本文主要是介绍[Caffe] - No.3 ssd-caffe(2):训练ssd-caffe模型:(以VOC数据集为例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2.训练ssd-caffe模型:(以VOC数据集为例)
使用caffe进行目标检测,我们的需要标注了标签的图片作为训练样本,训练模型。推荐使用开源的标注工具labelimg,来对我们的图片进行标注。标注之后,会产生.xml文件,用于标识图片中物体的具体信息。
这里,我们以VOC格式的数据为示例:
VOC的数据格式,主要有三个重要的文件夹:Annotations、ImageSets和JPEGImages
Annotations: 存放.xml标注文件
ImageSets/Main: 存放
train.txt、test.txt、trainval.txt、val.txttest.txt中保存的是测试所用的所有样本的名字,不过没有后缀(下同),一般测试的样本数量占总数据集的50%train.txt中保存的是训练所用的样本名,样本数量通常占trainval的50%左右val.txt中保存的是验证所用的样本名,数量占trainval的50%左右trainval.txt中保存的是训练验证样本,是上面两个的总和,一般数量占总数据集的50%
生成上述文本的代码如下:
import os
import random trainval_percent = 0.66
train_percent = 0.5
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath) num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr) ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
print("done")由于caffe只能处理lmdb格式的数据,如果你有自己的数据想要放在caffe上进行训练,方式如下:
- 自定义数据和VOC数据格式相同:直接使用VOC的数据集转换的代码转换为lmdb
- 自定义的数据和VOC的数据格式有出入:自己写代码或者修改源码
src/caffe/util/io.cpp,转换为lmdb格式
训练步骤如下,以mydataset为例:
分别创建
examples/mydataset,data/mydataset,data/VOCdevkit/mydataset三个文件夹:data/VOCdevkit/mydataset:将刚刚生成的Annocations等几个文件夹复制进去data/mydataset:将data/VOC0712下的create_list.sh,create_data.sh,labelmap_voc.prototxt三个文件拷贝到该文件夹create_list.sh:根据之前生成的ImageSets/Main中的train.txt等文件,生成具体的文件路径信息等。运行该文件夹会在当前目录生成几个txt文件更改
create_list.sh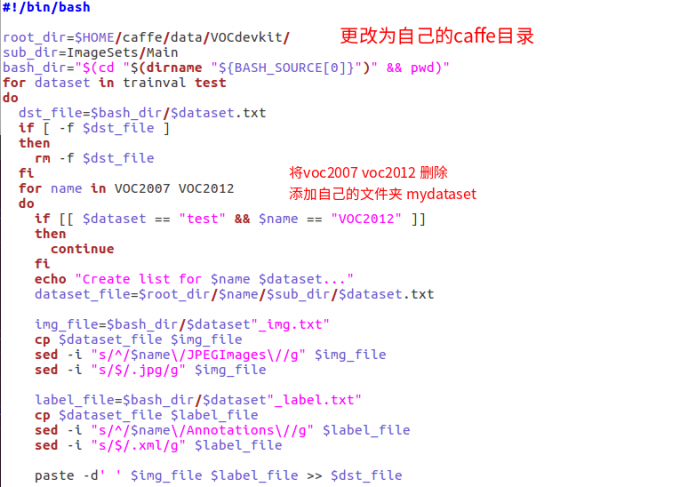
create_data.sh:生成lmdb文件,运行该文件夹,会在examples/mydataset生成更改
create_data.sh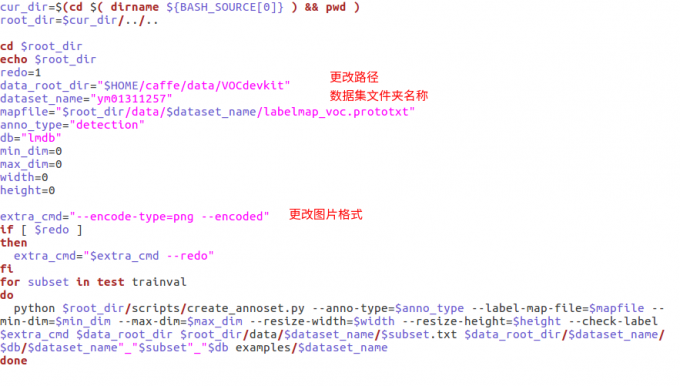
在ssd-caffe的根目录,运行如下命令:
./data/mydataset/create_list.sh ./data/mydataset/create_data.sh即可生成上述提到的文件。若运行两个.sh脚本文件错误,则删除刚刚生成的文件,debug后重新运行
运行成功以后,在
examples/mydataset即生成lmdb文件复制
examples/ssd/路径下的ssd_pascal.py文件到example/mydataset下,修改相应参数:修改所有文件夹路径为自己的路径
如果本机显存太小,修改
batch_size为8修改标签个数
num_classes为自己的种类n+1
(1即为添加的backgroud标签,识别为背景。另外,我们的xml标签文件中不能出现编号为0的backgrouond标注,否则会报错。这个问题在ssd-caffe的issue上也有提到,至今没有解决)
- 修改
max_iter等参数,将迭代次数减小,也可以不修改使用默认
在ssd-caffe根目录下运行
python example/mydataset/ssd_pascal.py等待模型运行结束
复制
examples/ssd/路径下的score_ssd_pascal.py文件到example/mydataset下,修改相应文件路径,即可测试模型:python example/mydataset/score_ssd_pascal.py
3. 调用训练完成的模型,对单张图片进行测试:
我们训练完的模型应该保存在以下路径:
models/VGGNet/mydataset/SSD_300X300
.
├── deploy.prototxt
├── solver.prototxt #超参数
├── test.prototxt
├── train.prototxt
├── VGG_mydataset_SSD_300x300_iter_55.caffemodel
└── VGG_mydataset_SSD_300x300_iter_55.solverstate
将example/ssd路径下的ssd_detect.py文件复制到example/mydataset下,将输入,输出的文件路径修改为自己的路径(其中包含网络定义,模型文件,标签文件,测试图片,输出图片等)
P.S. 文章不妥之处还望指正
这篇关于[Caffe] - No.3 ssd-caffe(2):训练ssd-caffe模型:(以VOC数据集为例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





