本文主要是介绍高清变脸更快更逼真!比GAN更具潜力的可逆生成模型来了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

变栗 问耕 发自 凹非寺
量子位 出品 | 公众号 QbitAI
昨天上市即破发的小米,今天上午股价大涨近10%。这下雷军要笑了。
而且可以笑得更灿烂。更灿烂是什么样?来,我们用OpenAI刚刚发布的人工智能技术,给大家展示一下。
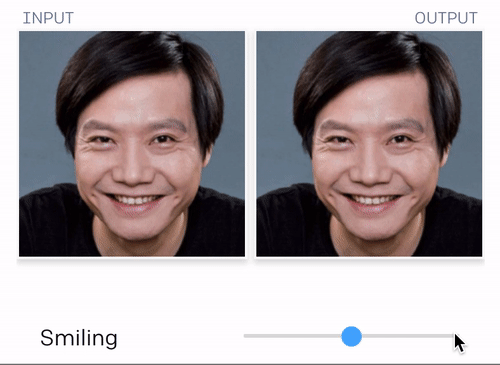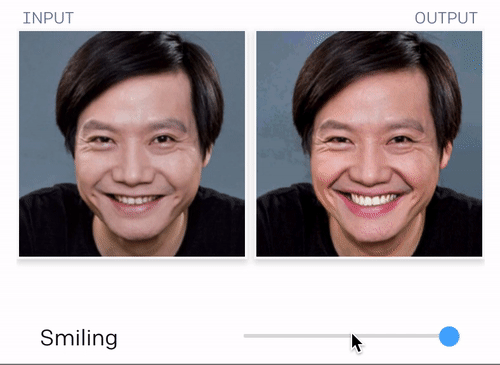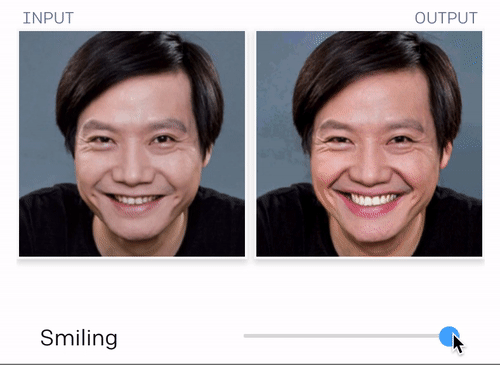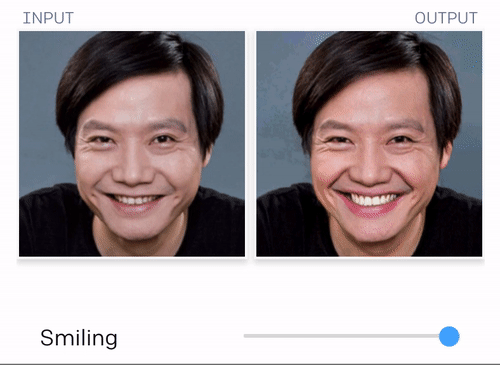
当然这个最新的技术,不止这点本事。它的“想象力”很强大的说~
比如,留胡子的硬汉版雷布斯什么样?
以及,娘化的雷布斯又是什么样?

还有。
OpenAI这个称作Glow的生成模型,不仅能像上面这样自动处理高清图片,而且还能把两个人的照片MIX一下。
说到MIX,还是以小米举例吧。
想象一下,碧昂丝和雷布斯如果有后代的话,会是什么样?把他俩照片放在一起,MIX一下……结果如下图所示。而且还可以调整父母的影像力,比方如1/4碧昂丝+3/4雷军……

好像……毫无违和感。
而且,这个新技术还放出了可用的Demo,如果你也想试试变脸或者合成照片,可以前往OpenAI官网,传送门在此:
https://blog.openai.com/glow/
Glow:另辟蹊径
上面讲的就是OpenAI发布的新技术Glow,一个AI通过观察原始图片,学会如何根据不同的属性,生成全新的高清图片。
更厉害的是,这个生成模型,既不是基于大火的对抗生成网络GAN,也不是变分自编码器VAE。
Glow是一种可逆的生成模型,也称为基于流的生成模型,它源于对NICE和RealNVP技术的扩展。与GAN和VAE两大流派相比,基于流的生成模型迄今为止在研究界很少受到关注。
NICE的论文最早发布于2014年,作者是来自蒙特利尔大学的Laurent Dinh、David Krueger、Yoshua Bengio。
传送门:https://arxiv.org/abs/1410.8516
RealNVP的论文最早发布于2016年,作者是蒙特利尔大学的Laurent Dinh以及谷歌大脑的Jascha Sohl-Dickstein、Samy Bengio。
传送门:https://arxiv.org/pdf/1605.08803.pdf
基于流的生成模型,有几个优点,例如:精确的潜变量推断和对数似然评估、可同时处理高效的推理和有效的合成、下游任务可用的潜在空间、显著节省内存空间等。
而且这种生成模型,并不限于图像处理,在语音合成、文本分析与合成、半监督学习和基于模型的控制等领域皆可应用。
开头演示的那些可调整属性,都不是预先标记好喂给神经网络的。朝怎样的方向变化,会产生发色啊,胡须量啊,诸如此类的改变,都是AI自己在潜在空间里面学到的。
OpenAI披露的信息显示,Glow模型在一块NVIDIA 1080 Ti GPU上生成256×256的样本,需要130ms。
这次的变脸,更流畅
为了让图像发生更流畅的变化,团队以Dinh等人2016年的研究为基础,提出了一种新的生成流 (Generative Flow) ,叫做Glow:
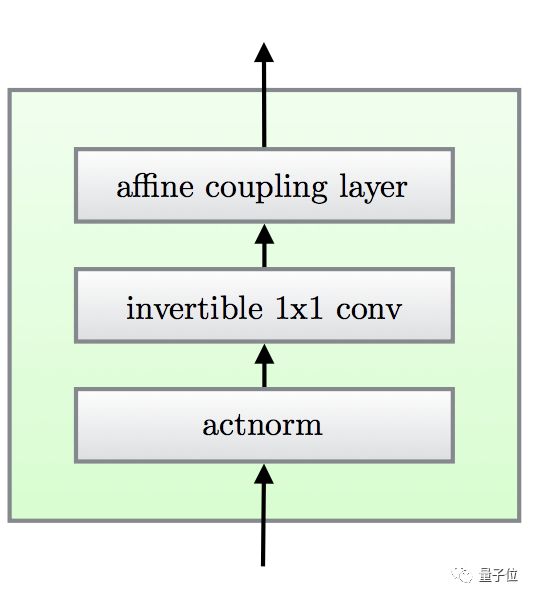
每一步 (绿框) ,都要从一个actnorm步骤开始,把激活神经元归一化 (Activation Normalization) 。
紧跟着,是一个可逆的1x1卷积,输入和输出通道数量一样多。
再往后,是一层仿射变换 (Affine Transformation) 。Dinh团队提出的可逆转换,很强大,在这里被沿用了。
这三步组成一个绿框,无数的绿框连在一起,就有了周而复始的生成流。
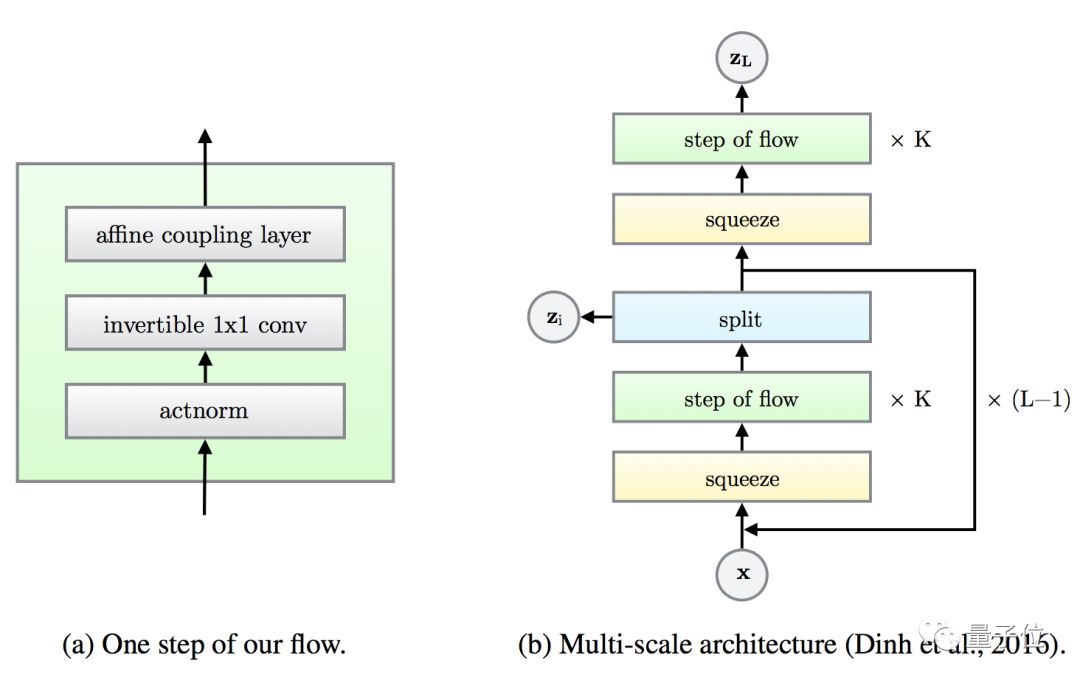
然后,把这个流,跟右边的多尺度 (Multi-Scale) 架构结合在一起。
潺潺流淌,人脸就可以在神经网络里,发生安静又自然的变化了。

是AI自己找到的方向
在模型的训练数据上,研究人员没有手动添加任何标记。
AI会在潜在空间里,掌握各种各样的变化规律。
不论是把光滑的下颌变得胡子拉碴,还是为起气色红润的面孔完成卸妆。
没有地图,所有的方向,AI都要自己找到。

幸好,它没有迷路。
变成不一样的自己

不管是发色,面色,还是表情,这些语义特征AI或许并不懂,但这并不妨碍它实现这些属性的变化。
用编码器给图像编码,为有胡子和没胡子的样子,分别算出一个潜在向量。

两个向量之间,相差的那个向量,就是调整胡子浓密程度的滑块了。
变成别人
用编码器,给两张不同人类的照片编码。可以产生二者之间的变换过程,很完整。
从换脸途中任取一张图,就能看到两个人的基因,和解之后的样子了。

除了肉眼可辨的效果之外,团队还对比了Glow和前辈RealNVP (来自2016年的Dinh实验室) ,处理数据集时的成绩——

结果是,在5个数据集里,这只闪闪发光的模型,表现都要优于RealNVP。完成相同的任务,Glow需要的数据量更少。
青出于蓝。
选择跟随Dinh的脚步,是因为OpenAI团队看到了可逆生成模型的优点。

它跟VAE不同,跟GAN也不同,潜变量 (Latent Variable) 有了确切的推断,不只是一个近似值了。
另外,可以给数据,生成确切的对数似然值 (Log-Likelyhood) ,不只是一个下限了。
总而言之,这样的模型比起前辈们,拥有更多确定的答案。
论文+代码

Glow的作者是来自OpenAI的两位:Diederik P. Kingma、Prafulla Dhariwal。而且OpenAI这次一口气放出了Glow的论文以及代码。
论文传送门:
https://d4mucfpksywv.cloudfront.net/research-covers/glow/paper/glow.pdf
代码传送门:
https://github.com/openai/glow
— 完 —


点击下方“阅读原文”了解云创大数据诚征公安总代理事宜 ↓↓↓
这篇关于高清变脸更快更逼真!比GAN更具潜力的可逆生成模型来了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






