本文主要是介绍深度特征合成与遗传特征生成,两种自动特征生成策略的比较,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:Deephub Imba
本文约1800字,建议阅读8分钟
本文我们将通过一个示例介绍如何使用 ATOM 包来快速比较两种自动特征生成算法。特征工程是从现有特征创建新特征的过程,通过特征工程可以捕获原始特征不具有的与目标列的额外关系。这个过程对于提高机器学习算法的性能非常重要。尽管当数据科学家将特定的领域知识应用特定的转换时,特征工程效果最好,但有一些方法可以以自动化的方式完成,而无需先验领域知识。
在本文中,我们将通过一个示例介绍如何使用 ATOM 包来快速比较两种自动特征生成算法:深度特征合成 (Deep feature Synthesis, DFS) 和遗传特征生成 (Genetic feature generation, GFG)。ATOM 是一个开源 Python 包,可以帮助数据科学家加快对机器学习管道的探索。
基线模型
为了进行对比,作为对比的基线只使用初始特征来训练模型。这里使用的数据是来自 Kaggle的澳大利亚天气数据集的变体。该数据集的目标是预测明天是否会下雨,在目标列 RainTomorrow 上训练一个二元分类器。
import pandas as pd
from atom import ATOMClassifier# Load the data and have a look
X = pd.read_csv("./datasets/weatherAUS.csv")
X.head()
初始化实例并准备建模数据。这里仅使用数据集的一个子集(1000 行)进行演示。下面的代码估算缺失值并对分类特征进行编码。
atom = ATOMClassifier(X, y="RainTomorrow", n_rows=1e3, verbose=2)
atom.impute()
atom.encode()输出如下所示。
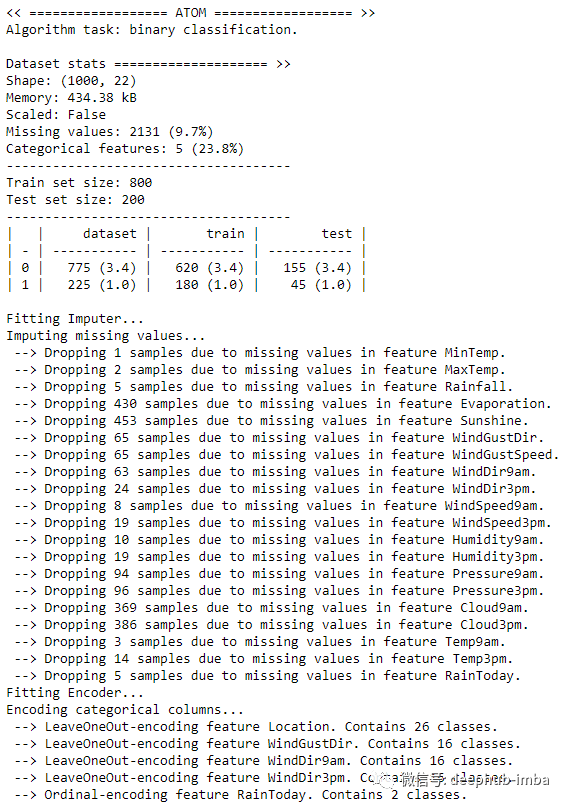
可以使用 dataset 属性快速检查数据转换后的样子。
atom.dataset.head()
数据现在已准备好。本文将使用 LightGBM 模型进行预测。使用 atom 训练和评估模型非常简单:
atom.run(models="LGB", metric="accuracy")
可以看到测试集上达到了 0.8471 的准确率。下面看看自动特征生成是否可以改善这一点。
DFS
DFS 将标准数学运算符(加法、减法、乘法等)应用于现有特征,并组合这些特征。例如,在我们的数据集上,DFS 可以创建新特征 MinTemp + MaxTemp 或 WindDir9am x WindDir3pm。
为了能够比较模型,需要为 DFS 管道创建了一个新分支。如果你不熟悉 ATOM 的分支系统,请查看官方文档。
atom.branch = "dfs"使用 atom 的 feature_generation 方法在新分支上运行 DFS。为了起见,这里只使用加法和乘法创建新特征(使用 div、log 或 sqrt 运算符可能会返回具有 inf 或 nan 值的特征,所以还需要再次进行处理)。
atom.feature_generation(strategy="dfs",n_features=10,operators=["add", "mul"],
)ATOM 是使用 featuretools 包来运行 DFS的 。这里使用了 n_features=10,因此从所有可能的组合中随机选择的十个特征被添加到数据集中。
atom.dataset.head()
再次训练模型:
atom.run(models="LGB_dfs")需要注意的是
在模型的首字母缩写词后添加标签 _dfs 以不覆盖基线模型。
不再需要指定用于验证的指标。atom 实例将自动使用任何先前模型训练的相同指标。在我们的例子中为accuracy。

看起来 DFS 并没有改进模型。结果甚至变得更糟了。让我们看看 GFG 的表现如何。
GFG
GFG 使用遗传编程(进化编程的一个分支)来确定哪些特征是有效的并基于这些特征创建新特征。与 DFS的盲目尝试特征组合不同,GFG 尝试在每一代算法中改进其特征。GFG 使用与 DFS 相同的运算符,但不是只应用一次转换,而是进一步发展它们,创建特征组合的嵌套结构。在使用运算符 add (+) 和 mul (x),特征组合的方式可能是:
add(add(mul(MinTemp, WindDir3pm), Pressure3pm), mul(MaxTemp, MinTemp))
在使用时与 DFS 一样,首先创建一个新分支(从原始 master 分支将 DFS 排除),然后训练和评估模型。同样,这里创建了 10 个新特征。
注意:ATOM 在底层使用 gplearn 包来运行 GFG。
atom.branch = "gfg_from_master"
atom.feature_generation(strategy="GFG",n_features=10,operators=["add", "mul"],
)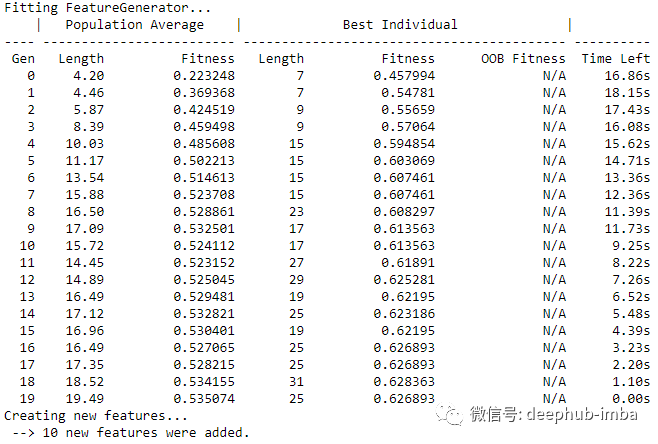
可以通过 generic_features 属性访问新生成的特征、它们的名称和适应度(在遗传算法期间获得的分数)的概述。
atom.genetic_features
这里需要注意的是,由于特征的描述可能会变得很长(看上图),因此将新特征将被编号命名为例如feature n,其中 n 代表数据集中的第 n 个特征。
atom.dataset.head()
再次运行模型:
atom.run(models="LGB_gfg")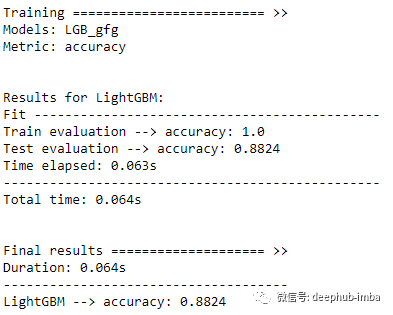
这次得到了 0.8824 的准确率,比基线模型的 0.8471 好得多!
结果分析
所有三个模型都已训练完毕可以分析结果了。使用 results 属性可以查看所有模型在训练集和测试集上的得分。
atom.results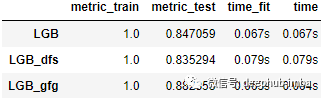
使用 atom 的 plot 方法可以进一步比较模型的特征和性能。
atom.plot_roc()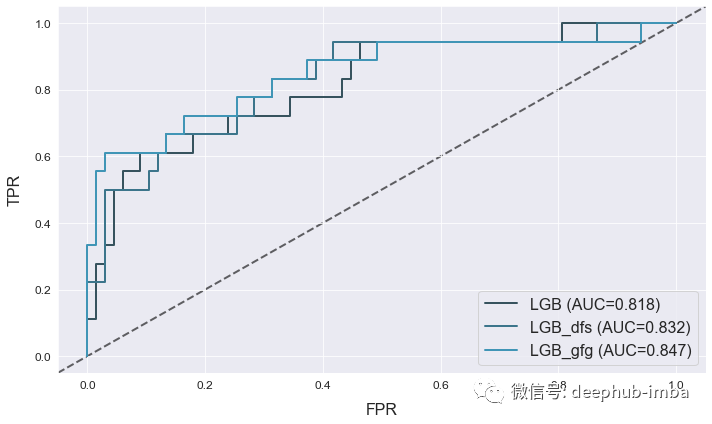
使用 atom 可以绘制多个相邻的图,查看哪些特征对模型的预测贡献最大
with atom.canvas(1, 3, figsize=(20, 8)):atom.lgb.plot_feature_importance(show=10, title="LGB")atom.lgb_dfs.plot_feature_importance(show=10, title="LGB + DFS")atom.lgb_gfg.plot_feature_importance(show=10, title="LGB + GFG")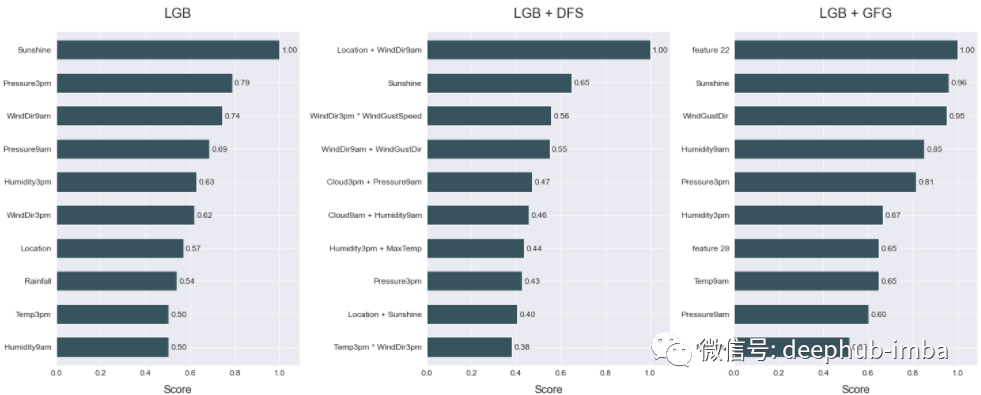
对于两个非基线模型,生成的特征似乎是都最重要的特征,这表明新特征与目标列相关,并且它们对模型的预测做出了重大贡献。
使用决策图,还可以查看特征对数据集中单个行的影响。
atom.lgb_dfs.decision_plot(index=0, show=15)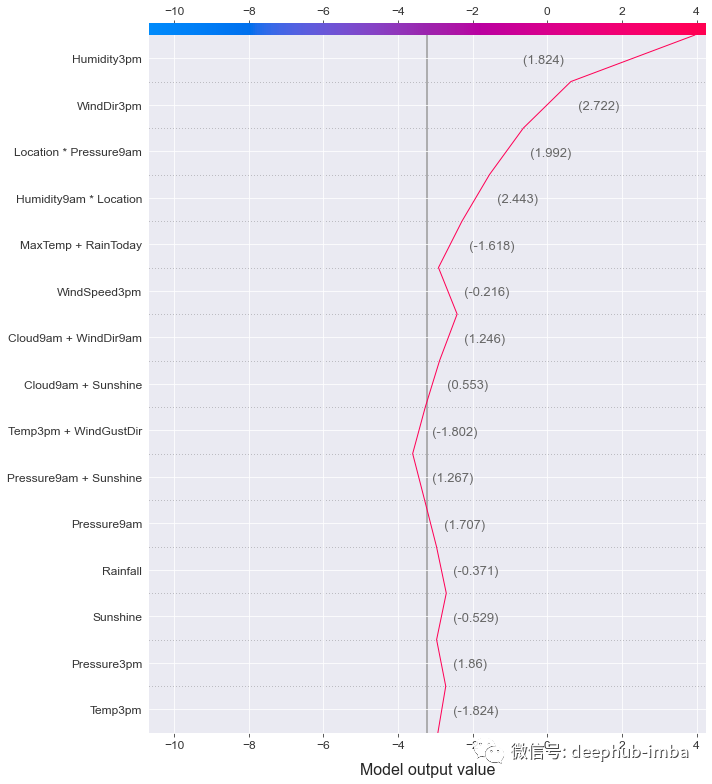
总结
本文中比较了在使用两种自动特征生成技术生成的新特征对于模型预测的表现。结果显示使用这些技术可以显着提高模型的性能。本文中使用了ATOM包简化处理训练和建模流程,有关 ATOM 的更多信息,请查看包的文档。
ATOM的github地址:
https://github.com/tvdboom/ATOM
使用的kaggle数据集地址:
https://www.kaggle.com/jsphyg/weather-dataset-rattle-package
编辑:王菁

这篇关于深度特征合成与遗传特征生成,两种自动特征生成策略的比较的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


