本文主要是介绍生成人工智能体:人类行为的交互式模拟论文与源码架构解析(2)——架构分析 - 核心思想环境搭建技术选型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
4.架构分析
4.1.核心思想
超越一阶提示,通过增加静态知识库和信息检索方案或简单的总结方案来扩展语言模型。
将这些想法扩展到构建一个代理架构,该架构处理检索,其中过去的经验在每个时步动态更新,并混合与npc当前上下文和计划,可能会相互强化或矛盾。
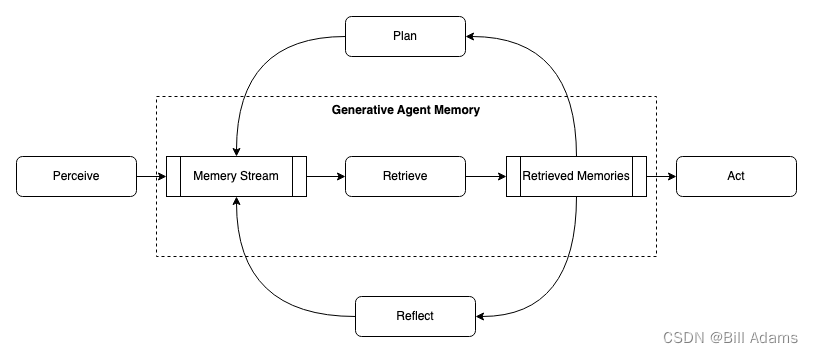
如上生成式NPC架构:NPC感知他们的环境,所有的感知都被保存在一个包含NPC经验的全面记录中,称为记忆流。基于NPC的感知,该架构检索相关的记忆,然后利用这些检索到的行为来确定一个动作。这些检索到的记忆还用于制定长期计划,并创建更高级别的反思,两者都被输入到记忆流中以备将来使用。
生成式NPC旨在为开放的世界提供一个行为框架:一个能够与其他NPC进行交互并能够对环境变化做出反应的框架。生成式NPC将它们当前的环境和过去的经验作为输入并产生行为作为输出。支撑这种行为的是一种新型NPC架构,它将大型语言模型与合成和检索相关信息的机制相结合,以使语言模型的输出具有条件性。如果没有这些机制,大型语言模型可以输出行为,但是结果可能不会基于NPC以往的经验做出反应、不会做出重要推理,也可能不会保持长期连贯性。即使是如GPT-4这样最表现良好的模型,长期规划和连贯性也存在挑战。由于生成式NPC产生大量需被保存的事件和记忆流,因此架构的主要挑战是确保NPC的记忆中最相关的部分在需要时被检索和综合。
架构的核心是记忆流,这是一个数据库,记录NPC的全部经历。从记忆流中检索记录,规划NPC的行动并对环境做出适当的反应,将记录递归地合成为更高级别的观察结果,指导行为。架构中的所有内容都以自然语言描述记录和推理,从而使架构能够利用大型语言模型。
架构包括三个主要组件。
第一个是记忆流,是一个长期记忆模块,以自然语言记录NPC经历的全面列表。检索模型将相关性、近期性和重要性相结合,以展现需要的记录,为NPC的及时行为提供信息。
第二个是反思,它将记忆综合成随着时间推移逐渐提高的推理,使NPC能够在指导其行为时对自身和他人进行结论。
第三个是规划,它将这些结论和当前环境转化为高层次的行动计划,然后递归地转化为详细的行为和反应。这些反思和计划被反馈到记忆流中,影响NPC未来的行为。
4.1.1.记忆与回忆
【挑战】创建能够模拟人类行为的生成式NPC需要对一个经验集合进行推理,这个集合比提示中描述的要大得多,因为完整的记忆流可能会分散模型的注意力,而且目前甚至无法适应有限的上下文窗口。考虑Isabella NPC回答“最近你热衷于什么?”这个问题。将所有的Isabella经验总结到语言模型有限的上下文窗口中,将得到一个无信息量的回答,Isabella会讨论一些关于活动与项目的合作、咖啡馆的清洁和组织等话题。而不是总结,下面描述的记忆流会呈现相关的记忆,从而产生更加信息丰富和具体的回答,提到Isabella热衷于让人们感到受欢迎和包容,策划活动并营造人们享受的氛围,比如情人节派对。
【方法】记忆流维护NPC经验的全面记录。它是一个存储记忆对象的列表,每个对象包含一个自然语言描述、一个创建时间戳和一个最近访问时间戳。记忆流的基本元素是一个观察,它是一个直接被NPC感知到的事件。常见的观察包括NPC自己执行的行为,或者NPC感知到其他NPC或非NPC对象执行的行为。例如,Isabella Rodriguez在咖啡馆工作,随着时间的推移,可能会积累以下观察:
(1) Isabella Rodriguez正在摆放糕点
(2) Maria Lopez正在喝咖啡复习化学考试
(3) Isabella Rodriguez和Maria Lopez正在谈论在霍布斯咖啡馆策划情人节派对
(4) 冰箱是空的。

记忆流包括许多与NPC当前情境相关和不相关的观察。检索确定了一部分这些观察,应该被传递给语言模型,以使它的回应对情境产生条件性
本架构实现了一个检索函数,将NPC的当前情境作为输入并返回一个子集的记忆流,以传递给语言模型。检索功能有许多可能的实现,这取决于NPC在决定如何行动时需要考虑的重要因素。在我们的情境中,我们关注三个主要组件,它们共同产生了有效的结果。
(1)最近性:将最近访问的记忆对象分配较高的分数,因此一段时间之前或今天早上的事件可能会留在NPC的注意力范围内。在此实现中,将最近性视为一个指数衰减函数,它是自上次检索记忆以来游戏时长的指数函数,衰减因子设定为 0.995。
(2)重要性:将普通记忆与核心记忆区分开来,通过对NPC认为重要的那些记忆对象分配较高的分数。例如,像在自己的房间里吃早餐这样的普通事件会得到较低的重要性分数,而与配偶分手这样的事件则会得到较高的分数。重要性分数的实现也有许多可能的方法;我们发现直接向语言模型输出整数分数是有效的。完整的提示如下:
在1到10的范围内,其中1是纯粹的日常事件(例如刷牙、整理床铺),10是极其深刻的事件(例如分手、被大学录取),请为下面的记忆片段评分,表示其可能的深刻程度 记忆: 在The Willows Market and Pharmacy购买杂货 评分: <填写>
此提示为“打扫房间”返回整数值2,为“向你的暗恋表白”返回整数值8。重要性分数是在创建记忆对象时生成的。
(3)相关性:为与当前情境相关的记忆对象分配较高的分数。什么是相关的取决于回答“相关于什么?”,因此我们会根据一个查询记忆对相关性进行限制。例如,如果查询是一个学生正在与同学讨论如何复习化学考试,他们的早餐记忆对象应该具有较低的相关性,而关于教师和功课的记忆对象应该具有较高的相关性。可使用语言模型生成文本描述的每个记忆的嵌入向量。然后将相关性计算为该记忆的嵌入向量与查询记忆的嵌入向量之间的余弦相似性。
为了计算最终权重得分,通过最大值最小值缩放将最近性、相关性和重要性分数归一化到[0,1]范围内。检索函数将所有记忆作为三个元素的加权组合进行评分:
𝑠𝑐𝑜𝑟𝑒 = 𝛼𝑟𝑒𝑐𝑒𝑛𝑐𝑦 · 𝑟𝑒𝑐𝑒𝑛𝑐𝑦 + 𝛼𝑖𝑚𝑝𝑜𝑟𝑡𝑎𝑛𝑐𝑒 ·𝑖𝑚𝑝𝑜𝑟𝑡𝑎𝑛𝑐𝑒 +𝛼𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑐𝑒 ·𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑐𝑒.
在具体实现中,所有的 𝛼 都设置为1。排名靠前的记忆将被包含在语言模型的上下文窗口中。
4.1.2.反思
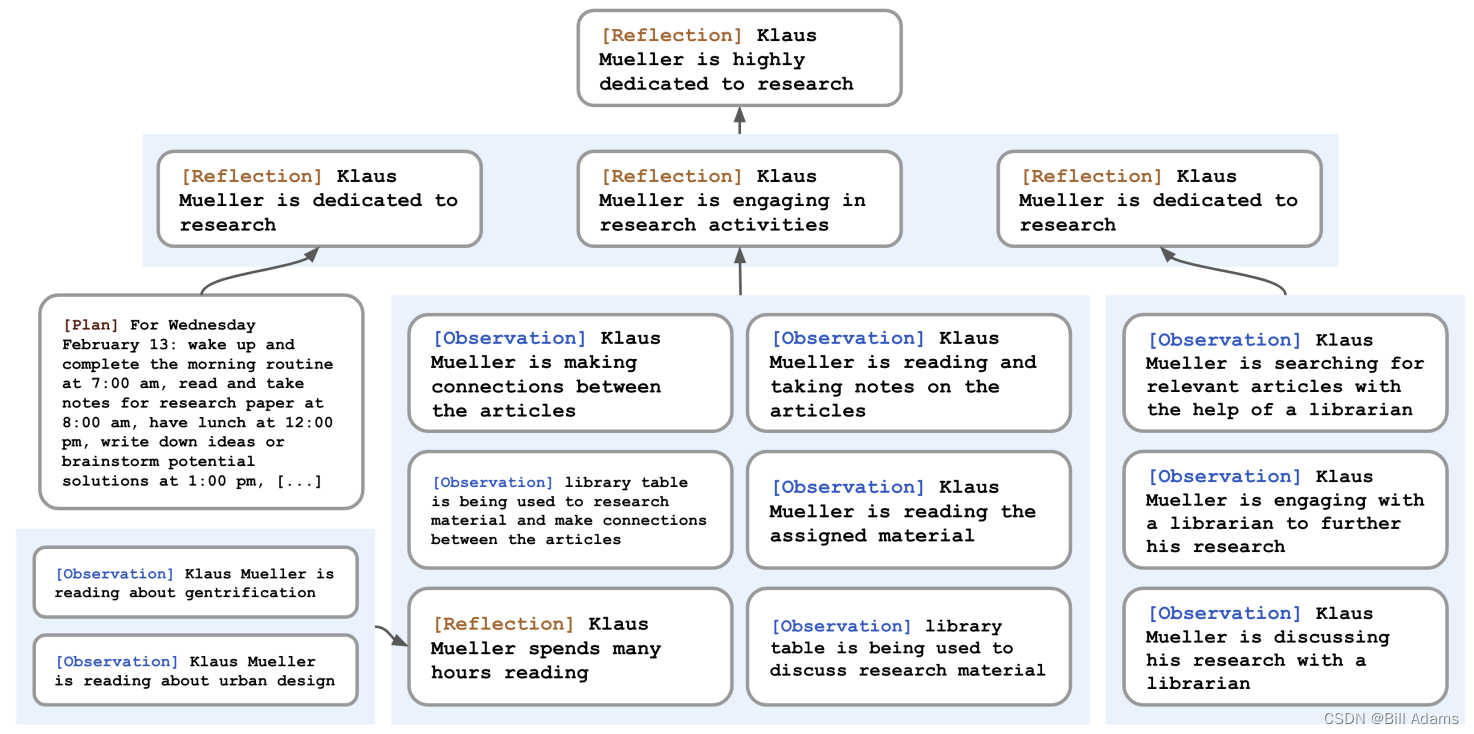
Klaus Mueller的反思树。NPC对世界的观察(代表在叶子节点中)被递归地综合起来,得出克劳斯(Klaus)高度致力于他的研究的自我观念。
【挑战】只提供原始观察记忆的生成代理在概括或推理方面存在困难。
考虑这样一种情况:用户问Klaus Mueller:“如果你必须选择你认识的一个人,和他/她共度一小时,你会选择谁?”只有观察性记忆的NPC只会简单地选择Klaus与之互动最频繁的人:他的大学宿舍邻居Wolfgang。不幸的是,Wolfgang和Klaus只是偶尔相遇,并没有深入的交流。更理想的回答需要NPC从Klaus花费时间在研究项目上的记忆中推广为更高水平的反思,即Klaus对研究充满热情,并且他也认识到Maria在自己的研究中投入了努力(尽管在不同的领域),从而使他们有一个共同的兴趣点。采用以下方法时,当Klaus被问及与谁共度时间时,他选择Maria而不是Wolfgang。
【方法】引入了第二种记忆类型,称为反思。反思是NPC生成的更高级、更抽象的思想。因为它们是一种记忆,所以它们在检索时与其他观察一起被包括在内。反思定期生成;在具体实现中,当NPC感知到的最新事件的重要性分数之和超过一定阈值时,则会生成反思。在实践中,NPC大约每天反思两到三次。反思的第一步是让NPC确定要反思什么,通过在NPC最近的经验中识别可以问的问题来完成。我们使用NPC的记忆流中的最近100个记录进行查询(例如“Klaus Mueller正在阅读有关城市更新的书”,“Klaus Mueller与图书馆员交谈他的研究项目”“图书馆的桌子当前没人使用”),并提示语言模型:“仅根据上述信息,我们可以对主题回答哪3个最显著的高级问题?“模型的响应会生成候选问题,例如,Klaus Mueller对哪个话题充满热情? Klaus Mueller和Maria Lopez之间的关系是什么?我们使用这些生成的问题作为检索查询,并收集与每个问题相关的记忆(包括其他反思)。然后提示语言模型提取见解并引用作为证据的特定记录。完整的提示如下:
关于Klaus Mueller的讲述:
- Klaus Mueller正在撰写一篇研究论文
- Klaus Mueller喜欢阅读一本有关城市更新的书
- Klaus Mueller正在与Ayesha Khan交谈有关锻炼的话题 请问你能从上述陈述中推断出哪五个高级见解?(例如格式:见解(因为1、5、3))
这个过程会生成像“Klaus Mueller致力于他在城市更新方面的研究(因为1、2、8、15)”这样的陈述。我们解析并将该陈述作为反思存储在记忆流中,包括引用的记忆对象的指针。
反思明确允许NPC不仅反思他们的观察,而且反思其他反思:例如,上面关于Klaus Mueller的第二个陈述是Klaus以前所持有的一个反思,而不是他的环境观测结果。因此,NPC会生成反思树:树的叶节点代表基本观察,而非叶节点代表更抽象、更高层次的思想,它们越往上,就越高级。
4.1.3.计划与反应
【挑战】虽然大型语言模型可以根据情境信息生成合理的行为,但NPC需要制定更长远的计划,以确保他们的行动序列连贯和可信。如果我们用Klaus的背景描述时间并询问他在给定时刻应该采取什么行动,Klaus将在12点和1点吃两次午餐,尽管他已经吃过午餐了。在当前情况下优化可信度会牺牲长期可信度。要解决这个问题,计划是必不可少的。使用以下方法,Klaus的下午计划少了些贪婪:他在Hobbs Cafe用餐并阅读,时间是12点,1点在学校图书馆工作撰写研究论文,3点在公园散步。
【方法】计划描述了NPC的未来行动序列,并有助于保持NPC的行为一致性。计划包括位置、开始时间和持续时间。例如,致力于研究和即将到来的截止日期的Klaus Mueller可能选择在他的桌子上工作,起草他的研究论文。计划的条目可能会说明:从2023年2月12日上午9点起,持续180分钟,在Oak Hill学生宿舍:Klaus Mueller的房间:桌子上,阅读和笔记研究论文。与反思一样,计划存储在记忆流中,并在检索过程中包括在内。这使得NPC在决定如何行动时可以同时考虑观察、反思和计划。NPC可以在需要时改变他们的计划。
让一位艺术家NPC在药房台坐四个小时画画是不现实和不有趣的。一个更理想的计划是,在四个小时的时间里,艺术家NPC花费必要的时间收集材料、调色、休息和清理工作室。为了创建这样的计划,我们的方法从上到下递归地生成更详细的信息。第一步是创建一份规划,概述全天的日程安排。为了创建最初的计划,我们提示语言模型代理的概述描述(例如名字、特征和他们最近经历的概述)和他们前一天的概述。下面是一个完整的示例提示,末尾未完成以供语言模型完成:
姓名:Eddy Lin(年龄:19岁)
内在特质:友好、外向、好客
Eddy Lin是一名在Oak Hill学院学习音乐理论和作曲的学生。他喜欢探索不同的音乐风格,总是在寻求扩展自己知识的方法。Eddy Lin正在为他的学院课程工作作曲项目。他还在上课学习更多关于音乐理论的东西。Eddy Lin对他正在工作的新作曲项目感到兴奋,但他希望在未来的几天里能够抽更多时间来工作。
2月12日星期二,Eddy 1)在早上7点起床并完成了早晨的日常事务[…] 6)准备在晚上10点睡觉。
今天是2月13日星期三。这是Eddy今天的整体计划:1)(此处未完成,留给语言模型完成)
这产生了NPC一天的粗略计划草图,分为五到八个活动段: “1)早上8点起床并完成早晨的日常事务,2)在Oak Hill学院上午10点开始上课,[…] 5)从下午1点到下午5点工作于他的新音乐作品,6)下午5:30吃晚餐,7)完成学校作业并在晚上11点睡觉。”
NPC将此计划保存在记忆流中,然后递归将其分解以创建更细粒度的动作,首先将其分解成每小时的动作块—— Eddy计划从下午1点到下午5点工作于他的新音乐作品,变为 1:00 下午:开始构想音乐作品的一些想法[…] 4:00 下午:休息片刻,重新激发他的创造力,以便审核和润色他的作品。然后我们再递归将其分解成5-15分钟的块:例如,下午4:00:拿些简单的零食,比如一块水果、一根麦片棒或几颗坚果。下午4:05:在他的工作区走一圈[…]下午4:50:花几分钟清理他的工作区。这个过程可以调整以匹配所需的粒度。
(1)反应与更新计划
生成型代理在一个行动循环中运行,在每个时间步中,它们感知周围的世界,这些感知观察结果存储在它们的记忆流中。我们使用这些感知观察结果提示语言模型,以决定NPC是否应该继续执行现有计划,还是进行反应。例如,站在画架前画画可能会触发画架的观察结果,但这不太可能会引起反应。然而,如果Eddy的父亲约翰记录了他看到Eddy在家里的花园里散步,结果就不同了。下面是提示信息,其中[代理概述]代表动态生成的、段落长的代理总体目标和性格概述:
[代理概述] 现在是2023年2月13日下午4:56。约翰·林的状态:约翰从工作中提前回家。 观察结果:约翰看到Eddy在他的工作场所周围散步。 从约翰记忆中整理出的相关背景概述:Eddy Lin是约翰·林的儿子。Eddy Lin正在为他的课程作曲。Eddy Lin喜欢在思考或听音乐时四处散步花园。 约翰应该对这个观察结果做出反应吗?如果应该,什么是一个适当的反应?
上下文概述是通过两次提示生成的,这些提示通过查询“[观察者]与[被观察实体]的关系是什么?”和“[被观察实体]是[被观察实体的行动状态]”,并将它们的答案总结在一起。输出表明,约翰可以考虑问问Eddy关于他的音乐作品的计划。然后,我们重新生成NPC的现有计划,从做出反应时开始。最后,如果行动表明NPC之间有交互,我们会生成他们的对话。
(2)对话
NPC与彼此交互时会进行对话。通过将NPC的话语与他们彼此间的记忆联系起来来生成对话。例如,当约翰与Eddy开始对话时,会使用他们关于彼此的总结性记忆以及当他决定询问Eddy有关他的作曲计划时的预期反应,来生成约翰的第一次话语。
[代理概述] 现在是2023年2月13日下午4:56。约翰·林的状态:约翰从工作中提前回家。 观察结果:约翰看到Eddy在他的工作场所周围散步。 从约翰记忆中整理出的相关背景概述:Eddy Lin是约翰·林的儿子。Eddy Lin正在为他的课程作曲。Eddy Lin喜欢在思考或听音乐时四处散步花园。 约翰正在问Eddy有关他的音乐作品的计划。他会对Eddy说什么?
结果是:“嘿 Eddy,你的音乐作品课程计划进展如何?”从Eddy的角度来看,约翰发起对话被认为是一个可能需要他做出反应的事件。因此,就像约翰一样,Eddy检索和总结他与约翰的关系的记忆,以及与对话中约翰最后一个话语相关的记忆。如果他决定回应,我们会使用他的总结性记忆和当前的对话历史来生成Eddy的话语:
[代理概述] 现在是2023年2月13日下午4:56。Eddy Lin的状态:Eddy正在他的工作场所周围散步。 观察结果:约翰正在与Eddy开始对话。 从Eddy的记忆中整理出的相关背景概述:Jonn Lin是Eddy Lin的父亲。John Lin关心Eddy Lin,并且有兴趣了解更多关于Eddy Lin的学校工作的事情。John Lin知道Eddy Lin正在进行音乐作曲。 以下是对话历史记录: 约翰:嘿,Eddy,你的音乐作品课程计划进展如何? Eddy会如何回应约翰?
这会产生Eddy的回应:“嘿,爸爸,进展不错。我一直在花园里散步,以便头脑清晰,获得灵感。”使用相同的机制生成对话的连续部分,直到其中一个NPC决定结束对话。
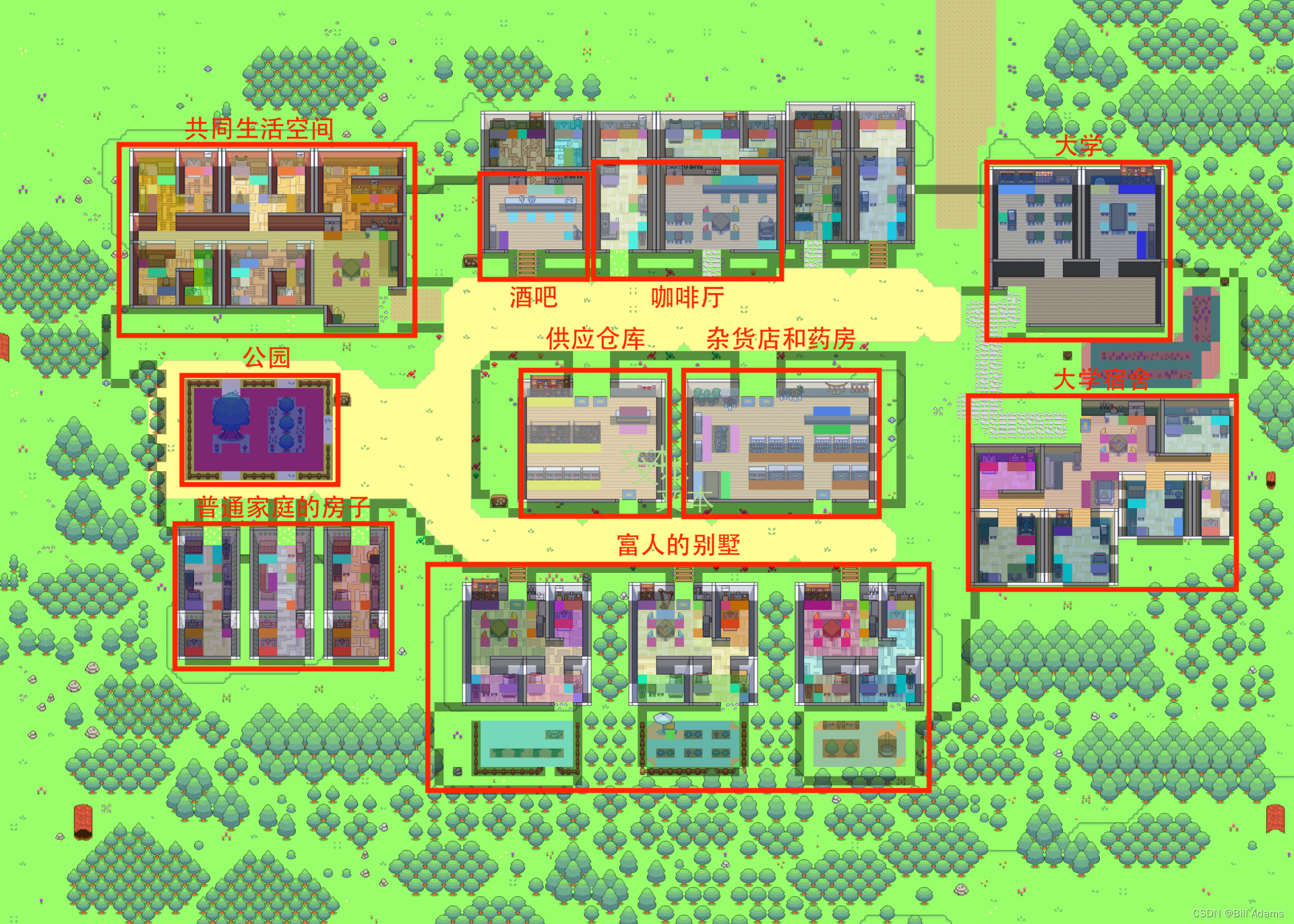
4.2.环境搭建
4.2.1.环境设置
(1)生成配置文件
在 reverie/backend_server 文件夹( reverie.py 所在的位置)中,创建一个名为 utils.py 的新文件,并将以下内容复制并粘贴到该文件中,并将 <name> 替换为您的姓名:
# Select the GPT4All Model you'll use for the simulation. See: https://observablehq.com/@simonw/gpt4all-models
gpt4all_model="orca-mini-3b.ggmlv3.q4_0.bin"
max_tokens = 30
temperature = 0.5# Put your name
key_owner = "<Name>"maze_assets_loc = "../../environment/frontend_server/static_dirs/assets"
env_matrix = f"{maze_assets_loc}/the_ville/matrix"
env_visuals = f"{maze_assets_loc}/the_ville/visuals"fs_storage = "../../environment/frontend_server/storage"
fs_temp_storage = "../../environment/frontend_server/temp_storage"collision_block_id = "32125"# Verbose
debug = True(2)安装requirements
pip install -r requirements.txt
建议版本:Python 3.9.12
4.2.2.运行模拟器
需要同时启动两个服务器:环境服务器和代理模拟服务器。
(1)启动环境服务器
环境是使用 Django实现,切换至至 environment/frontend_server目录 (这是 manage.py 所在的位置)。然后运行以下命令:
python manage.py runserver浏览器上访问 http://localhost:8000/,建议浏览器:chrome、Safari
(2)启动代理模拟服务器
打开另一个命令行并切换到到 reverie/backend_server目录,运行 reverie.py:
python reverie.py这将启动模拟服务器。将出现命令行提示,询问以下内容:“输入分叉模拟的名称:”。有两个选项可以支持,一个是与 Isabella Rodriguez、Maria Lopez 和 Klaus Mueller 启动 3 NPC模拟,一个是与25个NPC模拟,其中3NPC模拟请输入以下内容:
base_the_ville_isabella_maria_klaus<5NPC模拟:base_the_ville_n25>然后提示将询问“输入新模拟的名称:”。输入任何名称来表示您当前的模拟(例如,现在只需“测试模拟”即可)。
test-simulation保持模拟器服务器运行。此时会显示如下提示:“输入选项:”
(3)运行与保存模拟
在浏览器上,导航至 http://localhost:8000/simulator_home。您应该会看到The Ville的地图,以及地图上的活跃特工列表。您可以使用键盘箭头在地图上移动。请保持此选项卡打开。要运行模拟,请在模拟服务器中键入以下命令以响应提示“输入选项”:
run <step-count>请注意,您需要将上面的<step-count>替换为一个整数,表示您要模拟的游戏步骤数。例如,如果你想模拟100个游戏步骤,你应该输入run 100。一个游戏步骤代表游戏中的 10 秒。
您的模拟应该正在运行,您将看到代理在浏览器中的地图上移动。一旦模拟运行完成,“输入选项”提示将再次出现。此时,您可以通过重新输入带有所需游戏步骤的运行命令来模拟更多步骤,通过键入 exit 退出模拟而不保存,或通过键入 fin 保存并退出。
通过提供模拟名称作为分叉模拟,可以在下次运行模拟服务器时访问保存的模拟。这将允许您从上次停止的位置重新开始模拟。
您保存的所有模拟将位于 environment/frontend_server/storage 中,所有压缩演示将位于 environment/frontend_server/compressed_storage 中。
(4)重放模拟
只需运行环境服务器并在浏览器中导航到以下地址即可重播已运行的模拟: http://localhost:8000/replay/<simulation-name>/<starting-time-step><simulation-name> 替换为您要重播的模拟名称,并将 <starting-time-step> 替换为您希望开始重播的整数时间步长。
例如,通过访问以下链接,您将启动一个预模拟示例,从时间步 1 开始:
http://localhost:8000/replay/July1_the_ville_isabella_maria_klaus-step-3-20/1/
(5)演示模拟
您可能已经注意到重播中的所有角色精灵看起来都相同。我们想澄清的是,重播功能主要用于调试目的,并不优先考虑优化模拟文件夹或视觉效果的大小。为了正确演示具有适当角色精灵的模拟,您需要首先压缩模拟。为此,请使用文本编辑器打开位于 reverie 目录中的 compress_sim_storage.py 文件。然后,执行 compress 函数,并将目标模拟的名称作为其输入。这样,模拟文件将被压缩,以便为演示做好准备。
要启动演示,请在浏览器上访问以下地址: http://localhost:8000/demo/<simulation-name>/<starting-time-step>/<simulation-speed><simulation-name> 和 <starting-time-step> 表示与上面提到的相同的事物。 <simulation-speed> 可以设置控制演示速度,其中1最慢,5最快。例如,访问以下链接将启动一个预模拟示例,从时间步 1 开始,具有中等演示速度:
http://localhost:8000/demo/July1_the_ville_isabella_maria_klaus-step-3-20/1/3/
4.2.3.定制化
有两种方法可以选择自定义您的模拟。
(1)编写和加载代理的记忆
首先是在模拟开始时初始化具有唯一历史记录的代理。为此,您需要
1) 使用基本模拟之一开始模拟,2) 创建和加载代理历史记录。更具体地说,步骤如下:
如果要通过创作自己的历史文件来自定义初始化,请将文件放置在以下文件夹中: environment/frontend_server/static_dirs/assets/the_ville 。自定义历史文件的列格式必须与包含的示例历史文件相匹配。因此,我们建议通过复制并粘贴存储库中已有的内容来开始该过程。
存储库中包含两个基本模拟:具有 25 个代理的 base_the_ville_n25 和具有 3 个代理的 base_the_ville_isabella_maria_klaus 。按照上述步骤直至步骤 2 加载基本模拟之一。
然后,当提示“输入选项:”时,通过响应以下命令来加载代理历史记录:
call -- load history the_ville/<history_file_name>.csv
请注意,您需要将 <history_file_name> 替换为现有历史文件的名称。存储库中包含两个历史文件作为示例: agent_history_init_n25.csv 用于 base_the_ville_n25 和 agent_history_init_n3.csv 用于 base_the_ville_isabella_maria_klaus 。这些文件包括每个代理的以分号分隔的内存记录列表 - 加载它们会将内存记录插入到代理的内存流中。
(2)创建新的基础模拟
对于更复杂的定制,您将需要编写自己的基础模拟文件。最直接的方法是复制并粘贴现有的基本模拟文件夹,根据您的要求对其进行重命名和编辑。如果您决定保持代理名称不变,此过程会更简单。但是,如果您希望更改他们的名称或增加TheVille地图可容纳的NPC数量,您可能需要使用平铺地图编辑器直接编辑地图。
4.3.技术选型
-
前端:Phaser web游戏引擎
-
后端:Django + OpenAI(GPT4All/wenxin)
由于内容太多,请接下文:架构分析 - 实现分析&数据结构&核心逻辑
这篇关于生成人工智能体:人类行为的交互式模拟论文与源码架构解析(2)——架构分析 - 核心思想环境搭建技术选型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






