本文主要是介绍[自研开源] MyData v0.8 数据集成之实时同步,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
开源地址:gitee | github
详细介绍:MyData 基于 Web API 的数据集成平台
诚邀试用
可通过界面配置 实现API数据集成,减少集成工作,诚挚邀请更多用户试用;
系统的主要功能和优势:
- 集成度高:通过API集成数据,没有数据库类型、开发技术等限制,有API即可对接;
- 数据安全:无需开放业务系统数据库;
- 零侵入性:无SDK,业务系统有API即可集成;
- 可控性高:统一调度集成任务,对业务系统几乎无感知;
- 复用性高:业务系统迁移、技术升级等,无需重复集成,API可用即可恢复集成;
- 私有部署:支持本地部署,防止数据外泄;
特此承诺:
作为试用用户可享受 免费试用、免费升级功能、全程技术支持;
前10位纳入实际项目使用的将成为永久免费用户;
试用方式:联系微信,开通专属账号,开展数据集成;
截止日期:2024-08-30

案例:电商场景 - 跨平台实时同步商品库存
接之前的定时同步案例,本次通过界面配置对接两个商城系统的webhook,实现商品库存的实时同步;
预期实现的流程如下:
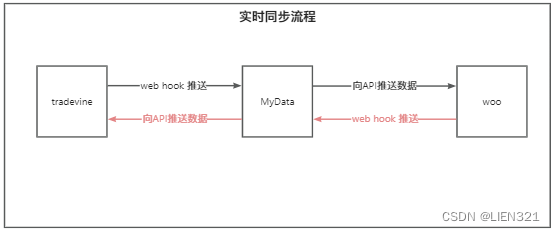
主要过程:
- MyData提供两个接口,分别配置到两个系统的webhook;
- 当一方有库存变更时,调用webhook中配置的接口,接收业务数据;
- MyData接收并存储数据;
- 同时触发业务数据的消费任务,调用另一方接口推送更新的数据;
MyData配置过程
-
配置数据来源任务,接收trade webhook推送的数据
- 创建
提供数据类型的任务 - 模式选择
接收推送 - 选择
认证方式和认证参数 - 配置接口与业务数据的
字段映射
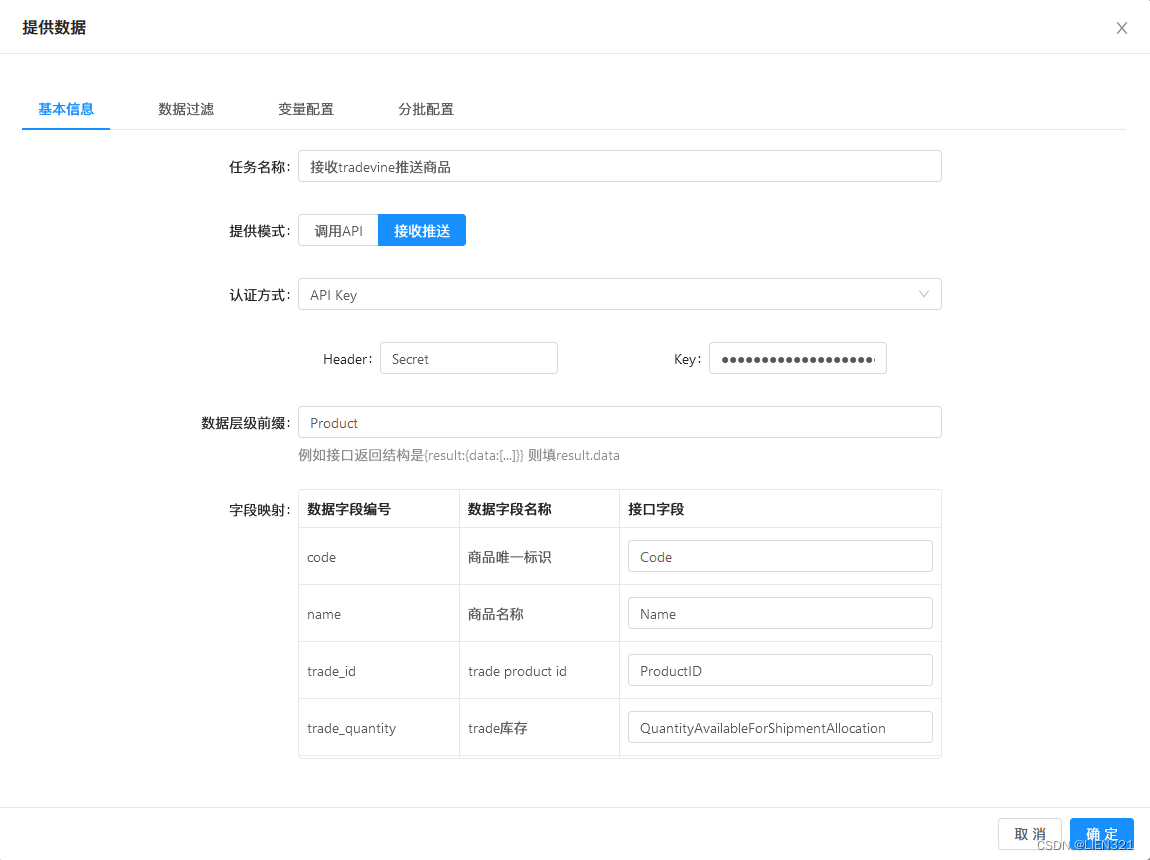
- 创建
-
保存任务后,未任务生成了随机地址,点击复制
-
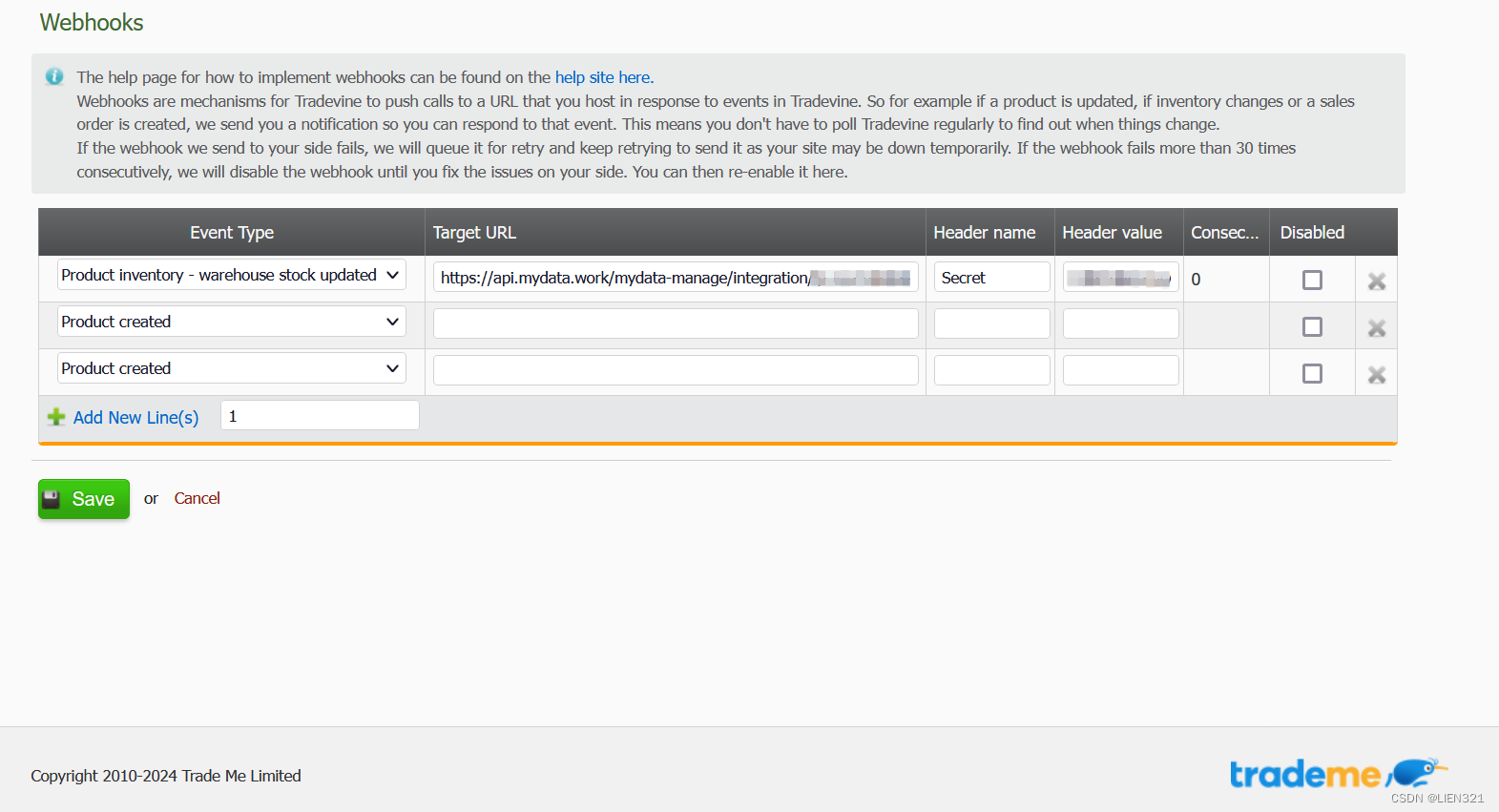
在tradevine的webhook配置中 选择
warehouse stock updated事件,填写目标地址和Header参数;
-
然后配置数据消费任务,调用woo系统的接口 更新商品库存
- 创建
消费数据类型的任务 - 模式选择
调用API,并选择API接口 - 选择
订阅,并选择触发订阅的任务为上一个配置的任务 - 单数据模式选择
对象 - 配置接口与业务数据的
字段映射
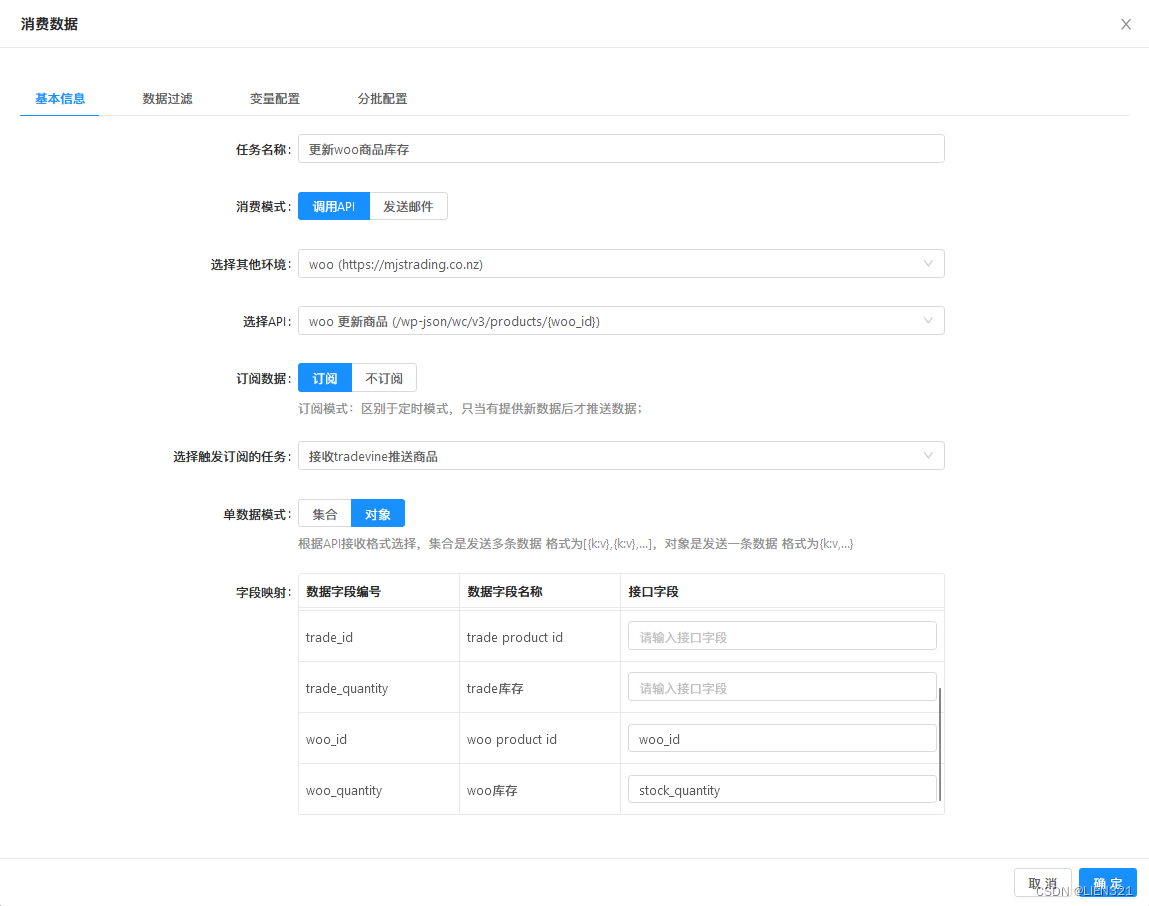
- 创建
-
自此完成了一方的实时同步,另一方采用相同配置即可;
-
实时同步的执行过程
- 当trade系统中 库存数量发生变化时,触发并调用webhook接口,以下是接口执行过程代码片段:
@Slf4j
@RestController
@AllArgsConstructor
@RequestMapping(MdConstant.API_PREFIX_MANAGE + "/integration")
public class IntegrationEndpoint {@Resourceprivate final ITaskService taskService;@Resourceprivate final JobExecutor jobExecutor;@PostMapping("/{task_url}")public R post(@PathVariable("task_url") String taskUrl, @RequestHeader HttpHeaders httpHeaders, @RequestBody String body) {log.info("integration post");return execute(taskUrl, httpHeaders, body);}@PutMapping("/{task_url}")public R put(@PathVariable("task_url") String taskUrl, @RequestHeader HttpHeaders httpHeaders, @RequestBody String body) {log.info("integration put");return execute(taskUrl, httpHeaders, body);}private R execute(String taskUrl, HttpHeaders httpHeaders, String body) {log.info("integration url : {}", taskUrl);log.info("integration headers : {}", httpHeaders);log.info("integration body : {}", body);Assert.notEmpty(taskUrl, "操作失败:地址 {} 无效!", taskUrl);Task task = taskService.findByApiUrl(taskUrl);Assert.notNull(task, "操作失败:地址 {} 无效!", taskUrl);Assert.equals(task.getTaskStatus(), MdConstant.TASK_STATUS_RUNNING, "操作失败:任务未启动 无法执行!");// 省略校验过程...// 执行任务流程 接收数据jobExecutor.acceptData(task, body);return R.success(StrUtil.format("任务 [{}] 开始执行,请查看日志。", task.getTaskName()));}
}
- 任务流程中,使用accept到的json数据,根据字段映射进行解析和保存
// 将json按字段映射 解析为业务数据
jobDataService.parseProduceData(taskInfo, json);// 根据条件过滤数据
if (CollUtil.isNotEmpty(taskInfo.getDataFilters())) {taskInfo.appendLog("过滤业务数据开始");taskInfo.appendLog("过滤条件:{}", taskInfo.getDataFilters());jobDataFilterService.doFilter(taskInfo);taskInfo.appendLog("过滤后的剩余数据量:{}", taskInfo.getProduceDataList().size());if (CollUtil.isEmpty(taskInfo.getProduceDataList())) {taskInfo.appendLog("过滤后的没有业务数据,跳过后续处理");break;}
}// 保存业务数据
jobDataService.saveTaskData(taskInfo);// 更新环境变量
jobVarService.saveVarValue(taskInfo, json);// 递增分批参数
jobBatchService.incBatchParam(taskInfo);
- 接收任务完成后,查询订阅该任务的消费任务,使用相同任务批次号 以便消费相同的业务数据
// 查询相同数据的订阅任务
List<Task> subTasks = taskService.listRunningSubTasks(taskInfo.getDataId(), taskInfo.getEnvId(), taskInfo.getId());
subTasks.forEach(task -> {TaskInfo subTaskInfo = build(task);// 订阅任务现在执行subTaskInfo.setStartTime(new Date());// 设置数据批次编号subTaskInfo.setDataBatchId(taskInfo.getDataBatchId());// 指定订阅任务,调用接口发送数据executeJob(subTaskInfo);
});
- 消费任务中,查询相同批次的数据,并调用API发送数据
// 订阅任务 使用任务批次号 查询数据
if (MdConstant.TASK_IS_SUBSCRIBED.equals(taskInfo.getIsSubscribed())) {// 构建数据批次查询条件 _MD_BATCH_ID_ = dataBatchIdBizDataFilter bizDataFilter = new BizDataFilter();bizDataFilter.setKey(MdConstant.DATA_COLUMN_BATCH_ID);bizDataFilter.setOp(MdConstant.DATA_OP_EQ);bizDataFilter.setValue(taskInfo.getDataBatchId());bizDataFilter.setType(MdConstant.TASK_FILTER_TYPE_VALUE);filters.add(bizDataFilter);
}
// 消费模式是调用API
if (MdConstant.TASK_CONSUME_MODE_API.equals(taskInfo.getConsumeMode())) {// 根据字段映射转换为api参数jobDataService.convertConsumeData(taskInfo);// 若消费任务是对象模式,则从字段映射中提取数据 替换url上的变量if (MdConstant.TASK_SINGLE_MODE_OBJECT.equals(taskInfo.getSingleMode())) {// 从url中解析出变量jobVarService.parseConsumeUrlVar(taskInfo);taskInfo.appendLog("替换API变量后 新地址为:url={}", taskInfo.getApiUrl());}// 调用api传输数据taskInfo.appendLog("调用API 获取数据,method={},url={},headers={},params={}", taskInfo.getApiMethod(), taskInfo.getApiUrl(), taskInfo.getReqHeaders(), taskInfo.getReqParams());String json = ApiUtil.write(taskInfo);// 更新环境变量jobVarService.saveVarValue(taskInfo, json);
}
这篇关于[自研开源] MyData v0.8 数据集成之实时同步的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






