本文主要是介绍有点意思!腾讯 ARC Lab 最新发布的MiraData数据集,用于长视频生成,从这些方面做了clip分层描述……,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近小编网上冲浪时,被腾讯 PCG ARC Lab 新开源的文本-视频数据集——MiraData 吸引了目光。

这个数据集有多新?Readme在一天前刚更新完的那种,而且数据集有一大特点,是专门为长视频生成任务设计的大规模视频数据集,不仅提供了时长更长的数据,还从视频主体、背景、风格等不同维度进行了非常详细的文本“分层”描述,关注视频生成的小伙伴不容错过!相信一定能给你启发,赶紧和小编一睹为快。
MiraData项目地址:https://github.com/mira-space/MiraData
一、数据集概览
视频数据集在sora等视频生成大模型中发挥着至关重要的作用。然而,现有的文本-视频数据集在处理长视频序列和捕获镜头过渡方面往往存在不足。为了解决这些限制,腾讯 PCG ARC Lab 研究人员引入了MiraData(Mi ni-So ra Data),这是一个专门为长视频生成任务设计的大规模视频数据集。

(MiraData 官方Demo Video截图,来源:https://www.youtube.com/watch?v=3G0p7Jo3GYM)
MiraData 的主要特点
1. 长视频时长:与以前的数据集不同,以前的数据集视频剪辑通常非常短(通常小于 6 秒),MiraData 专注于时长从 1 到 2 分钟不等的未剪辑视频片段。这种延长的持续时间允许对视频内容进行更全面的建模。
2. 结构化描述:MiraData 中的每个视频都附有结构化描述。这些标题从不同角度提供了详细描述,增强了数据集的丰富性。描述平均长度为349字,保证了视频内容的全面呈现。
数据集构成
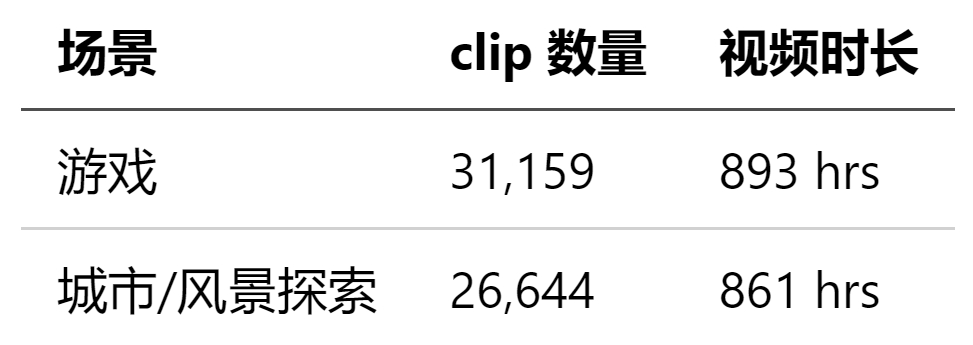
在这次初始发布的版本中,MiraData 包含 57,803 个视频片段,总时长 1,754 小时,主要提供游戏和城市/风景探索两个场景。clip数量和视频时长如下所示:
2种场景内容
● 游戏场景:包含了丰富的游戏体验相关视频;
● 城市或自然景观场景:通过视频捕捉了多样的城市风貌和自然美景。
6种类型的描述
MiraData 中的每个视频都附有结构化描述,从以下6种不同角度进行了详细地描述,增强了数据集的丰富性:
● 主体描述(Main Object Description):描述视频中的主要目标或主体,包括它们在整个视频中的属性、动作、位置和运动。
● 背景(Background):提供有关环境或场景的信息,包括物体、地点、天气和时间。
● 风格(Style):涵盖艺术风格、视觉和摄影方面,如写实、赛博朋克、电影风格。
● 摄像机运动(Camera Movement):详细说明摄像机的平移、变焦或其他运动。
● 简短描述(Short Caption):一段简洁的摘要,描述视频的精髓,使用Panda-70M字幕模型生成。
● 密集描述(Dense Caption):一个更详尽和详细的、总结了上述五种类型的描述。
举个“栗子”
看1个官方提供的例子,就明白了,比如这个游戏视频

(开头画面冲击力较强,注意谨慎观看)
描述内容有:
主体描述
从玩家的视角出发,最初与一个对手搏斗,这一点可以从机械部件和玩家手部的特写镜头中得到证实。随后,焦点转移到一位老年女性身上,她最初表现出攻击性或防御性,高举着铲子,好像随时准备出击。接着她转身,带领玩家绕到一个木制结构的侧面,那可能是她的家。随着时间的推移,她的态度变得柔和,看起来像是在和玩家交谈,因为她放下了手中的铲子,姿态变得更加放松。
背景描述
背景描绘了郁郁葱葱的乡村环境,有一座木屋或棚屋,周围环绕着绿色植物、岩石和红色花朵。环境具有自然主义的感觉,晴朗的天空和日光表明这是白天的环境。背景中没有可见的其他人物或移动元素,这表明这是一个虽然与世隔绝但平静的地点。
风格描述
视觉风格是现实主义的,具有详细的角色模型、自然光照以及高度的环境细节,共同营造出一个沉浸式且令人信服的乡村环境,适合于电子游戏的背景设定。
镜头描述
相机视角在整个序列中始终与第一人称视点保持一致。初始画面表明了一场动态的斗争,伴随着快速的动作,而随后的画面则显示了玩家与女性互动时更为稳定的相机。镜头跟随女人移动,将她保持为焦点,并且拍摄角度会随着玩家视角的变化而变化,以保持女人在视野中,特别是当她移动和转身时。
简短描述
一个电子游戏角色站在房子前面。
密集描述
该视频序列展示了视频游戏角色在乡村环境中与不可玩角色 (NPC) 互动的第一人称视角。最初,玩家角色似乎正在与敌人或生物搏斗,如特写斗争和火花或余烬的存在所示。场景切换到玩家角色站在一位老年妇女面前,她以防御或威胁的姿势挥舞着铲子。该女子的表情和姿势表明她对玩家持警惕或对抗态度。随着视频的进展,这名女子似乎稍微放松了一点,放下了铲子并与玩家交谈,这一点从她不断变化的面部表情和肢体语言可以看出。
二、数据采集与标注
为了收集MiraData,研究团队首先手动选择不同场景下的YouTube频道。然后,使用PySceneDetect下载并分割相应频道中的所有视频。之后,选择了时长在1到2分钟之间的视频片段。对于超过2分钟的视频片段,他们将其分成多个2分钟的片段。最后,使用 GPT-4V 为视频剪辑添加描述。
GPT-4V 描述
研究团队测试了现有的开源视觉LLM方法和GPT-4V,发现GPT-4V的描述在时间序列方面的语义理解上表现出更好的准确性和连贯性。它还可以更准确地描述主要主体和背景物体,减少物体遗漏和幻觉问题。因此,他们使用GPT-4V来生成密集描述、主体描述、背景描述、镜头描述和风格描述。
Panda-70M 描述
为了平衡标注成本和描述准确性,他们为每个视频统一采样 8 帧,并将它们排列成一张大图像的 2x4 网格。然后,使用Panda-70M的描述模型为每个视频添加一句话描述,作为主要内容的提示,并将其输入到他们的微调 prompt 中。
通过将微调的提示和 2x4 大图像输入 GPT-4V,他们可以在一轮对话中高效地输出多个维度的描述。具体提示内容可以在caption_gpt4v.py中找到,欢迎大家贡献更多优质的文字-视频数据。
caption_gpt4v.py链接:https://github.com/mira-space/MiraData/blob/main/caption_gpt4v.py
三、统计
数据集信息统计如下:
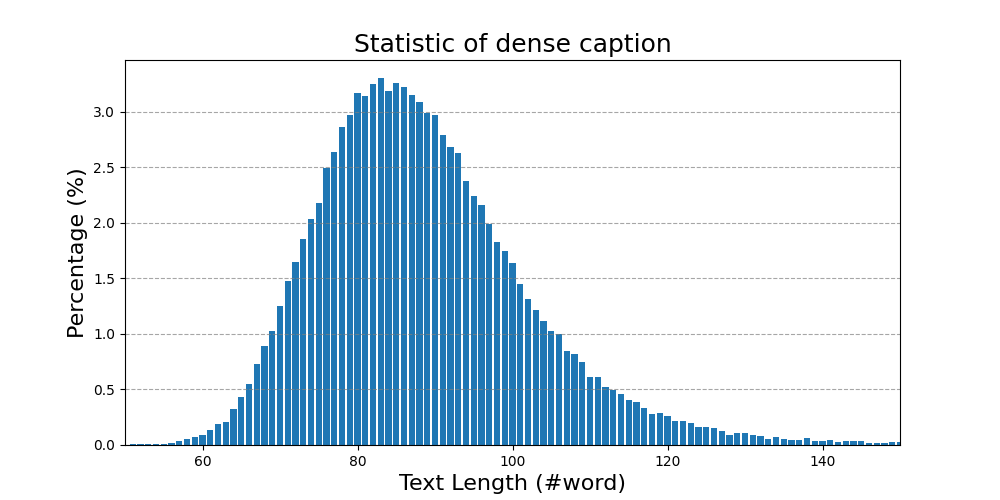
密集字幕的总文本长度统计
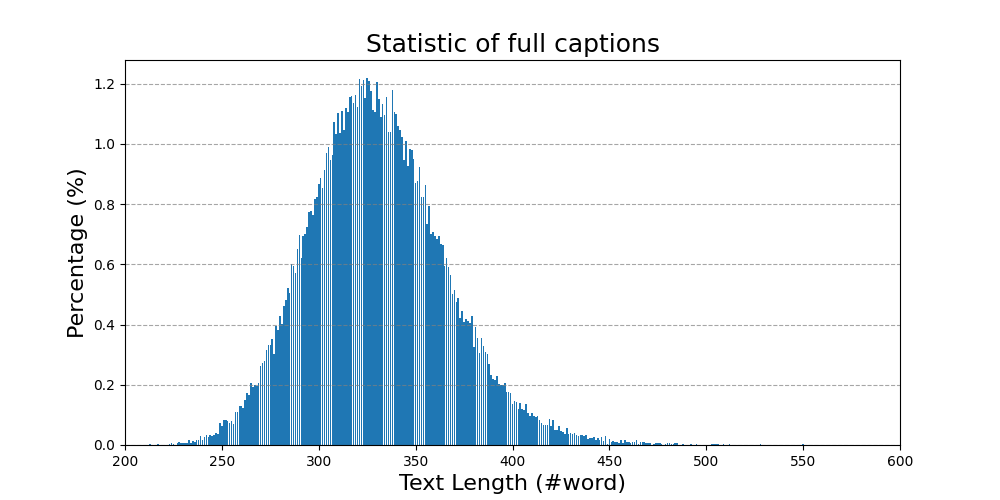
六种类型字幕的总文本长度统计
简短描述词云
密集描述的词云
四、数据集下载
作者提供的描述元文件,除了上述6种维度描述外,还提供了YouTube视频ID等相关信息:
● 元文件字段:
· index : 视频片段索引,由以下部分组成{download_idx}_{video_id}-{clip_id}
· video_id : YouTube 视频 ID
· start_frame : YouTube 视频的剪辑开始帧
· end_frame : YouTube 视频的剪辑结束帧
· main_object_caption:视频中主体描述
· background_caption : 视频背景描述
· style_caption:视频风格描述
· camera_caption : 镜头描述
· Short_caption:简短描述
· dend_caption:密集描述
· fps:用于提取帧的视频帧率
*你可以使用 start_frame/fps 或 end_frame/fps 获取开始和结束时间戳
另外,作者提供了视频下载并分割的脚本:
python download_data.py --meta_csv miradata_v0.csv --video_start_id 0 --video_end_id 10631 --raw_video_save_dir miradata/raw_video --clip_video_save_dir miradata/clip_video其中--video_start_id和表示要下载的元文件的--video_end_id开始值和结束值。游戏场景范围为0至7416,城市/风景探索范围为7417至10631。download_idxindex
更多数据集,请访问OpenDataLab:https://opendatalab.org.cn/
这篇关于有点意思!腾讯 ARC Lab 最新发布的MiraData数据集,用于长视频生成,从这些方面做了clip分层描述……的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








