本文主要是介绍【精读文献】Scientific data|2017-2021年中国10米玉米农田变化制图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文名称:Mapping annual 10-m maize cropland changes in China during 2017–2021
第一作者及通讯作者:Xingang Li, Ying Qu
第一作者单位及通讯作者单位:北京师范大学地理学部
文章发表期刊:《Scientific data》(中科院2区期刊|最新影响因子:9.8)
期刊平均审稿周期:16周
1.文章摘要
在过去几年中,中国的玉米产量占世界玉米产量的近五分之一。绘制中国玉米农田分布图对确保全球粮食安全至关重要。尽管如此,中国仍有10米玉米农田地图无法获取,这限制了可持续农业的推广。在本文中,我们收集了大量样本,利用基于机器学习的分类框架,制作了2017年至2021年中国每年10米的玉米农田地图。为了克服植物的时间变化,该框架以Sentinel-2序列图像为输入,利用深度神经网络和随机森林作为分类器,以特定区域的方式绘制玉米地图。总体精度(OA)在0.87-0.95之间,估算的玉米种植面积与统计年鉴记录高度吻合(R²在0.83-0.95之间)。据我们所知,这是中国首份年度10米玉米地图,在很大程度上促进了以小农为主的中国农业可持续发展。
2.研究背景及意义
在过去的几年里,中国贡献了世界上近五分之一的玉米生产。绘制中国玉米农田分布对于确保全球粮食安全至关重要。尽管如此,仍然没有中国10米玉米农田地图,这限制了可持续农业的推进。了解中国玉米种植模式对于促进农业管理和确保粮食安全具有重要意义。
3.研究方法
3.1 研究区域
本研究将中国的玉米种植区根据当地气候和耕作方式划分为北方、黄淮海、西南、西北和南方五个区域。根据《中国统计年鉴23-27》,这五个研究区覆盖了中国玉米种植面积的99.9%以上,如图1所示。
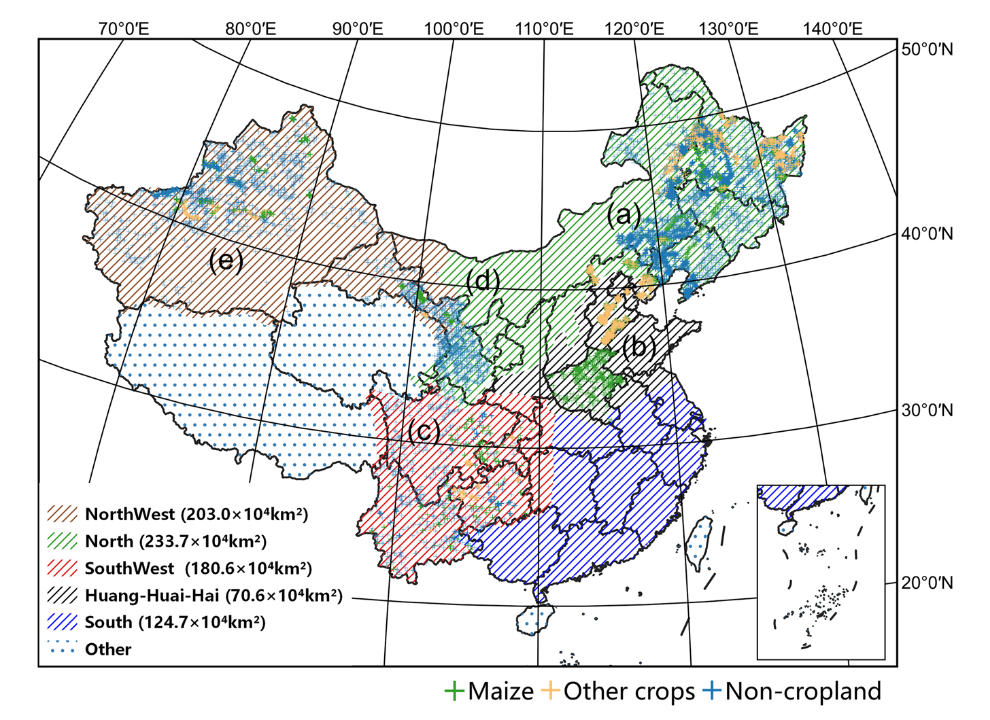
图1|在中国收集的样本概况。不同的纹理背景代表不同的农业生态区,分为北方、西北、西南、黄淮海和南方。(a-e)分别表示样品在华北、黄淮海、西南、甘肃和新疆的分布。
3.2 玉米制图过程
中国的农业景观主要由小农农田决定,农田的大小在很大程度上取决于农业生态和经济环境。在小规模农田中,很难根据从具有混合像素的 10 米空间分辨率图像中提取的纹理特征来识别作物类型。因此,本研究使用Sentinel-2 (S2)图像的时间序列数据作为分类模型的输入来提取分层时间表示。该框架的概述如图2所示,它包括以下四个主要步骤,即图像预处理、样本收集、分类和后处理。
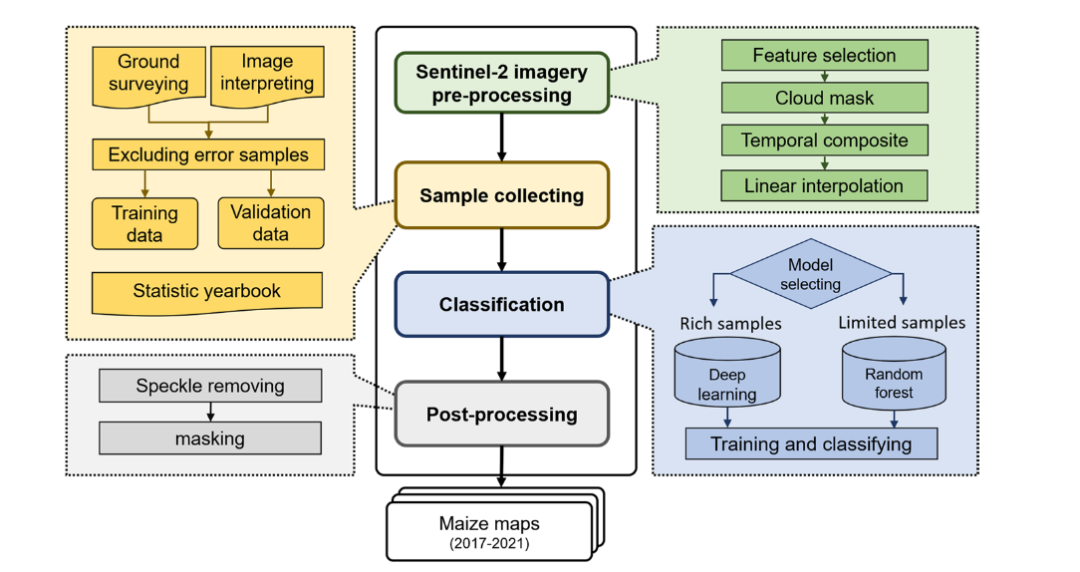
图2 本研究的玉米制图框架概述
(1)图像预处理步骤包括波段选择(为了减少图像的光谱冗余,提高本文方法的效率,计算玉米样本上不同光谱的Pearson相关系数,去除相关性大于0.98的波段,如图3所示)、去云、多时相图像合成和样本的可视化插值(为了恢复被云覆盖的区域,使用每30天间隔的中位数合成了S2图像。然后,通过使用前一个月和后一个月的图像进行线性插值来填充缺失的像素)。
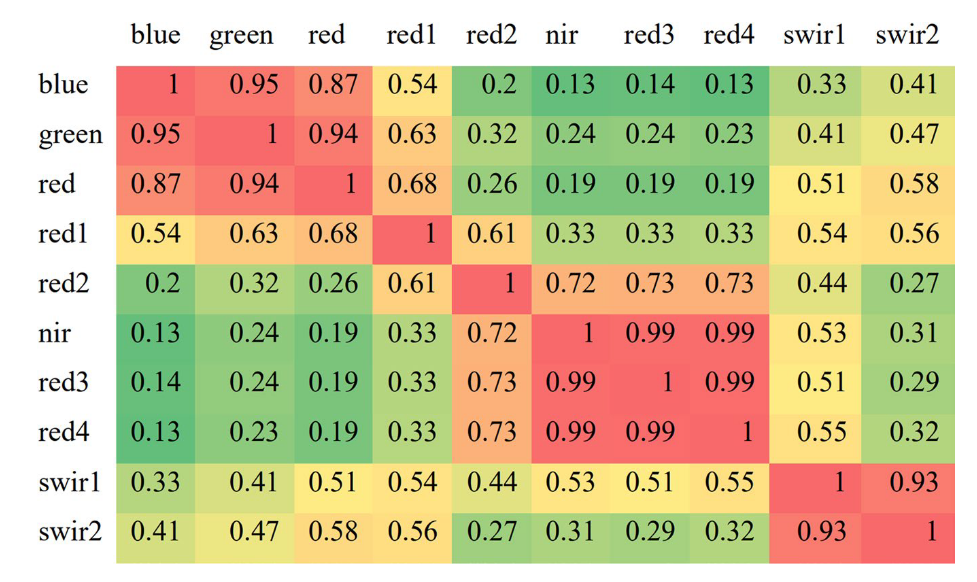
图3|S2影像各波段的Pearson相关分析
(2)第二步,本研究从2017 - 2021年五个玉米种植区收集了79255个地面真值标签。
表1|样本在华北地区的分布 字母(a)为华北玉米种植区,希腊数字表示不同的样本采集方法。
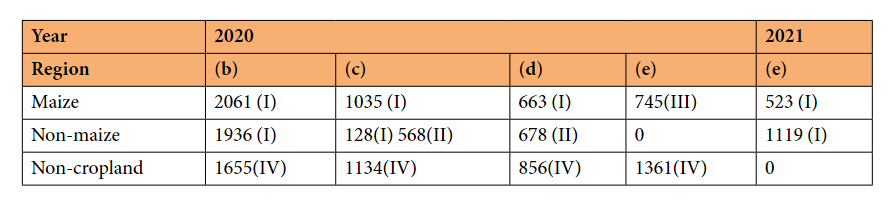
表2|样品在其他玉米种植区的分布,从(b)到(e)分别代表黄淮海、西南、甘肃省和新疆省的玉米种植区。
(3)第三步是模型选择和地图生成,针对不同的区域选择不同的机器学习模型,得到多年玉米种植分布产品。为了防止过拟合,对于有足够样本的种植区(a),本研究提出了一种基于深度学习的模型来识别植物。对于样本有限的其他区域(b、c、d、e区)的植物,采用特定区域的随机森林模型进行植物分类。所提出的基于深度学习的玉米制图方法流程图如图4所示。网络体系结构主要包括两个模块,即特征提取和分类模块。
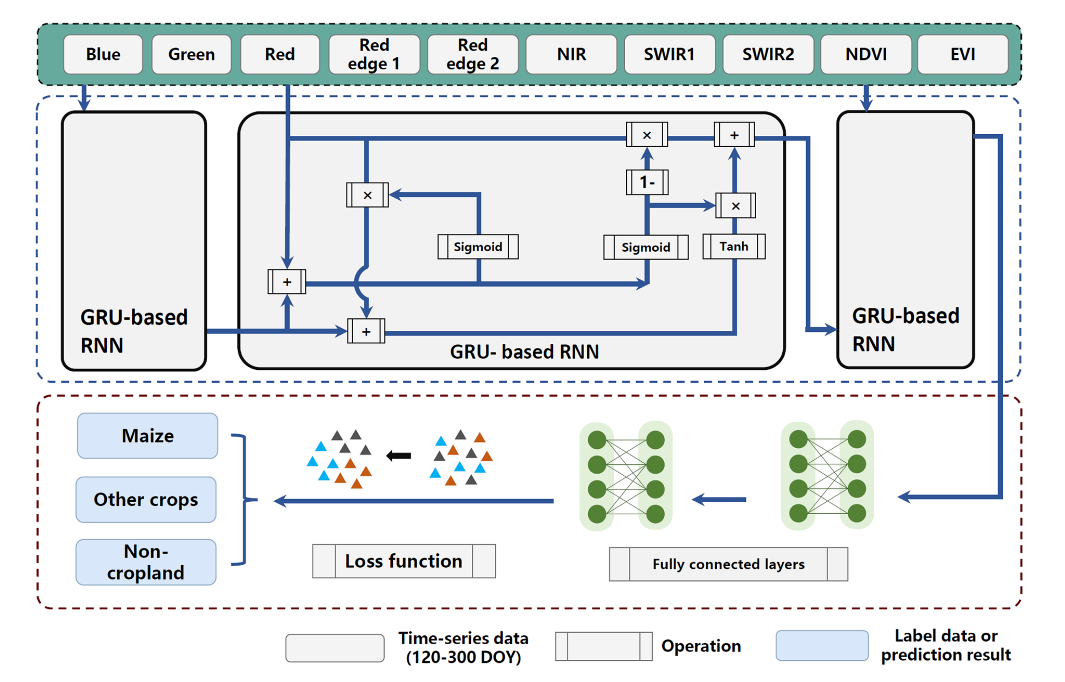
图4|在玉米制图框架中提出的深度学习模型。“+” 和“x”分别表示逐点加法和乘法。
(4)最后一步是后处理,通过半径为10m的圆形核多数滤波器去除斑点点,并用更粗分辨率的玉米图对玉米图进行掩膜处理。
4.研究结果
4.1 数据记录
本研究生成了2017-2021年中国玉米种植区5张10米玉米农田图。数据记录在figshare中共享,这是一个用于发布研究数据的在线开放存取存储库。由于10米分辨率产品比较大,按照行政区划代码(adcode)进行了分离保存。该数据集由145个文件组成。文件的命名格式为'[adcode]_[year].tif ' 。
4.2 方法验证
本研究从两个方面对生成的玉米图进行评价,即:(1)测试数据集的总体分类精度;(2)基于本文方法估算的玉米种植面积与统计年鉴中记录的玉米种植面积的一致性。
(1)对于每个玉米种植区,采用验证集中OA最高的模型对测试集中的标签进行预测。不同区域的测试集大小分别为7266(a)、1024(b)、910(c)、500(d)和532(e)。使用四个矩阵,包括用户精度、生产者精度、总体精度和kappa系数,来评估生成地图的精度。深度学习模型和随机森林模型的评价结果如表3所示。可以观察到,5个区域的OAs在0.83-0.95之间变化。
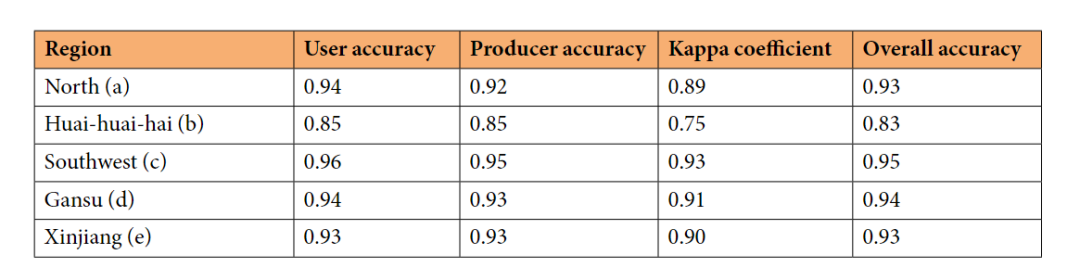
表3|各玉米产区模型性能总结。
由于训练和测试样本不是在同一年获得的,因此由于物候变化,拟议框架的性能可能在不同年份有所不同。为了验证所提出框架的稳健性,在拥有多年样本的区域(a)进行了实验。如表4所示,本研究从2017年、2018年、2019年中选取两年,其中一年的样本作为训练数据,另一年的样本作为测试数据验证模型的性能。预测的精度略有下降(平均总体精度为0.85),但仍保持了较好的精度,证明了所提出框架的可行性。
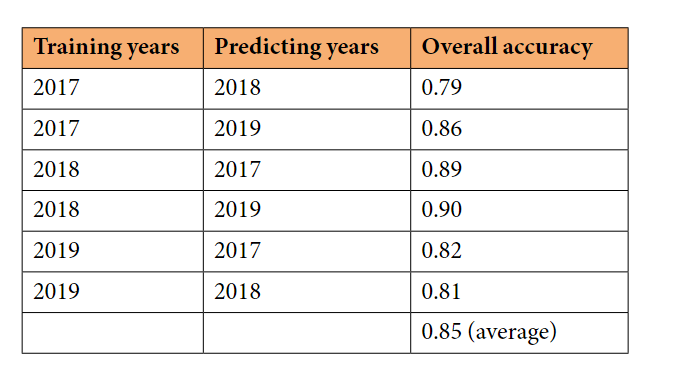
表4|使用不同年份的训练和测试数据集进行分类的准确性。
(2)为了进一步评价所提出的框架,将年度玉米分布图得出的玉米种植面积与2017 - 2021年统计年鉴记录的玉米种植面积进行了比较。特别地,本研究将年度地图在GEE平台上重新投影为WGS 1984 Albers for North-ern Asia (EPSG: 102025),以确保面积单位与年鉴一致。如图5所示,平均决定系数(R²)为0.91,2020年最高为0.95。这些发现表明本研究的产品与统计年鉴记录一致。2017 - 2021年玉米地图的空间细节如图6所示。可以观察到,中国南部和西北部省份的准确性较差,因为这些省份的样本点数量较少。在样本点较多的东北和黄淮海地区,精度较高。这表明不确定性的程度主要是由样本点的数量引起的,这是数据驱动模型的局限性。在未来,其研究计划通过结合数据驱动模型和机制驱动模型来改进该方法。
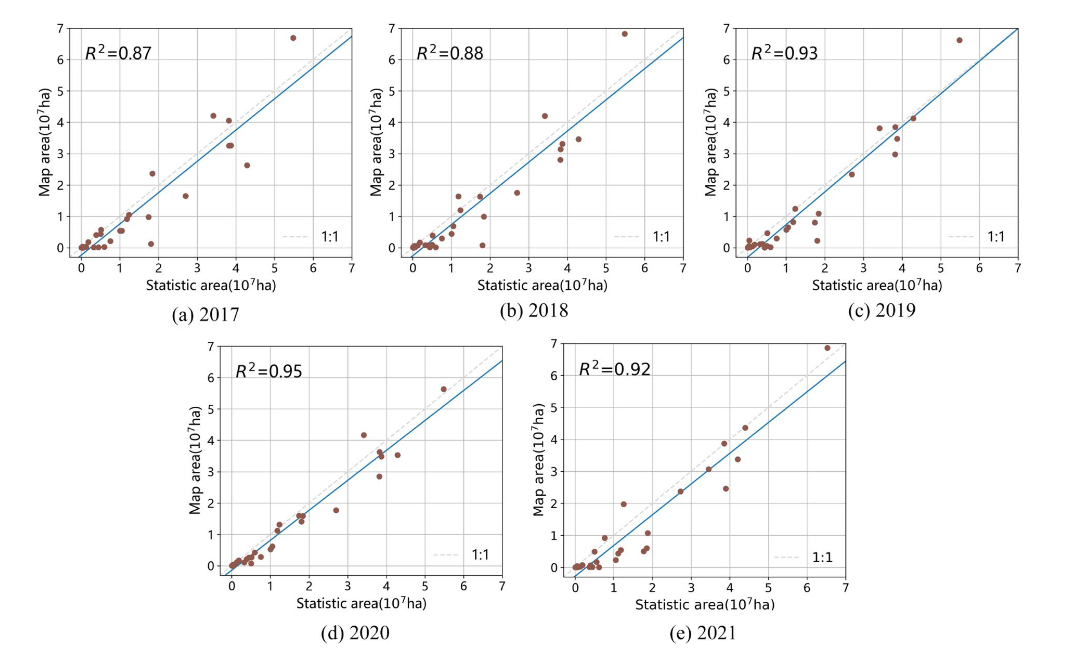
图5|2017年、2018年、2019年、2020年和2021年省级统计数据的玉米年图估算玉米种植面积。

图6 2017 - 2021年玉米地图空间细节。
5.文章相关代码和数据链接
5.1 代码链接
https://github.com/lixinang/ChinaMaizeCls
5.2 数据链接
https://doi.org/10.6084/m9.figshare .22689751.v17
6.文章引用
Li, X., Qu, Y., Geng, H. et al. Mapping annual 10-m maize cropland changes in China during 2017–2021. Sci Data 10, 765 (2023). https://doi.org/10.1038/s41597-023-02665-3
这篇关于【精读文献】Scientific data|2017-2021年中国10米玉米农田变化制图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








