本文主要是介绍AI与律师比赛审核保密协议,人类输了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

AI 科技评论按:昨天,一家坐落于以色列的初创公司 Lawgeex 举行了一场人机比赛:AI v.s. 人类律师,在 4 个小时内审查五项(共 14 页)保密协议,结果 20 名经验丰富的人类律师无论从时间还是准确度上都远逊于 AI,被机器完败。这向人们证明了,AI 已经有能力接替人类在法律领域的某些工作。

机遇与挑战
人工智能对商业产生的变革显而易见,在全球有 6000 亿美元的法律服务市场当然也不能幸免。据咨询公司 McKinsey 估计,22% 的律师工作和 35% 的律师助理工作都可以通过自动化来完成。显然,对于某些非核心的法律任务来说,机器应该比律师处理的更快且更好,例如合同审核工作。
2014 年成立的人工智能合同审查自动化解决方案公司 LawGeex 在这方面做得尤为出色。他们认为合同审查是现在每个公司都会需要的且数量庞大,例如典型的 1000 强企业,差不多在任何时候都会维持 2 万到 4 万个活跃的合同。但是据国际合同和商业管理协会(IACCM)调查,有 83% 的企业对其合同流程不满意,因为例如交易中常见的保密协议(NDA)一般需要一周或更长的时间才能批准下来,这大大降低了交易的速度。
而从另一方面对律师来说,审核这些合同大多只是重复性体力劳动,浪费了大量的时间,而又不得不做。
这样的市场需求似乎是在召唤着人工智能的到场,但事实并不是那么容易,在法律文件方面训练人工智能模型其实还有蛮多独特的挑战的。
首先是法律术语——通常这些法律语言复杂且违反直觉,这让训练变得十分困难。对于合同审查和批准,自然语言处理(NLP)和现成的解决方案根本不起作用,没有现有的计算语言模型能够连贯地阅读法律术语。
其次是高精度的要求——律师的主要职责是控制甚至降低其公司或客户的风险,准确性至关重要。在法律人工智能的训练中,单一文档分析要求的准确性要高得多,比如大数据「情感」分析(使用文本分析挖掘不同数据来源以获得意见以预测趋势的过程)。
针对第一个问题,LawGeex 创建了新的法律「语言」——专有的法律语言处理(LLP)和法律语言理解(LLU)模型。律师和工程师团队通过给 AI 展示大量的法律文件,教授了 LawGeex AI 相关的法律文献。当 AI 学习法律术语时,法律训练人员会指出它需要识别的概念。LLP 技术允许算法识别这些概念,即使这些词组它从来没有见过。
另一方面他们采用监控概念,而不是关键字 - LawGeex AI 的操作方式要比迟钝的「关键字搜索」复杂得多。关键字搜索可能过多或过少,因为相关文档中可能没有相关文字,或出现在不相关的文档中。但是真正的人工智能应该能够识别出一个概念,不管它是什么样的词组或出现在文档中的什么地方。
比赛
这次比赛的内容为四小时审查五项保密协议(NDA),并确定 30 个法律问题,包括仲裁、关系保密和赔偿等。如何准确界定每个问题是比赛的得分要点。

需要说的是参加比赛的这些律师都是拥有十多年从业经验的律师,而 LawGeex AI 也不是从头开始学习。按照 LawGeex 的介绍,LawGeex AI 已经接受了足够的训练,不光是 NDAs,它还可以检测十几种不同的法律合同,从软件协议到服务协议到采购订单。但在这项具体的比赛中,它仅关注 NDAs--最常见的商业合同形式。
比赛的结果预料之中,人类律师输了。
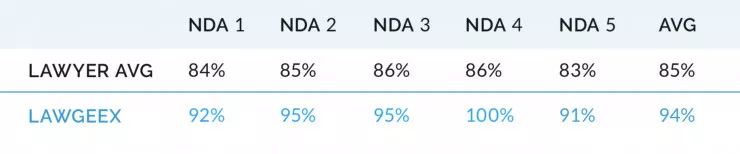
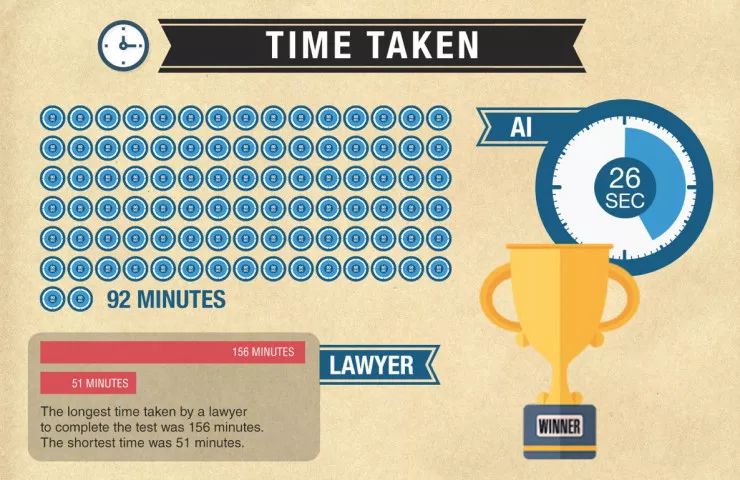
人类律师的平均准确率仅为 85%,而 AI 的准确率达到了 95%。时间上,AI 仅仅用了 26 秒就完成了任务,而人类律师平均需要 92 分钟。值得注意的是,人工智能在这些合同中最高可以达到 100%的准确率,而其中人类律师的最高得分仅为 97%。

意义
尽管这并不是法律领域人类与 AI 对抗第一次比赛(也不会是最后一次),但它是 AI 首次与真实的有经验的律师之间的 PK。这使得比赛的结果在一定程度上可以说明,法律领域的某些工作,AI 可以比从业多年的人类专家完成的更好。
这可能会引起法律从业者的恐慌——难道在不久的将来律师要被机器所取代了吗?这真的是多虑了。目前来看,AI 在各个领域中还只能从事部分重复性工作。对于律师来说,AI 的出现其实是一种福音,它可以帮助自己处理掉大量重复性劳动工作,这一方面可以加快自己的工作速度,另一方面也能够给自己足够多的时间专注于那些真正有创造性的工作当中。



这篇关于AI与律师比赛审核保密协议,人类输了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







