本文主要是介绍机器学习_逻辑回归、聚类分析、模型调用与保存,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、模型的加载与保存
# 保存训练好的模型
joblib.dump(自己命名分类器名称, "保存地址")
# 比如 lr = LogisticRegression(),那里就写lr# 调用保存好的模型(训练好的)去做预测
model = joblib.load("地址")
y_predict = model.predict(x_test)
# 当我们的x,y都被正则化的时候
#y_predict = std_y.inverse_transform(model.predict(x_test))
print("保存的模型预测的结果:", y_predict)
二、逻辑回归
应用场景
0-1分类问题
公式
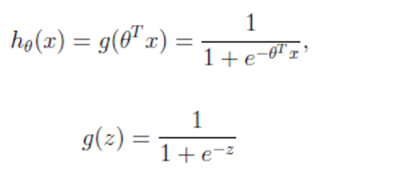
优缺点
优点:计算代价不高,易于理解和实现
缺点:容易欠拟合,分类精度不高
适用数据:数值型和标称型
逻辑回归示例
# 默认内置函数为sigmoid,也可选择其它内置函数Relu
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report# 读取数据,附上列标签
colum_names = ['Sample code number','Clump Thickness', 'Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei',这篇关于机器学习_逻辑回归、聚类分析、模型调用与保存的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





