本文主要是介绍通过超分辨率像素引导的Scribble Walking和逐类对比正则化的弱监督医学图像分割(SC-Ne)论文速读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- Weakly Supervised Medical Image Segmentation via Superpixel-Guided Scribble Walking and Class-Wise Contrastive Regularization
- 摘要
- 方法
- 实验结果
Weakly Supervised Medical Image Segmentation via Superpixel-Guided Scribble Walking and Class-Wise Contrastive Regularization
摘要
基于深度学习的分割通常需要大量数据和密集的手动描绘,这既耗时又昂贵。因此,弱监督学习试图利用稀疏的注释(如涂鸦)进行有效训练,引起了相当大的关注。然而,这种涂鸦监督本质上缺乏足够的结构信息,导致了两个关键挑战:(i)虽然在dice分数指标上取得了良好的性能,但现有方法难以执行令人满意的局部预测,因为在训练期间无法获得所需的结构先验;(ii)由于稀疏和极不完全的监督,类特征分布不可避免地不那么紧凑,导致泛化性差。
本文中,我们提出了SC-Net,这是一种新的涂鸦监督方法,它将超像素引导的涂鸦行走与类对比正则化相结合。
该框架建立在最近的双解码器主干设计之上,其中来自两个略有不同的解码器的预测被随机混合,以提供辅助伪标签监督。除了稀疏和伪监督外,涂鸦还向超像素连接和图像内容引导的未标记像素扩散,以提供尽可能多的密集监督。然后,类对比正则化断开不同类的特征分布,以促进类特征分布的紧凑性。
方法
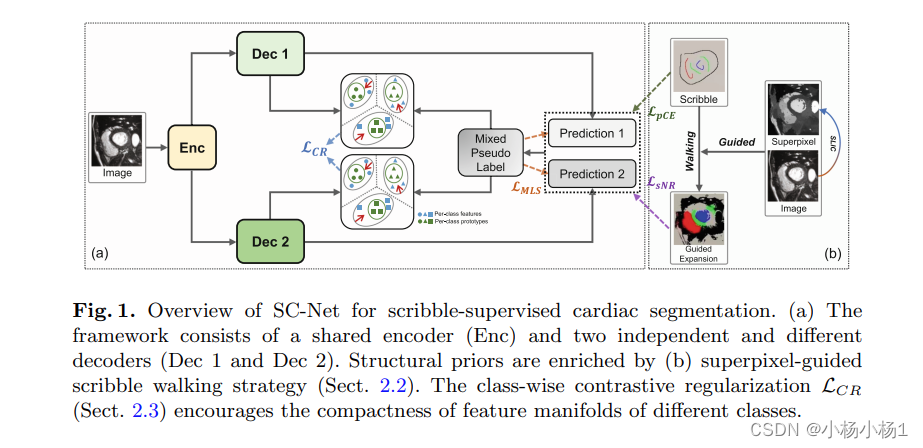
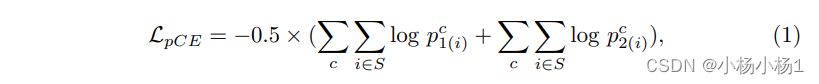
采用简单的线性迭代聚类(SLIC)算法来生成超像素
SLIC工作原理: 首先将图像划分为大小相等的方块网格,然后根据所需的超像素数 K 在每个方块中选择一定数量的种子点。接下来,它根据每个像素的颜色相似度和空间邻近性(距离)迭代地将每个像素分配给最近的种子点。重复此过程,直到聚类收敛或达到预定义的迭代次数。最后,该算法将种子点的位置更新到相应超像素的质心,并重复直到收敛。因此,图像被粗略地分割成 K 个簇。
然后,在获得的超像素的引导下,涂鸦通过以下机制走向未标记的像素:
(i)如果超像素簇与涂鸦重叠,则 涂鸦r 走向该簇中包含的像素;
(ii) 然而,如果超像素簇不与任何涂鸦重叠或与多个涂鸦重叠,则不会为该簇中的像素分配任何标签。尽管我们使用严格的行走约束来扩展标签,但超像素主要基于颜色相似性和与种子点的空间邻近性
采用noise-robust Dice loss来监督模型,公式为:
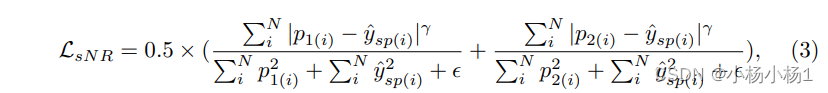
成对的对比正则化如下:z为原型,N为原型的数量
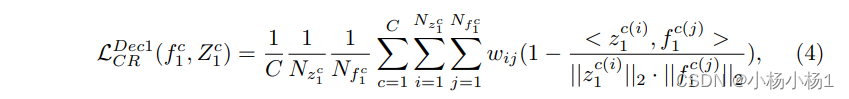
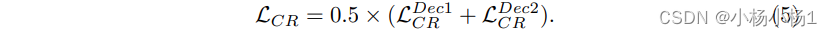
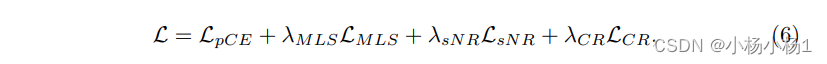
实验结果

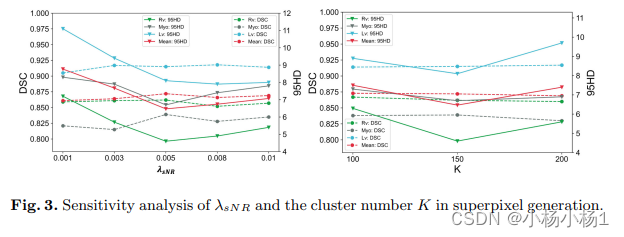
这篇关于通过超分辨率像素引导的Scribble Walking和逐类对比正则化的弱监督医学图像分割(SC-Ne)论文速读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





