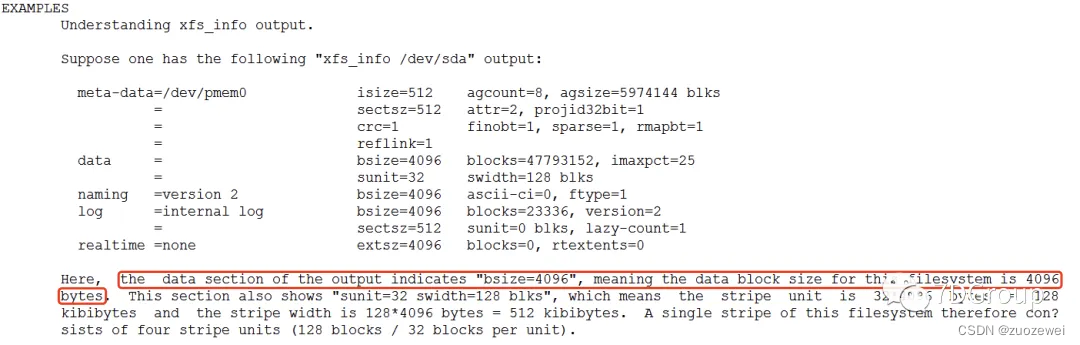
也就是说,一个block是4096字节。
再回到上面的vmstat输出:
- 最大的一次bi(读)是 34171 个block,也就是: ( 34171 x 4096 ) / 1024 / 1024 (34171x4096)/1024/1024 (34171x4096)/1024/1024 约为 133.48M。而其他的值显然都比它要小。
- 最大的一次bo(写)是 4429个 block,也就是: ( 4429 x 4096 ) / 1024 / 1024 (4429x4096)/1024/1024 (4429x4096)/1024/1024 约为 17.3M。
如果你有兴趣,可以把这一列的所有值都算一遍,看看读写的趋势。我即便没有一个个算,也大概能判断,这个读写的趋势一定是上上下下跨度很大的。像bi列最小的才19,bo列最小的是500多。
那这个趋势和我们的tps、响应时间有没有关系呢。再回来看一眼tps和响应时间图。
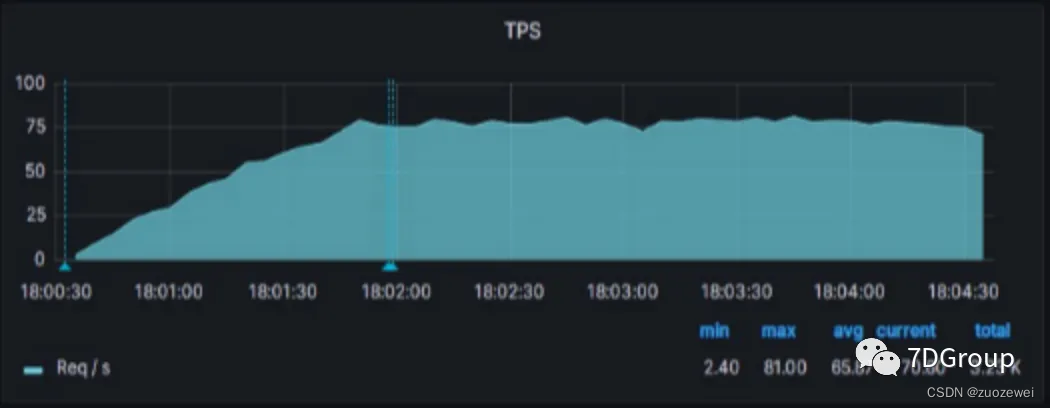
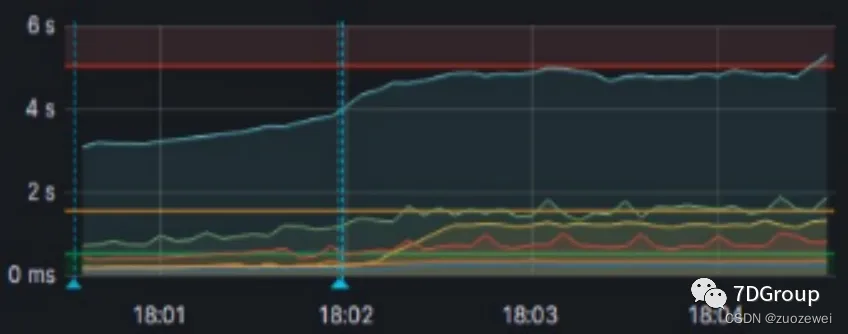
从趋势上看就对不上,因为tps比较平稳地上升,动荡幅度并不大,而响应时间也随着tps的增加也在上升,虽然慢,但是动荡幅度也并不大。
所以,上面的 bi/bo 和这个性能瓶颈点并没有关系。
上面的过程,在我看来才是分析,我们把别人脑子里认为的逻辑关系经过分析了之后,给出明确的答案,这是性能项目中经常的事情。
四、看到现象就蒙原因
在性能分析过程中,我经常看到一些人,看到现象就蒙原因。而这个蒙原因的过程由于没有完整的证据链,就会产生沟通上的误导。
只能让人根据蒙的原因试着去优化。一次、两次、三次,就会逐渐失去信任。
在我们这个项目中,我说过,如果没有明确的证据就不用找开发。因为那样会让开发觉得我们不是专业的,有些基础的自己可以判断的都在瞎蒙,怎么能得到别人技术上的尊重。
记得疫情期间做扫码系统的时候碰到一个架构师的角色的人,一个问题蒙了七次都没对。这样的人怎么会让人信任呢?
在这个项目中,也是因为一直这样要求团队,所以在和开发的沟通界面上,从一开始开发的被动配合,到后来的主动配合,时不时的还能唠个闲嗑。
如果你想在性能市场上生存下去,性能分析的思路一定是重要的能力之一。
这篇关于7D性能项目日记5:性能分析是查找瓶颈证据链的过程,而不是罗列数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






