本文主要是介绍Python数据分析案例39——电商直播间评论可视化分析(LDA),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 引言
1.1 直播电商的发展背景
随着互联网技术的飞速发展,电商行业迎来了新的变革——直播电商。直播电商是一种结合了直播技术和电子商务的新型销售模式。在这种模式下,商家或主播通过实时视频直播的方式,展示产品并与消费者互动,促进产品销售。这种新兴的电商形式因其独特的互动性和即时性,在短时间内迅速发展并受到了消费者的广泛欢迎。
1.2 研究的重要性与目的
直播电商的快速发展不仅改变了传统的购物方式,也带来了新的数据分析需求。在这种模式下,消费者的互动行为成为了重要的数据来源,能够反映出消费者的兴趣偏好和购物行为。对这些互动数据进行深入分析,有助于商家更好地理解消费者需求,优化产品推荐,提高销售效率。本研究旨在通过对直播间内消费者评论数据的挖掘,探索消费者行为模式和兴趣偏好特征,为直播电商的发展提供数据支持。
2. 直播电商与传统电商的比较分析
2.1 传统电商的特点
传统电商,如在线商城和电子商务平台,主要通过图片、文字和视频等形式展示产品信息。消费者在这些平台上浏览商品信息,根据自己的需要进行选择和购买。传统电商的优势在于产品种类丰富、购物便捷、价格透明。然而,这种模式通常缺乏即时的互动和个性化的购物体验。
2.2 直播电商的特点
与传统电商相比,直播电商具有以下几个显著特点:
互动性强:主播可以实时回答消费者的问题,提供即时的购买建议,增强了消费者的购物体验。
真实性高:产品通过直播的形式展示,消费者可以更直观地了解产品的实际效果。
娱乐性:直播通常结合了娱乐元素,如主播的互动和表演,使购物过程更加轻松愉快。
即时性:直播电商能够实时推送优惠信息和限时折扣,刺激消费者的购买欲望。
2.3 社交互动在直播电商中的作用
社交互动是直播电商区别于传统电商的一个关键因素。在直播过程中,消费者不仅可以与主播互动,还可以与其他观众进行讨论和交流。这种互动性增强了消费者的参与感和归属感,对提高消费者的购买意愿和忠诚度具有重要影响。同时,通过分析消费者的互动行为,商家可以更准确地把握市场趋势和消费者需求,从而进行更有效的产品推广和销售策略调整。
3. 研究方法与数据处理
3.1 研究框架设定
本研究旨在通过分析直播间的实时评论数据,深入探索消费者行为模式和兴趣偏好。研究主要关注于从评论数据中提取有效信息,如情感倾向、主题趋势以及评论互动特性,并将这些信息与成交数据相结合,以揭示消费者行为与直播间销售效果之间的关系。
3.2 数据集描述
数据集包括2023年9月期间两个直播间(RoomJ和RoomL)的40场次直播的实时评论与成交数据。数据粒度为分钟级。收集的数据变量主要包括:
(ps:本次代码演示只选取RoomJ这一个直播间,完整的全部代码文件和数据集获取可以参考:电商直播间评论)
| live_room_id | 直播间ID |
| time | 记录的时间点 |
| live_comment | 直播评论内容 |
| ONLINE_USER_CNT | 在线用户数量 |
| follow_anchor_ucnt | 关注主播的用户数量 |
| fans_club_join_ucnt | 加入粉丝团的用户数量 |
| pay_combo_cnt | 成交件数 |
| pay_ucnt | 成交人数 |
| pay_amt | 成交金额 |
3.3 数据预处理过程和思路
数据预处理包括清理无效或不完整的评论数据,标准化时间格式,并对评论内容进行解析和处理。为了准确分析评论内容,将使用自然语言处理技术提取关键信息,如情感倾向和评论主题。
主要思路是对数据集里面的live_comment进行解析和计算。获取里面的用户名称,用户ID和评论内容,然后计算不同时间点的评论数量,评论文本长度,评论的情感值。不同时间的趋势进行数据可视化。对主题进行分析,对文本进行情感分析,和LDA建模划分不同的话题进行可视化分析。
全文使用python代码和其第三方工具库,例如pandas处理数据,matplotlib进行可视化,snownlp进行自然语言处理等对评论文本进行操作和分析。
(本文演示的所有代码文件和数据集获取参考:电商直播间评论)
4. 数据分析代码实现
4.1读取数据
导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import json
from snownlp import SnowNLP
from wordcloud import WordCloud
import jieba
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号读取数据,过滤没名称的列:
data = pd.read_csv('./本科生课设数据/RoomJ.csv',parse_dates=['time']).set_index('time')
data = data.loc[:, ~data.columns.str.contains('Unnamed')]
data.head(3)
第一列是直播间编号,应该都是一样的,live_comment就是我们需要的评论文本,是列表嵌套字典的结构,需要提取出来。列表里面的不同元素代表不同的用户的评论,字典代表这条评论的信息:即文本内容,评论时间,评论的id等等。
4.2数量分析
首先自定义一个函数,从live_comment提取所有的评论
def parse_comments(comments):parsed_comments = []for comment in comments:try:# Parse the JSON stringcomment_list = json.loads(comment.replace("'", "\""))for c in comment_list:# Extract relevant informationif c['nick_name'] != 'None' and c['content'] != 'None':parsed_comments.append({'nick_name': c['nick_name'],'msg_id': c['msg_id'],'content': c['content']})except json.JSONDecodeError:continue # Skip if JSON is not properly formattedreturn pd.DataFrame(parsed_comments)parsed_comment_df = parse_comments(data['live_comment'])
parsed_comment_df.head() 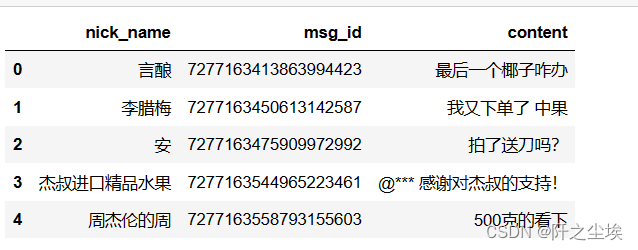
看到里面有一些椰子,水果之类的名称和评论文本,推测这应该是一个卖水果的直播间。
查看不同id发的评论数量可视化:
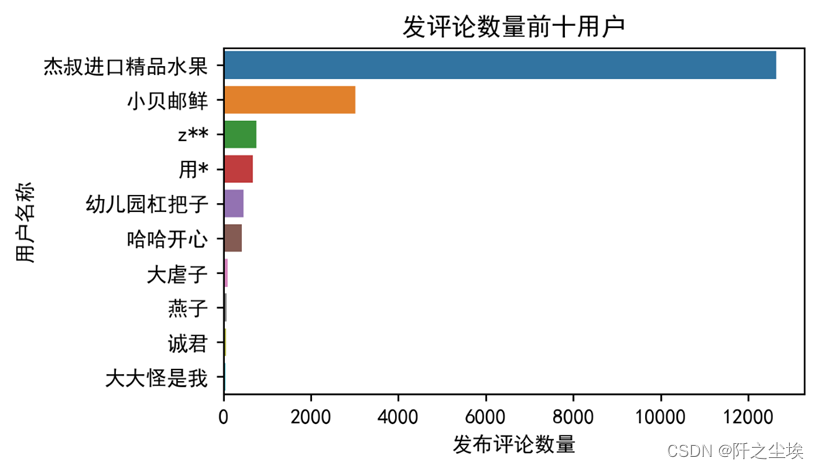
我们可以清晰地看到,杰叔进口精品水果这个用户发布评论最多,还有小贝邮鲜,猜测这个是他们这个直播间的官方运营账号。查看杰叔进口精品的评论大多如下:
| @*** 感谢对杰叔的支持! |
@L*** 发顺丰 大部分城市隔天到 |
@片*** 感谢对杰叔的支持! |
@z*** 发顺丰 大部分城市隔天到 |
@小*** 感谢对杰叔的支持! |
这样验证了我们的猜测,这是卖家官方运营的直播回复账号,所以文本会出现很多‘杰叔,’‘顺丰’之类的词汇。
所以我们排除了官方的账号的评论,然后简单统计一下哪些用户发的评论多:
top_two_names = parsed_comment_df['nick_name'].value_counts().nlargest(2).index
parsed_comment_df = parsed_comment_df[~parsed_comment_df['nick_name'].isin(top_two_names)].reset_index(drop=True)
parsed_comment_df['nick_name'].value_counts()
计算一下这个数据涵盖了多少天的评论:
total_days = (data.index.max() - data.index.min()).days
total_days
计算数量:
#1.评论数量
comment_count = len(parsed_comment_df)
# 2. 评论人数
unique_commenters_count = parsed_comment_df['nick_name'].nunique()
# 3. 平均长度
average_comment_length = parsed_comment_df['content'].apply(len).mean()
comment_count, unique_commenters_count, average_comment_length
计算一下每天平均数量
print(f'平均每天评论数量{comment_count/total_days:.2f}')
print(f'平均每天评论人数{unique_commenters_count/total_days:.2f}') 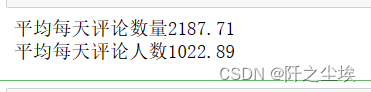
可以看到计算出来该J直播间这个时间段总共有761256条评论,参加评论的人数是28641条,每条评论的平均长度是6.48个文字。该时间段内平均每天评论数量2287条,平均每天评论人数1023人,表现出该直播间人气旺盛,直播观看人数较多,每天互动人数也多。
找出前10 的评论用户已经对应的评论数量:
top_nick_names=parsed_comment_df['nick_name'].value_counts()[:10]
top_nick_names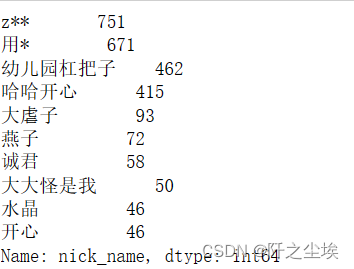
可视化:
# 使用 seaborn 绘制水平条形图
plt.figure(figsize=(5, 3),dpi=256)
sns.barplot(x=top_nick_names.values, y=top_nick_names.index)
plt.title('发评论数量前十用户')
plt.xlabel('发布评论数量')
plt.ylabel('用户名称')
plt.show()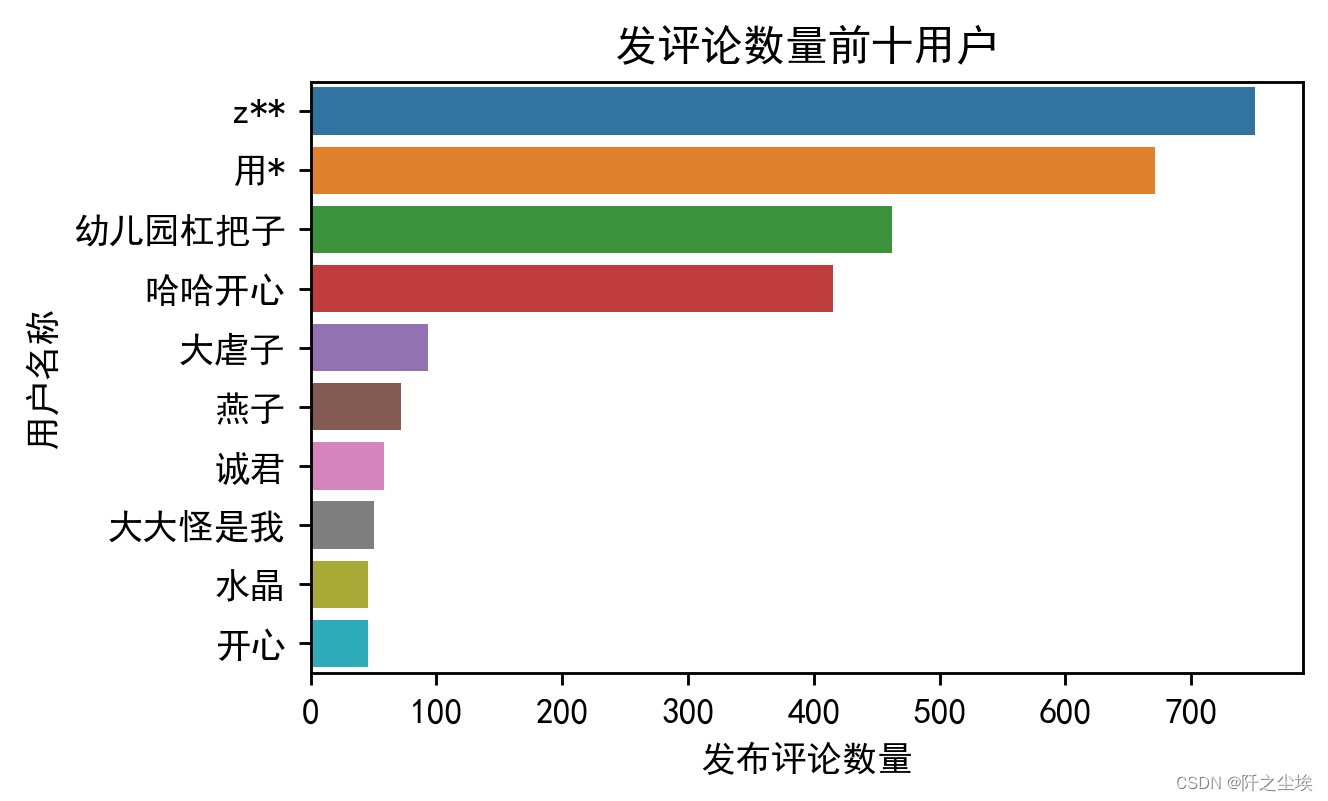
下面自定义一个函数,从评论中抽取了新的三个特征值,分别是comment_count代表该时间点的评论数量,该时间点的评论平均长度是avg_comment_length,最后是该时间点的评论的情感系数值sentiment,这个值处于0-1之间,越靠近1表示这段文本越正面。0.4-0.6附近则为中性。
# Define a function to parse the live_comment column
def parse_comments(comments_str):try:comments = json.loads(comments_str.replace("'", "\""))if comments == [{'nick_name': 'None', 'msg_id': 'None', 'content':'None'}]:return [], 0, 0,'无'else:comment_texts = [comment['content'] for comment in comments if comment['content'] != 'None']comment_count = len(comment_texts)total_length = sum(len(comment) for comment in comment_texts)avg_length = total_length / comment_count if comment_count > 0 else 0all_text = ' '.join(comment_texts)return comment_texts, comment_count, avg_length, all_textexcept json.JSONDecodeError:return [], 0, 0, "无"# Apply the function to each row in the dataframe
data['parsed_comments'], data['comment_count'], data['avg_comment_length'], data['all_comments_text'] = zip(*data['live_comment'].apply(parse_comments))
data['sentiment'] = data['all_comments_text'].apply(lambda x: SnowNLP(x).sentiments)
data['open'] = data['live_comment'].astype('str').apply(lambda x: 1 if "杰叔进口精品水果" in x else 0)查看一下:
data.tail(3)
每天的的评论数量,平均文本长度,评论情感值进行描述性统计如下:
data.resample('D').mean().describe().iloc[:,-4:]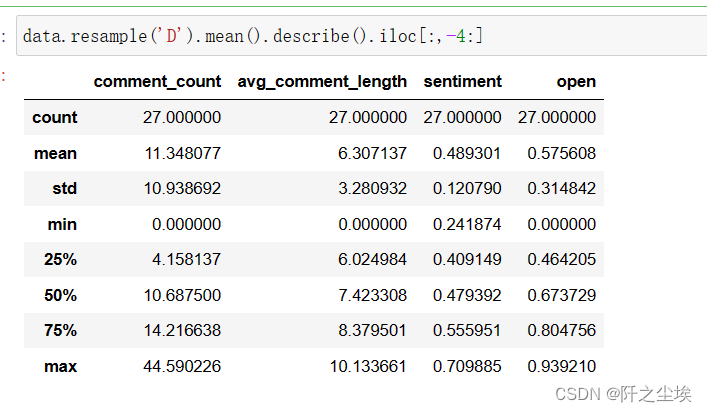
评论数量 (comment_count): 平均值为11.35,表明在一个给定的时间点,直播间大约有11条评论。最大值为44.59,表明在某些高峰时段,评论数量会显著增加。标准差为10.94,说明评论数量在不同时间点间有较大的波动,可能反映了直播内容的吸引力或观众参与度的变化。
评论平均长度 (avg_comment_length): 平均长度为6.31个字,表示观众的评论倾向于简短。最长的平均评论长度为10.13个字,表明在某些时刻,观众愿意更详细地表达自己的观点。这个指标的标准差为3.28,显示出评论长度的差异性。
评论的情感系数值 (sentiment): 平均值为0.49,接近0.5,表明总体上评论的情感倾向是中性的。情感系数值的范围从0.24到0.71,显示出从偏消极到偏积极的情感波动。这可能与直播内容的性质和观众的反应有关。
4.3趋势分析
将数据重采样为每小时的评论数量,进行可视化如图:
resampled_data = data.resample('H').mean().fillna(method='ffill').asfreq('H', method='ffill')
# 设置画布和子图
fig, axes = plt.subplots(3, 1, figsize=(8, 7),dpi=256)
# 为每个变量绘制折线图
sns.lineplot(ax=axes[0], data=resampled_data['comment_count'])
axes[0].set_title('每小时评论数量')
axes[0].tick_params(axis='x', labelsize=7,rotation=20) sns.lineplot(ax=axes[1], data=resampled_data['avg_comment_length'])
axes[1].set_title('每小时评论平均长度')
axes[1].tick_params(axis='x', labelsize=7,rotation=20) sns.lineplot(ax=axes[2], data=resampled_data['sentiment'])
axes[2].set_title('每小时的文本情感值')
axes[2].tick_params(axis='x', labelsize=7,rotation=20) # 调整子图间距
plt.tight_layout()# 显示图表
plt.show()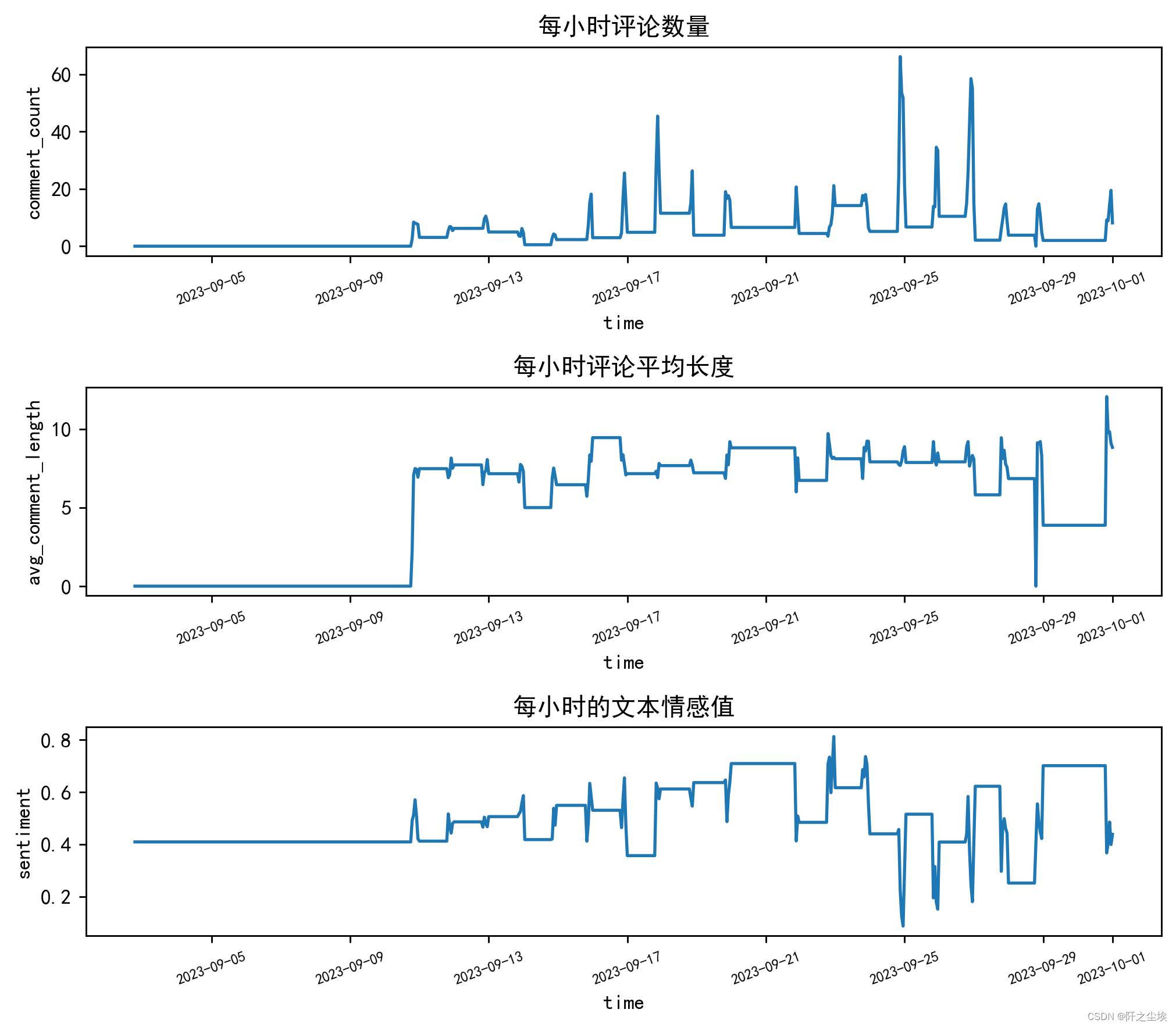
评论数量分布图分析,此图表显示了在一定时间内评论数量的变化。可以看出,评论数量刚开始未开播的时候都是0没有变化,后面有几个高峰期,这可能表明在这些时段内进行了特别的活动或促销,或者是某个热门产品的推出,引起了观众的高度互动。
这些高峰期的具体日期和时间,可能是直播活动导致的观众活跃度最高的时段,可以看到高峰时期,平均每一分钟就有50条以上的评论数量,反映了直播和观众们高频的互动和体验。可以从直播的行为得到相应的结论从而为未来的直播安排和促销活动提供数据支持。
平均评论长度此图表反映了观众在评论中投入的努力程度,可以间接反映观众对直播内容的投入和参与度。较长的评论可能意味着观众更加投入,可能是对直播内容有较强烈的反应。没开播的时候评论长度都是0,而一般的时候评论长度都是5-10个汉字之间。
注意到在某些时间点,平均评论长度有显著的下降,这可能是直播内容较为单一或不够吸引人时的表现,也可能是直播时段选择不佳,导致观众参与度不高。
评论情感分布图,这个图表显示了评论情感的波动,通常用于衡量观众对直播内容的正面或负面反应。值越高,表示评论中的正面情感越多;值越低,则可能包含更多的负面情感或者是中性评论。当情感值为0.4附近时是代表中性评论,可以发现情感分数在整个时间序列中,前段时间没开播时平稳,后续开播互动中波动较大,这可能与直播内容、直播主持人的互动方式,或者是观众期望与实际体验之间的差异有关。
对不同时间段的评论数量长度和情感值进行可视化,如下:
# 按每三小时分组
grouped_data = resampled_data.groupby(resampled_data.index.hour // 3).mean()
time_labels = [f'{i*3}-{i*3+3}点' for i in range(8)]
# 重新索引 grouped_data
grouped_data.index = time_labels
# 绘制饼图
fig, ax = plt.subplots(1, 3, figsize=(12, 6),dpi=128)ax[0].pie(grouped_data['comment_count'], labels=grouped_data.index, autopct='%1.1f%%')
ax[0].set_title('不同时间点的评论数量')# 第二个饼图:avg_comment_length 的平均值
ax[1].pie(grouped_data['avg_comment_length'], labels=grouped_data.index, autopct='%1.1f%%')
ax[1].set_title('不同时间点的评论平均长度')ax[2].pie(grouped_data['sentiment'], labels=grouped_data.index, autopct='%1.1f%%')
ax[2].set_title('不同时间点的评论情感值')plt.show()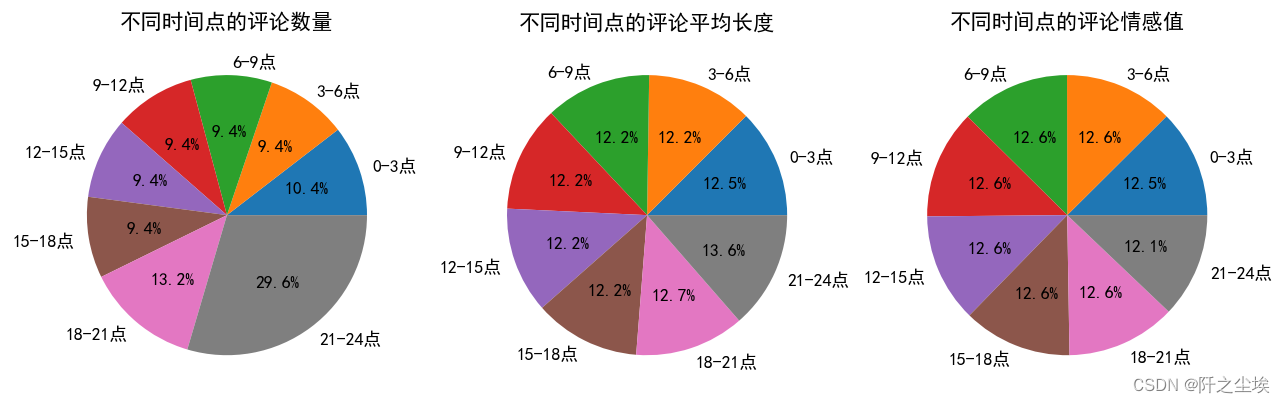
第一个饼图,这张图表显示的是不同时间点的评论数量,可能也反映了是用户在直播间的活跃时间分布。最大的部分是在21-24时,占了29.6%,这表明晚上是用户活跃度最高的时间段。其次是18-21时的部分,占了13.2%,表明晚上的用户参与度明显高于白天。
第二个饼图,第二个图表表示不同时间的评论长度,分布更为均匀,没有一个区域明显大于其他区域,这可能表明评论文本的长度与时间关联不大,或者用户的参与类型更为多样化。
第三个饼图在这个图表中表示不同时间段的情感值分布,没有明显的大块区域,这表示分布相对均匀。这可能表示户的留言或分享行为分布的情绪与时间的关系不是非常大。
对提取的每天的评论数量,每天评论平均长度,文本情感值进行时间折线图的可视化。
resampled_data = data.resample('D').mean().fillna(method='ffill').asfreq('D', method='ffill')
# 设置画布和子图
fig, axes = plt.subplots(3, 1, figsize=(8, 7),dpi=256)
# 为每个变量绘制折线图
sns.lineplot(ax=axes[0], data=resampled_data['comment_count'])
axes[0].set_title('每天评论数量')
axes[0].tick_params(axis='x', labelsize=7,rotation=20) sns.lineplot(ax=axes[1], data=resampled_data['avg_comment_length'])
axes[1].set_title('每天评论平均长度')
axes[1].tick_params(axis='x', labelsize=7,rotation=20) sns.lineplot(ax=axes[2], data=resampled_data['sentiment'])
axes[2].set_title('每天的文本情感值')
axes[2].tick_params(axis='x', labelsize=7,rotation=20) # 调整子图间距
plt.tight_layout()# 显示图表
plt.show() 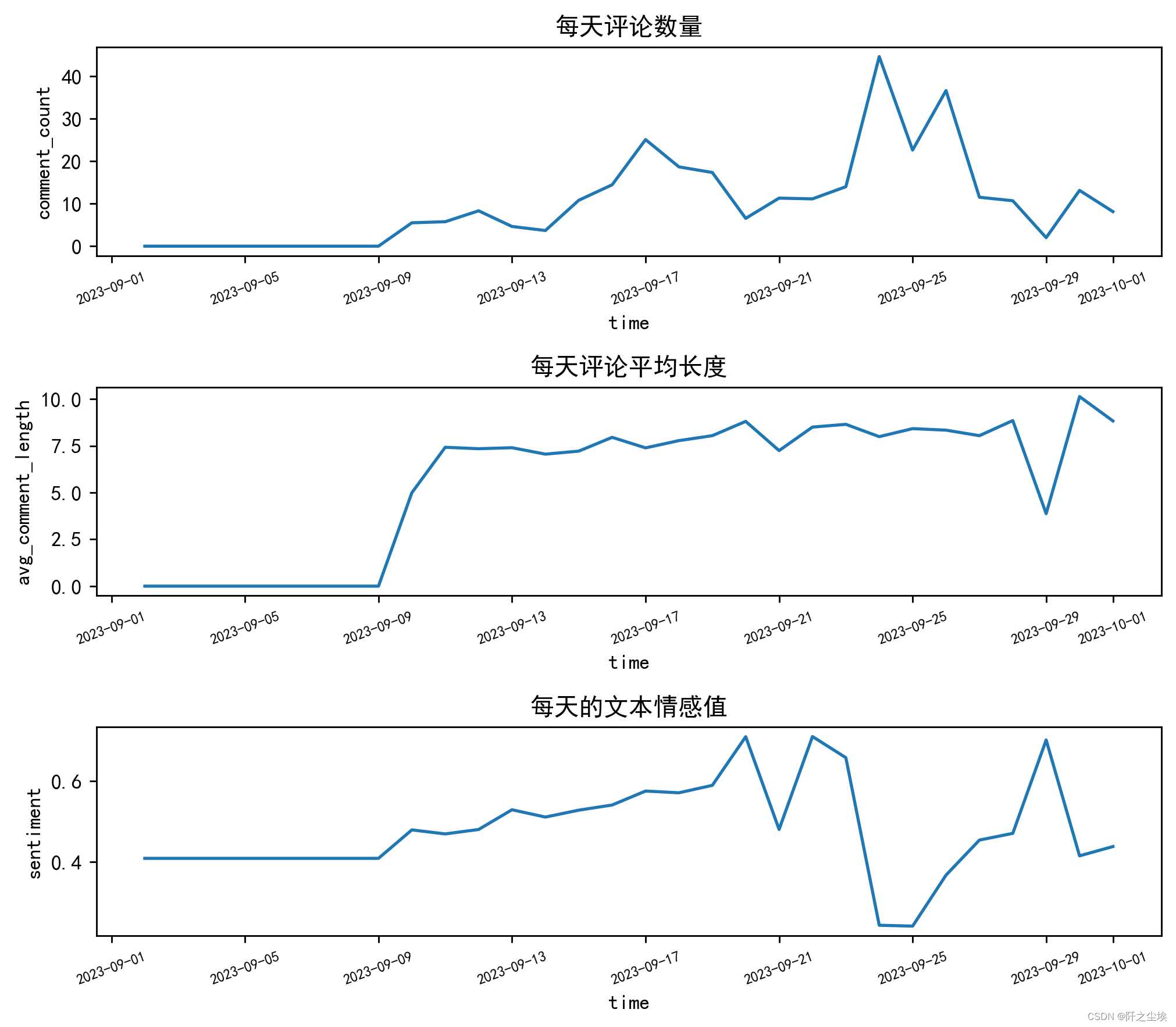
就不写那么多分析了,对应的核密度图为:
# 设置画布和子图
fig, axes = plt.subplots(3, 1, figsize=(4,5), dpi=168)# 为每个变量绘制核密度图
sns.kdeplot(ax=axes[0], data=resampled_data['comment_count'], fill=True)
axes[0].set_title('评论数量核密度图')
axes[0].tick_params(axis='x', labelsize=7, rotation=0)
axes[0].set_xlabel('')
sns.kdeplot(ax=axes[1], data=resampled_data['avg_comment_length'], fill=True)
axes[1].set_title('评论平均长度核密度图')
axes[1].tick_params(axis='x', labelsize=7, rotation=0)
axes[1].set_xlabel('')
sns.kdeplot(ax=axes[2], data=resampled_data['sentiment'],fill=True)
axes[2].set_title('文本情感值核密度图')
axes[2].tick_params(axis='x', labelsize=7, rotation=0)
axes[2].set_xlabel('')
# 调整子图间距
plt.tight_layout()# 显示图表
plt.show()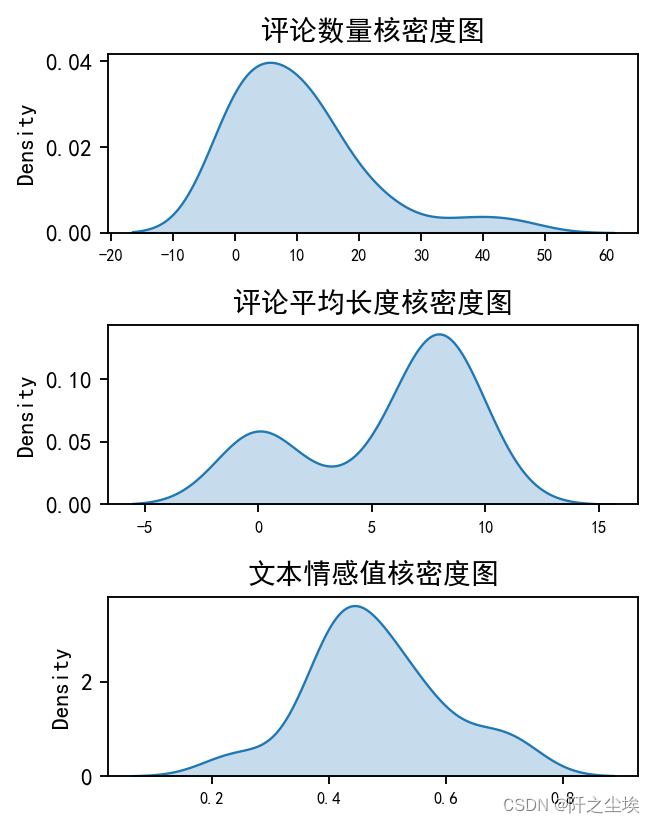
4.4内容分析
首先我们对评论采用snownlp库进行情感分析,对评论都打上情感系数的具体取值,然后进行分析:
# Calculating sentiment score for each comment
parsed_comment_df['sentiment'] = parsed_comment_df['content'].apply(lambda x: SnowNLP(x).sentiments)对所有的评论的情感值画出其分布的直方图,如下:
# Plotting the sentiment scores
plt.figure(figsize=(7, 4),dpi=128)
sns.histplot(parsed_comment_df['sentiment'], bins=50, color='lightblue', alpha=0.5, kde=False)
plt.title('评论的情感分数分布直方图')
plt.xlabel('情感分数')
plt.ylabel('评论数量')
plt.show()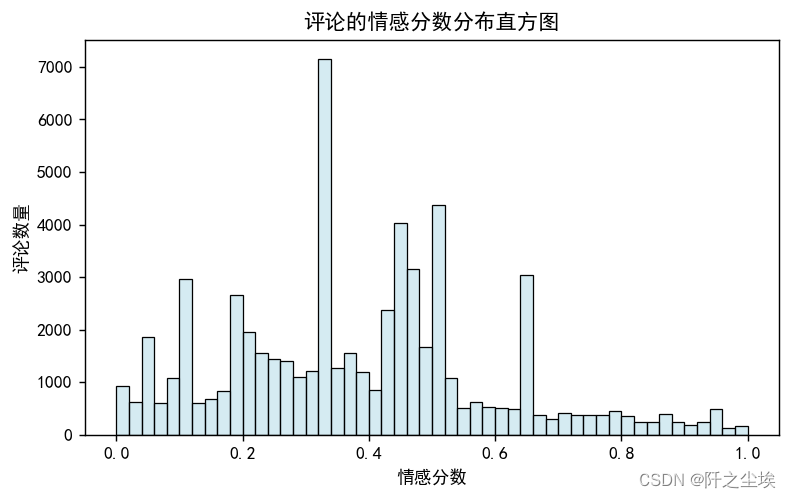
其中横轴代表情感值,从0.0到1.0,纵轴代表评论的数量。通常情感值接近0的表示负面情绪,接近1的表示正面情绪,而0.5附近通常被认为是中性。分析这个直方图,我们可以注意到几个关键点:
有三个显著的峰值分布在0.34、0.64和0.98。这可能表明有三种明显不同的情感倾向:负面、中性偏正面和强烈正面。情感值在0.32的负面情绪峰值较低,这可能意味着负面评论的数量相对较少。中间的峰值位于0.64附近,表明大部分评论倾向于中性或轻微正面。最右边的峰值非常接近0.98,表明有相当数量的评论表达了非常正面的情绪。
直方图两端的评论数量明显多于中间部分,这可能表明有部分用户倾向于发表极端情绪的评论,要么非常正面,要么非常负面。这也符合中国网民的习惯。
4.5主题分类分析(LDA)
使用sklearn进LDA主题建模。LDA就不多介绍了吧,一个无监督的文本聚类方法。
首先我们采用jieba库首先对评论文本的词频和其权重进行的抽取分析,挑选了权重数值钱20的词汇,
#主题分析
import jieba.analyse
jieba.analyse.set_stop_words('停用词.txt')
#jieba.add_word('杰叔')
text = ''
for i in range(len(parsed_comment_df['content'])):text += parsed_comment_df['content'][i]+'\n'
tags_with_weights=jieba.analyse.extract_tags(text,topK=20,withWeight=True)
pd.DataFrame(tags_with_weights, columns=['Keyword', 'Weight'])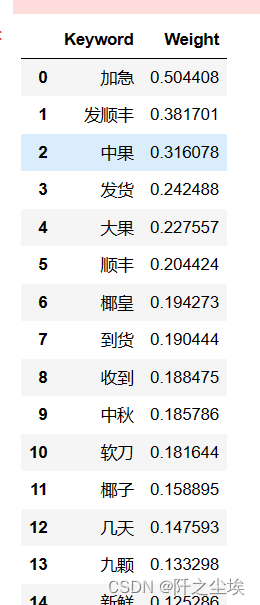
可视化如下:
df1=pd.DataFrame(tags_with_weights, columns=['Keyword', 'Weight'])
plt.figure(figsize=(7,3),dpi=256)
sns.barplot(x=df1['Keyword'][:20],y=df1['Weight'][:20])
plt.xticks(rotation=70,fontsize=9)
plt.ylabel('频率')
plt.xlabel('')
plt.title('前20个频率最高的词汇')
plt.show()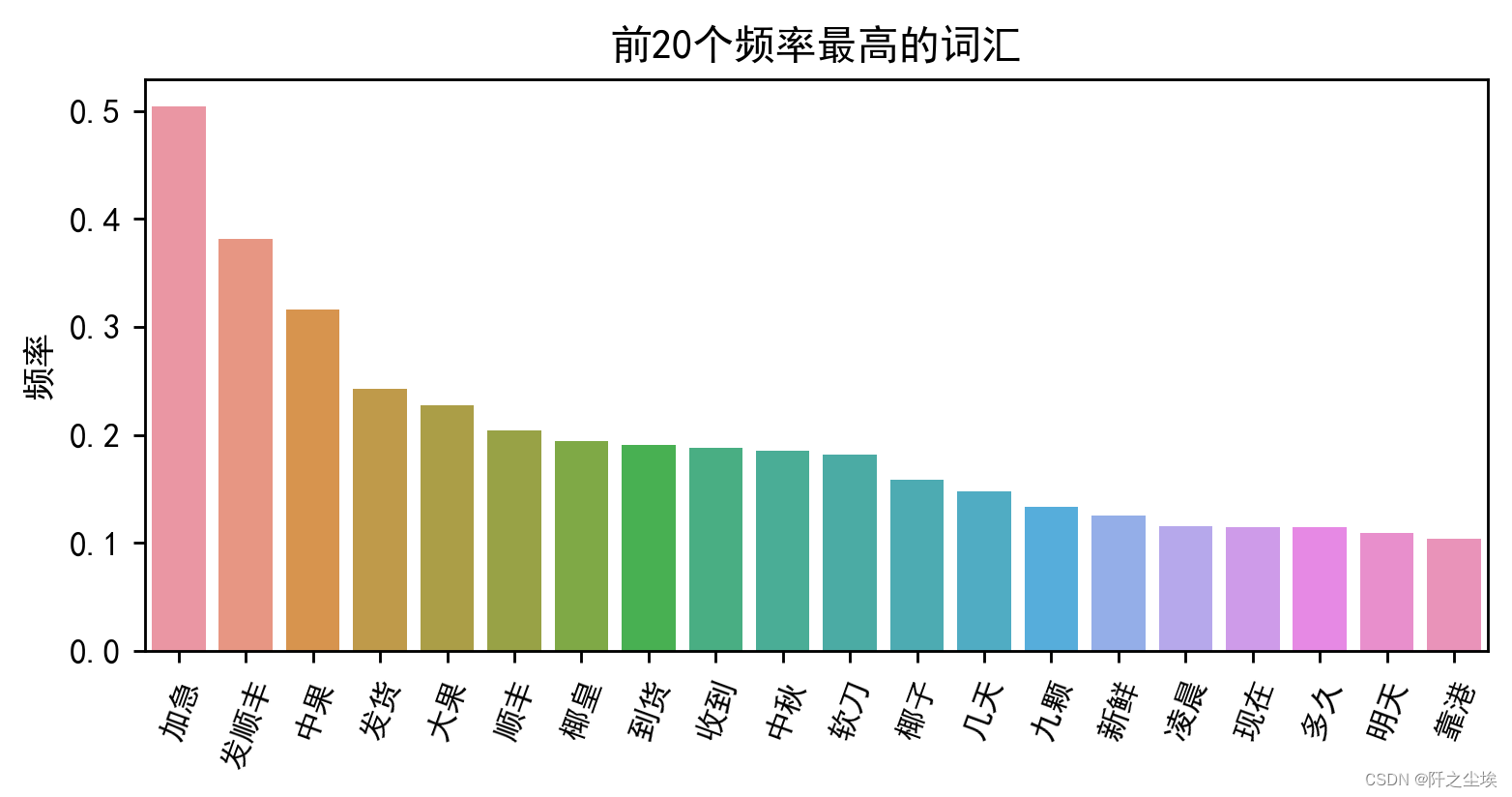
可以看到杰叔(0.782959)这个词的权重最高,这是卖家的品牌,也是官方账户回复常用词,也表示顾客可能经常提到这个名字,表明其对品牌或卖家的认可度高。感谢(0.476627):表示正面的情感态度,顾客对服务或商品的满意度高。加急(0.347757):顾客可能需要快速收到商品,表明对发货速度的关注。发顺丰(0.345859):顾客可能对快递公司有偏好,这里指顺丰快递,表明直播间都采用顺丰发货服务,顾客们对物流服务的质量有期待。支持(0.328136):这又是一个正面的情感词,表明顾客对卖家或商品的支持。
LDA建模前需要 分词然后过滤停用词:
#分词
stop_list = pd.read_csv("停用词.txt",index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8')
def txt_cut(juzi):lis=[w for w in jieba.lcut(juzi) if w not in stop_list.values]return (" ").join(lis)
parsed_comment_df['cutword']=parsed_comment_df['content'].astype('str').apply(txt_cut)开始LDA,使用tf-idf的词袋模型
## LDA建模
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
tf_vectorizer = TfidfVectorizer()
X = tf_vectorizer.fit_transform(parsed_comment_df['cutword'])
print(X.shape)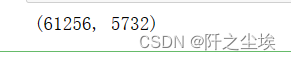
可以看到6.1w条评论,特征维度为5732,即经过了tf-idf变成了词矩阵后变成了5732维,数据量还有点大。
简单分为4类主题吧
n_topics = 4 #分为4类
lda = LatentDirichletAllocation(n_components=n_topics, max_iter=100,learning_method='batch',learning_offset=100,
# doc_topic_prior=0.1,
# topic_word_prior=0.01,random_state=0)
lda.fit(X)然后自定义一个函数,可以打印出每个主题最重要的词汇以及对应的权重:
def print_top_words(model, feature_names, n_top_words):tword = []tword2 = []tword3=[]for topic_idx, topic in enumerate(model.components_):print("Topic #%d:" % topic_idx)topic_w = [feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]]topic_pro=[str(round(topic[i],3)) for i in topic.argsort()[:-n_top_words - 1:-1]] #(round(topic[i],3))tword.append(topic_w) tword2.append(topic_pro)print(" ".join(topic_w))print(" ".join(topic_pro))print(' ')word_pro=dict(zip(topic_w,topic_pro))tword3.append(word_pro)return tword3打印前20个:
n_top_words = 20
feature_names = tf_vectorizer.get_feature_names_out()
word_pro = print_top_words(lda, feature_names, n_top_words)
只看文本不直观,下面画出对应的词云图可视化。
首先把聚类的类别添加到数据框里面
#输出每篇文章对应主题
topics=lda.transform(X)
topic=np.argmax(topics,axis=1)
parsed_comment_df['topic']=topic
#df.to_excel("data_topic.xlsx",index=False)
print(topics.shape)
print(topics[0])
topic[0]自定义一个颜色函数
import random #定义随机生成颜色函数
def randomcolor():colorArr = ['1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']color ="#"+''.join([random.choice(colorArr) for i in range(6)])return color
[randomcolor() for i in range(3)]导入主要的包
from collections import Counter
from wordcloud import WordCloud
from matplotlib import colors
#from imageio import imread #形状设置
#mask = imread('爱心.png') def generate_wordcloud(tup):color_list=[randomcolor() for i in range(10)] #随机生成10个颜色wordcloud = WordCloud(background_color='white',font_path='simhei.ttf',#mask = mask, #形状设置max_words=20, max_font_size=50,random_state=42,colormap=colors.ListedColormap(color_list) #颜色).generate(str(tup))return wordcloud画图:
dis_cols = 2 #一行几个
dis_rows = 2
dis_wordnum=20
plt.figure(figsize=(5 * dis_cols, 5 * dis_rows),dpi=128)
kind=len(parsed_comment_df['topic'].unique())for i in range(kind):ax=plt.subplot(dis_rows,dis_cols,i+1)most10 = [ (k,float(v)) for k,v in word_pro[i].items()][:dis_wordnum] #高频词ax.imshow(generate_wordcloud(most10), interpolation="bilinear")ax.axis('off')ax.set_title("第{}类话题 前{}词汇".format(i+1,dis_wordnum), fontsize=30)
plt.tight_layout()
plt.show()
第一类话题:这个话题似乎集中在客户对产品(如椰子)和服务的满意度表达上。关键词如“支持”,“感谢”,“杰叔”表明正面的情感反馈和对卖家的认可。同时,“新鲜”,“好喝”,“特别”等词汇表明产品质量是用户评论的重点。物流服务也是关注点,诸如“发顺丰”和“快递”表明用户对配送速度和质量有积极评价。整体而言,第一类话题反映了用户对产品和服务的高满意度。
第二类话题:这一话题更多地集中在物流流程,特别是发货和到货的时间。关键词如“发货”,“明天”,“到货”,“发出”,和“顺丰”表明用户非常关心订单处理的速度和效率。此外,“性价比”和“回购”指示用户在评估成本效益和复购意愿时也考虑了物流因素。这些关键词可能表示用户在选择产品时,会考虑卖家的发货速度和物流选择。
第三类话题:这个话题似乎关注于用户的特殊需求和紧急服务,如“加急”和“现在”表明用户需要快速服务。关键词“软刀”和“冰箱”可能与产品的特殊处理或保存方式有关,而“中秋”表明可能有节日购物的季节性因素。此外,“收到”和“已经”可能表示用户对接收商品的实时状态有着迫切的关注。
第四类话题:这一类话题聚焦在购物体验和特定群体的需求。例如,“孕妇”可能表明产品或服务针对特定客户群体的讨论。关键词“下单”,“打开”,“看看”,和“保存”反映了用户在购买和使用产品后的体验。城市名字如“北京”和“上海”可能表示地域上的发货或用户分布情况。
结合这四个话题,分析表明用户评论涉及产品满意度、物流服务、特殊需求满足和购物体验的不同方面的关注点。
数值型数据存储一下,给后面下一篇文章做机器学习用。
data[['ONLINE_USER_CNT', 'follow_anchor_ucnt','fans_club_join_ucnt', 'pay_combo_cnt', 'pay_ucnt', 'pay_amt','comment_count', 'avg_comment_length', 'sentiment', 'open']].to_csv('预测RoomJ.csv')5. 结果与讨论
经过了评论的数量,内容,情感,趋势等数据和可视化的分析,我们可以得到如下的一些结论。
很多直播间的活跌宕起伏主要集中在晚上,尤其是21-24时段,因此可以在这个时间段推出重点内容或促销活动以吸引更多观众和潜在买家。
用户的评论文本长度为在各个时段较为均匀,说明直播内容在全天都有一定吸引力,但同时也意味着没有特别的高峰期,可能需要通过特别活动来创造高峰。
用户的社交互动行为,情绪状态分布均匀,表明直播间具有持续的社交活跃度。可以利用这点来增强社区的互动性,比如设置问答环节或互动游戏,以保持用户的持续参与。
大部分用户对产品/服务持中性到正面的态度,这是一个好现象,说明产品/服务在总体上是受欢迎的。极端正面的评论数量众多,这意味着有一定比例的用户非常满意。可以进一步分析这些评论来了解用户满意的具体方面,并加以强化。负面评论相对较少,但是极端情绪发言还是存在,仍需要关注。应该分析这些评论找出常见问题,并尝试解决这些问题以提高用户满意度。
关键词分析对于不同的直播间是不一样的,主播应该关注这些关键词背后的内容,进一步优化直播策略,如保证食品质量、提供更多的购买链接、增加试吃环节和福利活动,以及解决负面反馈问题,以提高用户满意度和促进销售。
通过主题分析我们可以得到电商平台可以根据这些信息来优化产品和服务,例如,通过确保产品质量和新鲜度,提高发货和配送效率,满足用户的紧急需求,以及针对特定客户群体提供定制化服务。此外,了解用户在特定节日或活动期间的购买行为也有助于进行市场营销和库存管理。
(本文演示的所有代码文件和数据集获取参考:电商直播间评论)
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~
这篇关于Python数据分析案例39——电商直播间评论可视化分析(LDA)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




