本文主要是介绍ELK,ELFK日志收集分析系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ELK简介
ELK是一套完整的日志集中处理解决方案,将ElasticSearch,Logstash和Kibana三个开源工具配合使用,实现用户对日志的查询、排序、统计需求。
ELK工作原理
在所有需要收集日志的服务器上部署Logstash,或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署Logstash
Logstash收集日志,将日志格式化并输出到Elasticsearch集群中,Elasticsearch对格式化的数据进行索引和存储
Kibana从ES集群中查询数据生成图表,并进行前端数据的展示
Elasticsearch介绍
是基于Luccene(一个全文检索引擎的架构)开发的分布式存储检索引擎,是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大容量的日志数据,也可用于搜索许多不同类型的文档
Elasticsearch是基于java语言开发,可以通过restful web接口,让用户可以通过浏览器与Elasticsearch通信
Logstash介绍
数据收集引擎,它支持动态的从各种数据源搜集数据,并对数据进行过滤,分析,丰富,统一格式等操作,然后存储到用户指定的位置,一般发送给Elasticsearch
Kibana介绍
kibana是一个功能强大的数据可视化 Dashboard(仪表板),kibana提供图形化的web界面来浏览
Elasticsearch日志数据,可以用来汇总,分析和搜索重要数据
Filebeat介绍
filebeat是轻量级的开源日志文件数据收集器,通常用于需要采集数据的客户端安装filebeat,并指定目录与日志格式,并发送给 logstash 进或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代,常应用于 EFLK 架构当中
Fluentd介绍
fluentd是一个流行的开源数据收集器,由于logstash太重量级的缺点,logstash性能低,资源消耗比较多等问题,随后就有 Fluentd 的出现。相比较 logstash,Fluentd 更易用、资源消耗更少、性能更高,在数据处理上更高效可靠,受到企业欢迎,成为 logstash 的一种替代方案,常应用于 EFK 架构当中
搭建ELK
| 主机名 | ip地址 | 需安装的软件 |
| node1 | 192.168.94.7 | elasticsearch,kibana |
| node2 | 192.168.94.8 | elasticsearch |
| apache | 192.168.94.9 | apache logstash |
安装elasticsearch
#更改主机名
#node1
hostnamectl set-hostname node1
bash
#node2
hostnamectl set-hostname node2#以下两台同时做
vim /etc/hosts
192.168.94.7 node1
192.168.94.8 node2#查看java版本,若没安装 yum install java -y 安装一下 openjdk即可
java -version#部署elasticsearch软件
#将elasticsearch-5.5.0.rpm包放在opt下,可以去官网获取
cd /opt
rpm -ivh elasticsearch-5.5.0.rpm#加载系统服务
systemctl daemon-reload
systemctl enable elasticsearch.service#修改配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
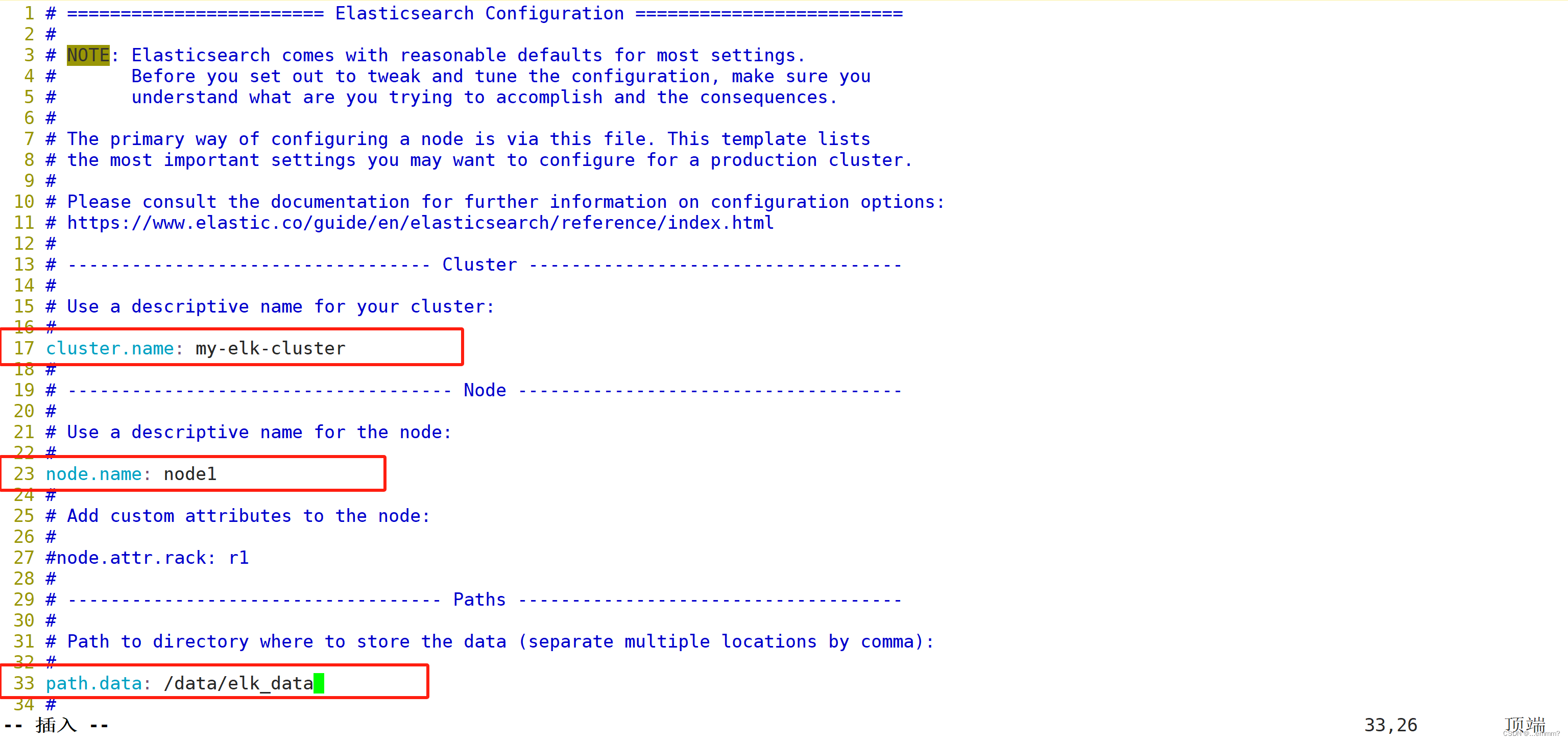
vim /etc/elasticsearch/elasticsearch.yml--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
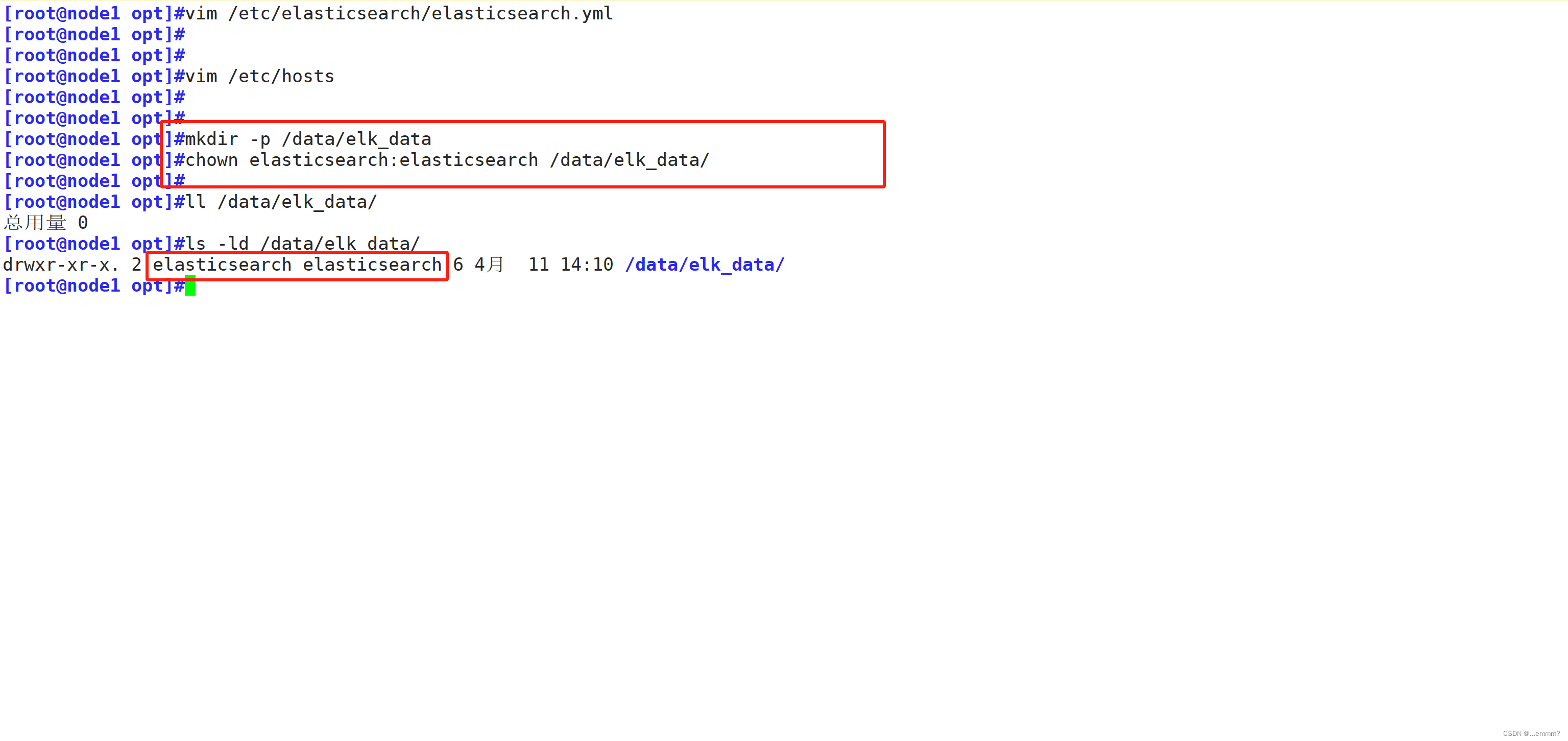
discovery.zen.ping.unicast.hosts: ["node1", "node2"]#创建数据存放路径并授权
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/#启动elasticsearch,并查看是否成功开启
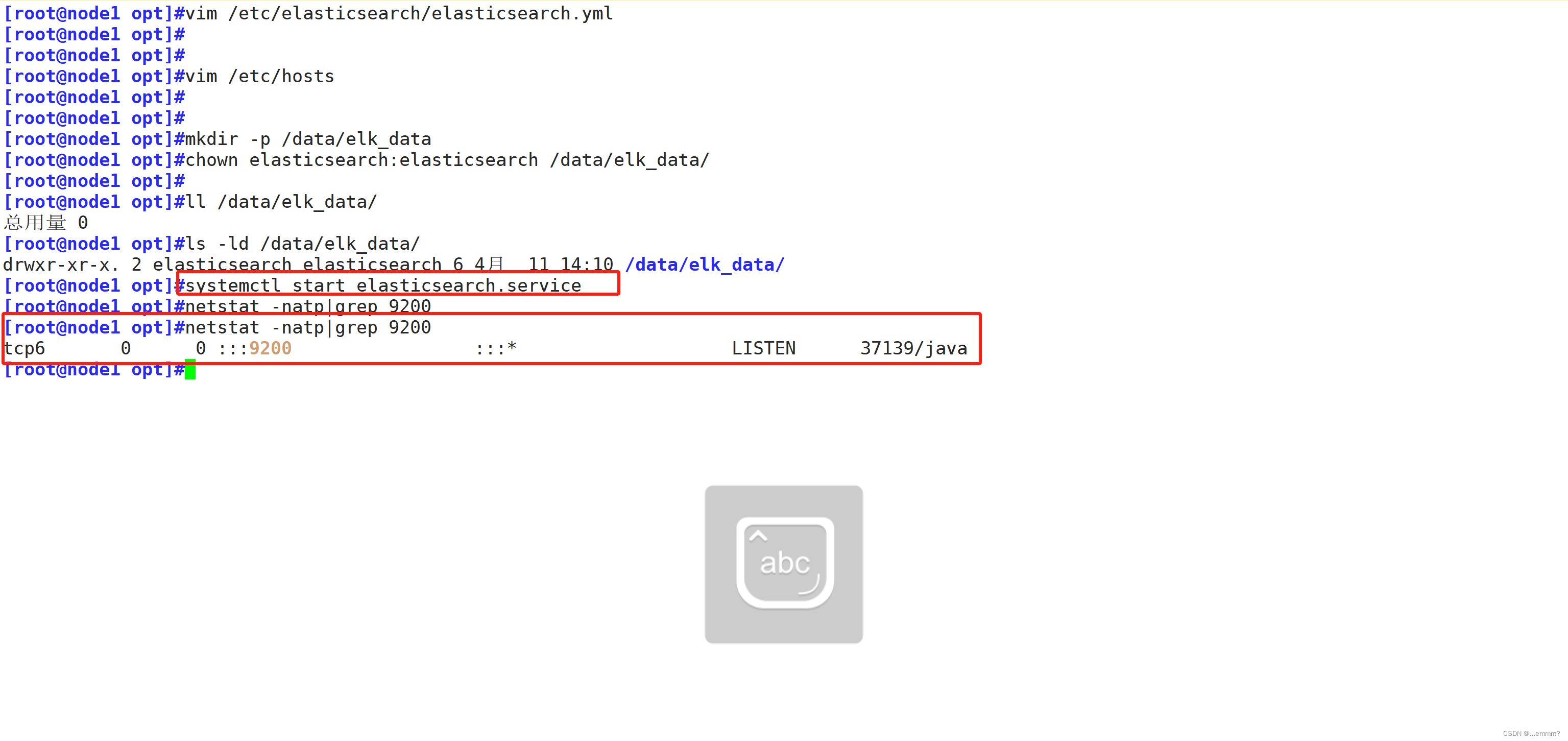
systemctl start elasticsearch.service
#可能需要等待10秒左右
netstat -natp|grep 9200#查看节点信息
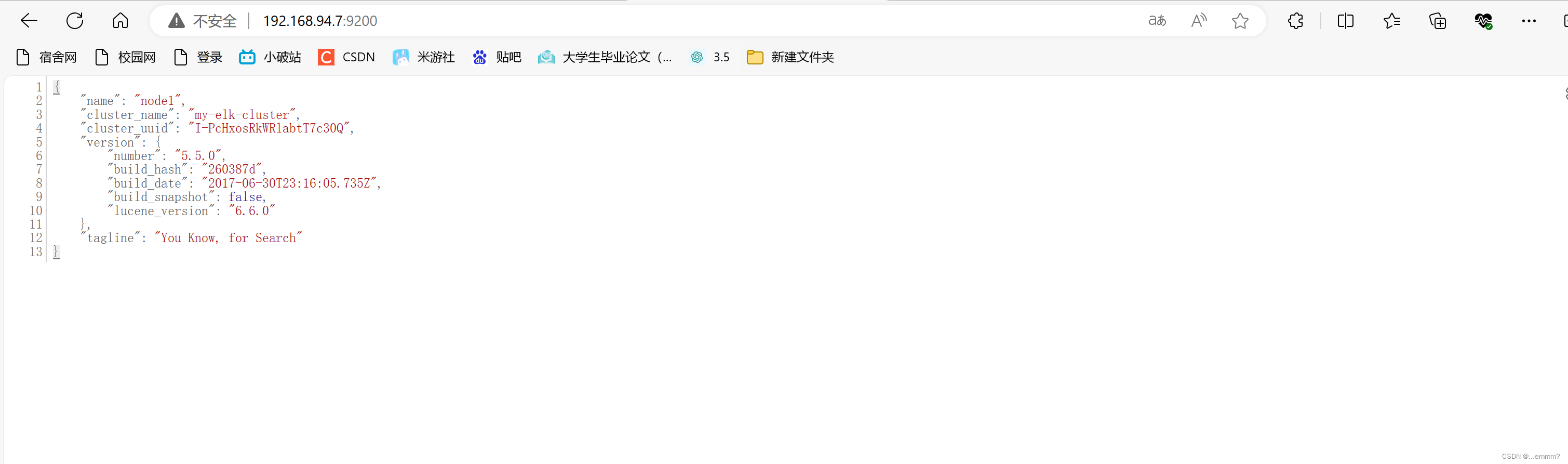
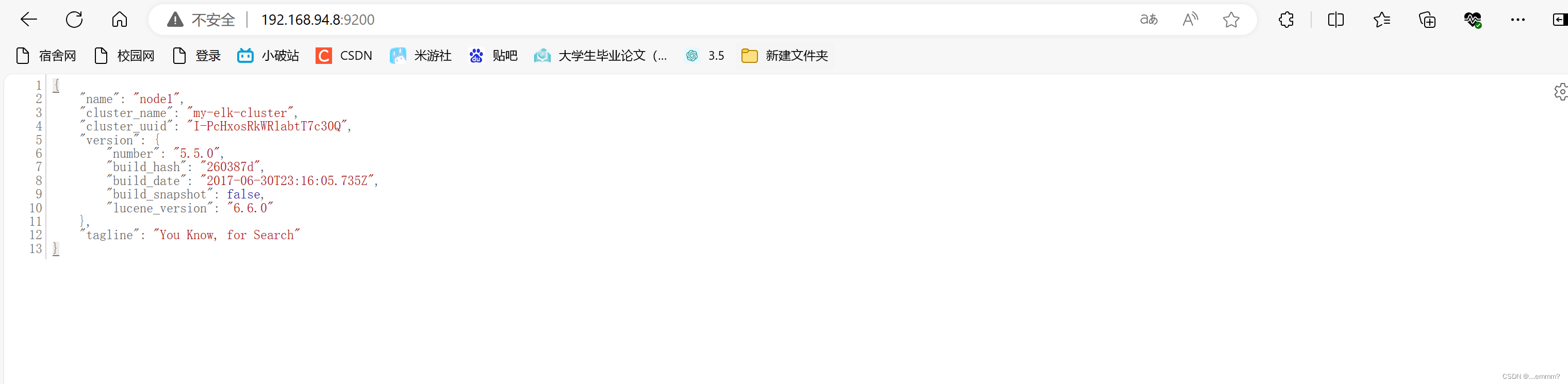
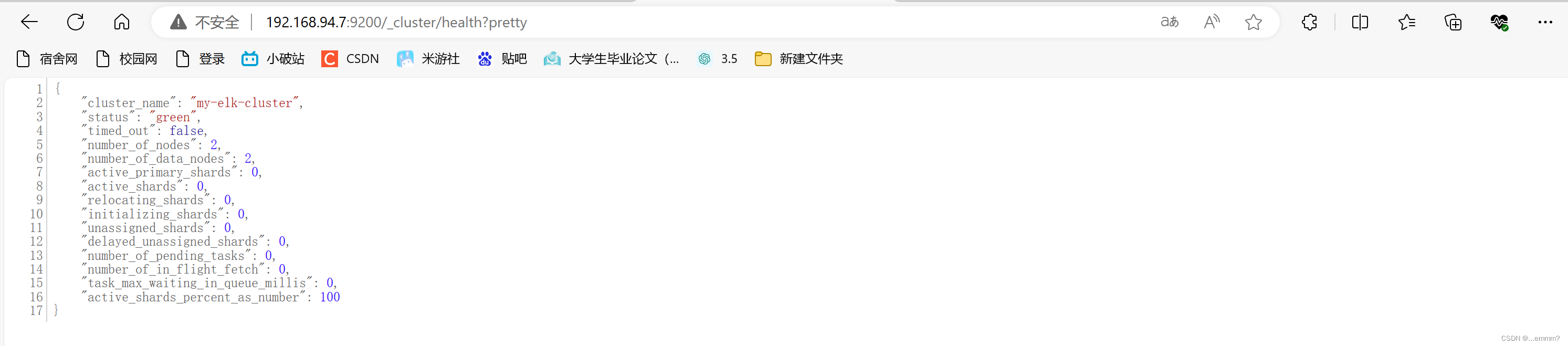
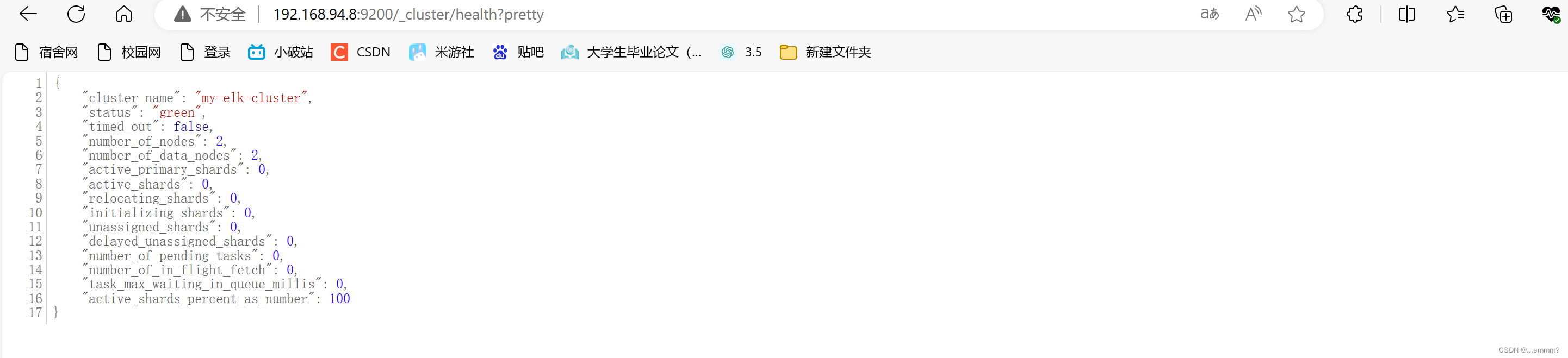
浏览器访问 192.168.94.7:9200 192.168.94.8:9200 查看node1,node2的节点信息浏览器访问
192.168.94.7:9200/_cluster/health?pretty
192.168.94.8:9200/_cluster/health?pretty
查看群集的健康情况,可以看到 status 值为 green(绿色),表示节点健康运行。
绿色:健康 数据和副本 全都没有问题
红色:数据都不完整
黄色:数据完整,但副本有问题







使用上述方式查看群集的状态对用户并不友好,可以通过安装 Elasticsearch-head 插件,可以更方便地管理群集
安装 Elasticsearch-head 插件
#两个节点同时操作
#切换到opt
cd /opt#准备安装包,node Elasticsearch-head phantomjs 安装包
#下载编译安装工具
yum install gcc gcc-c++ make -y#解压node压缩包
tar xf node-v8.2.1.tar.gz#进行编译安装,这个需要一段时间,大概10分组左右,可以根据自己的内核核数,make -j 数字 来加快编译速度
cd node-v8.2.1/
./configure
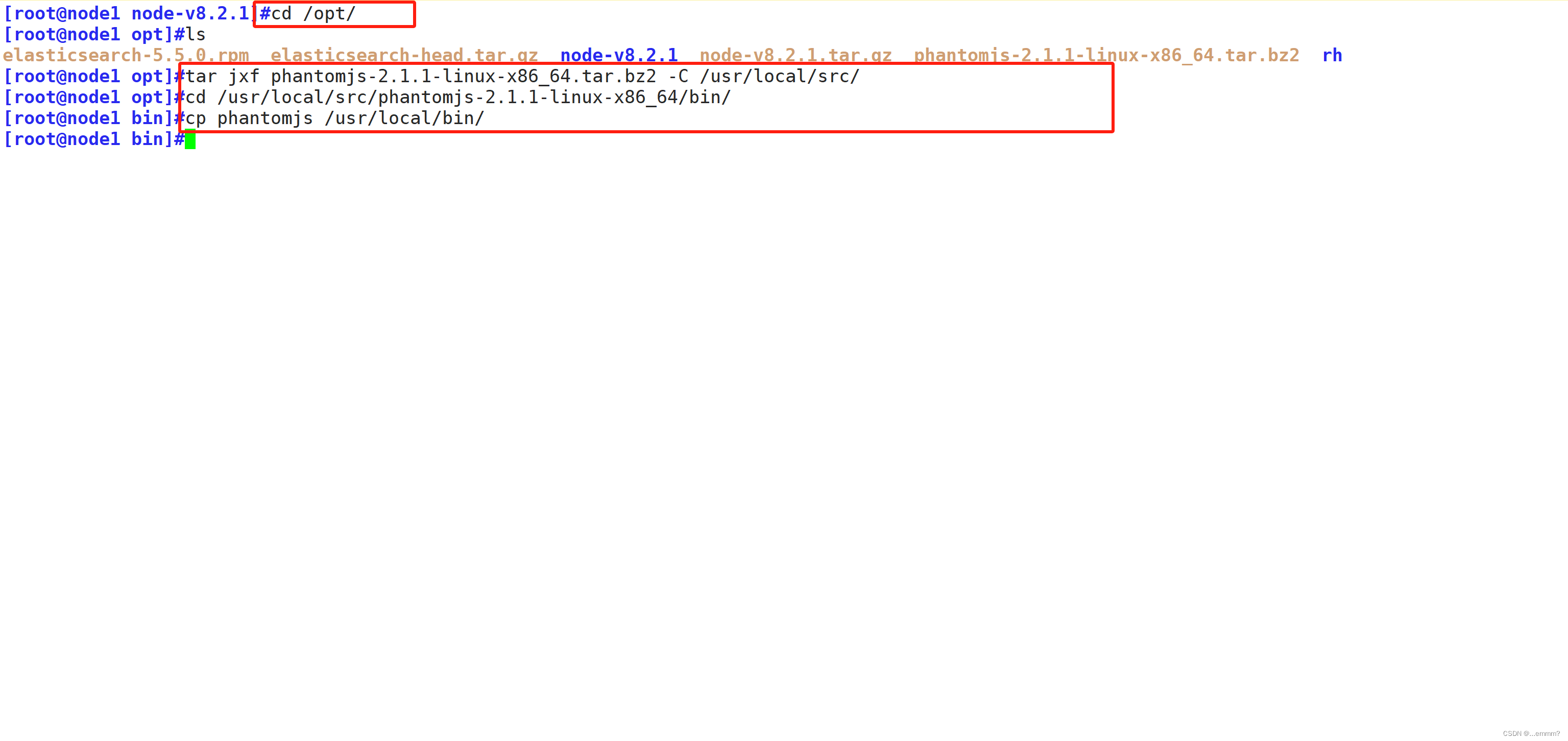
make && make install#安装 phantomjs
cd /opt
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin#安装 Elasticsearch-head 数据可视化工具
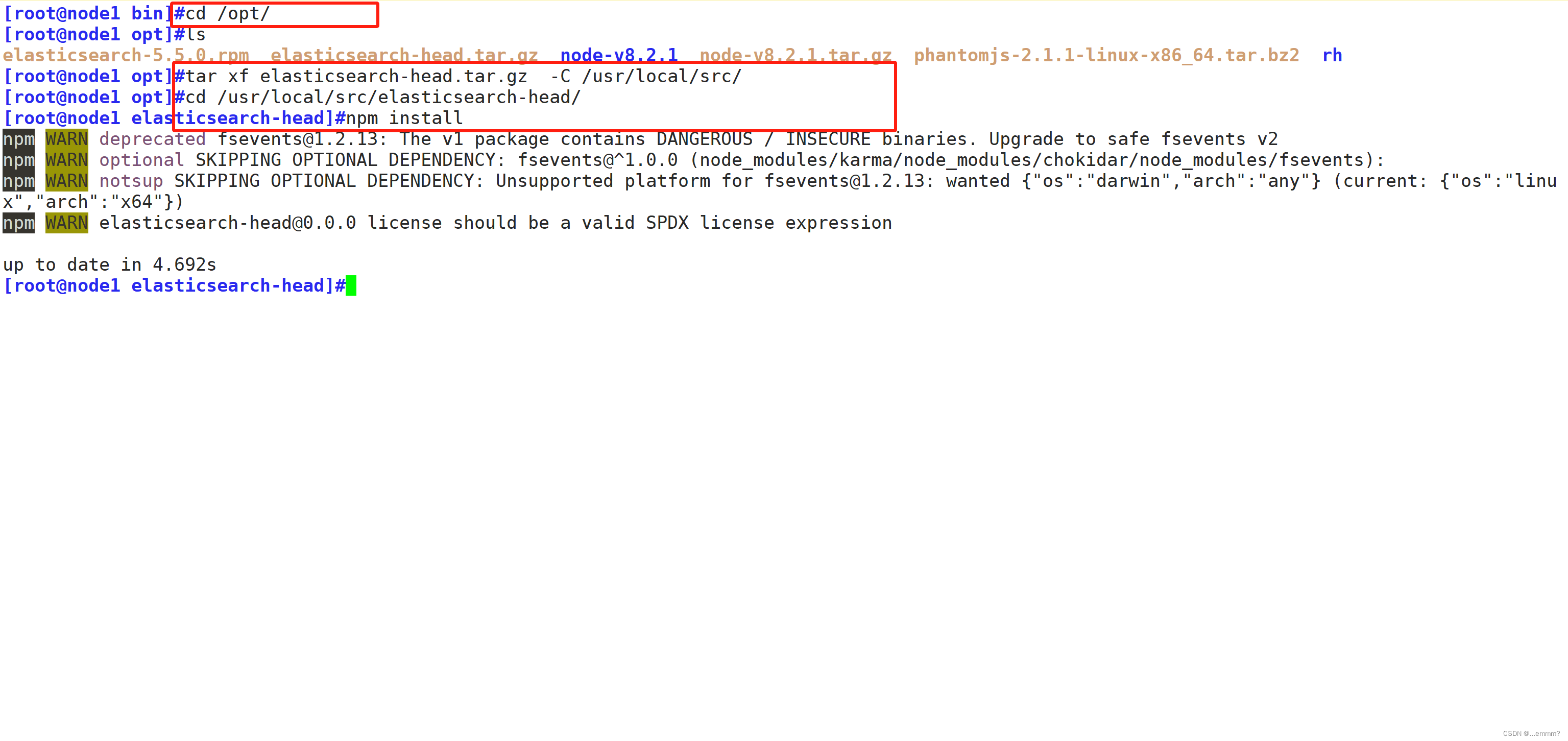
cd /opt
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install#修改elasticsearch主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml_bak
vim /etc/elasticsearch/elasticsearch.yml--末尾添加以下内容--
http.cors.enabled: true #开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有#重新启动elasticsearch
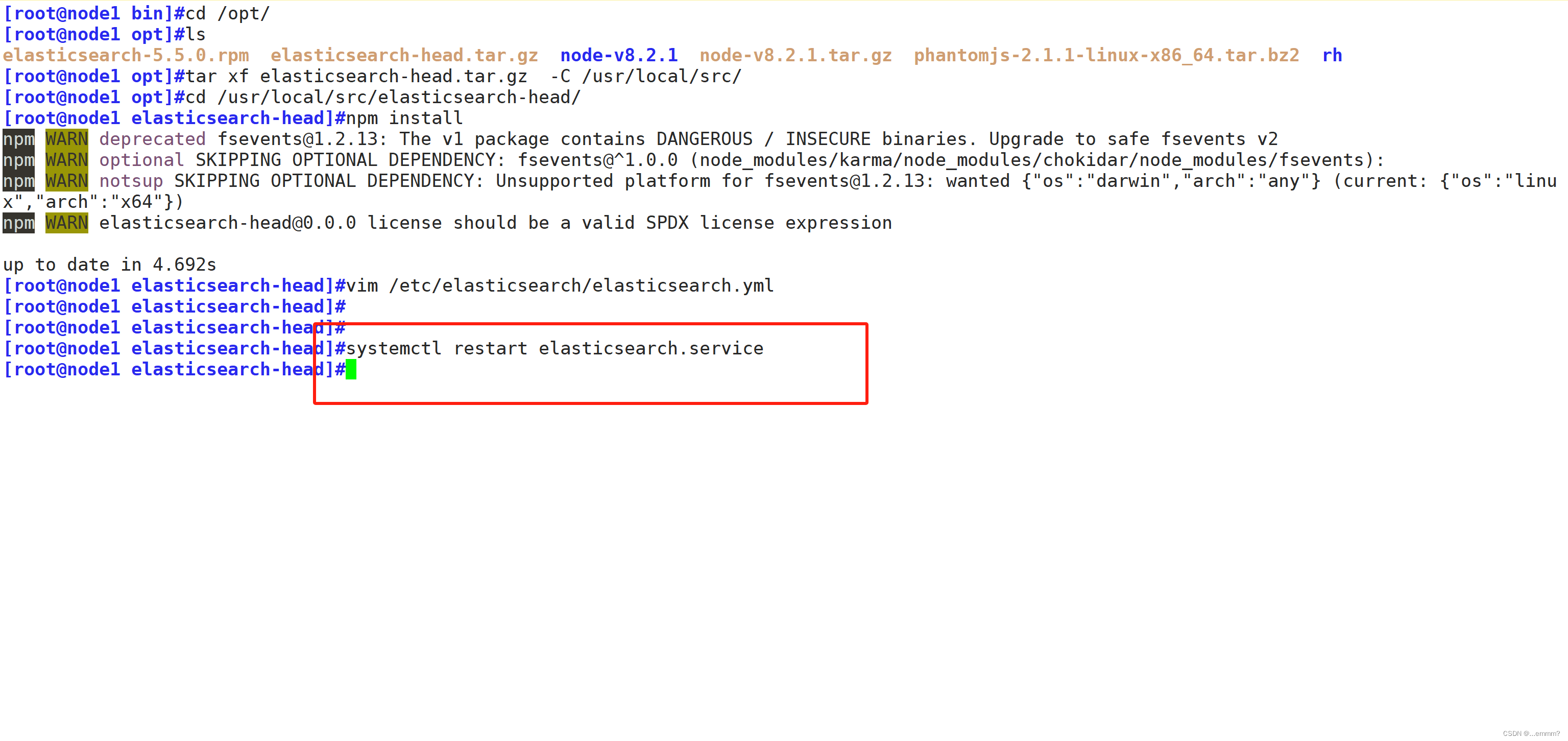
systemctl restart elasticsearch#启动 elasticsearch-head 服务,必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败
cd /usr/local/src/elasticsearch-head/
npm run start &#elasticsearch-head 监听的端口是 9100
netstat -natp |grep 9100#通过浏览器查看 Elasticsearch 信息
192.168.94.7:9200
192.168.94.8:9200









在apache节点部署logstash
#apache节点部署logstash,用于apache日志信息并发送到elasticsearch#更改主机名
hostnamectl set-hostname apache#安装apache服务(httpd)
yum install httpd -y
systemctl start httpd#切换到/opt下
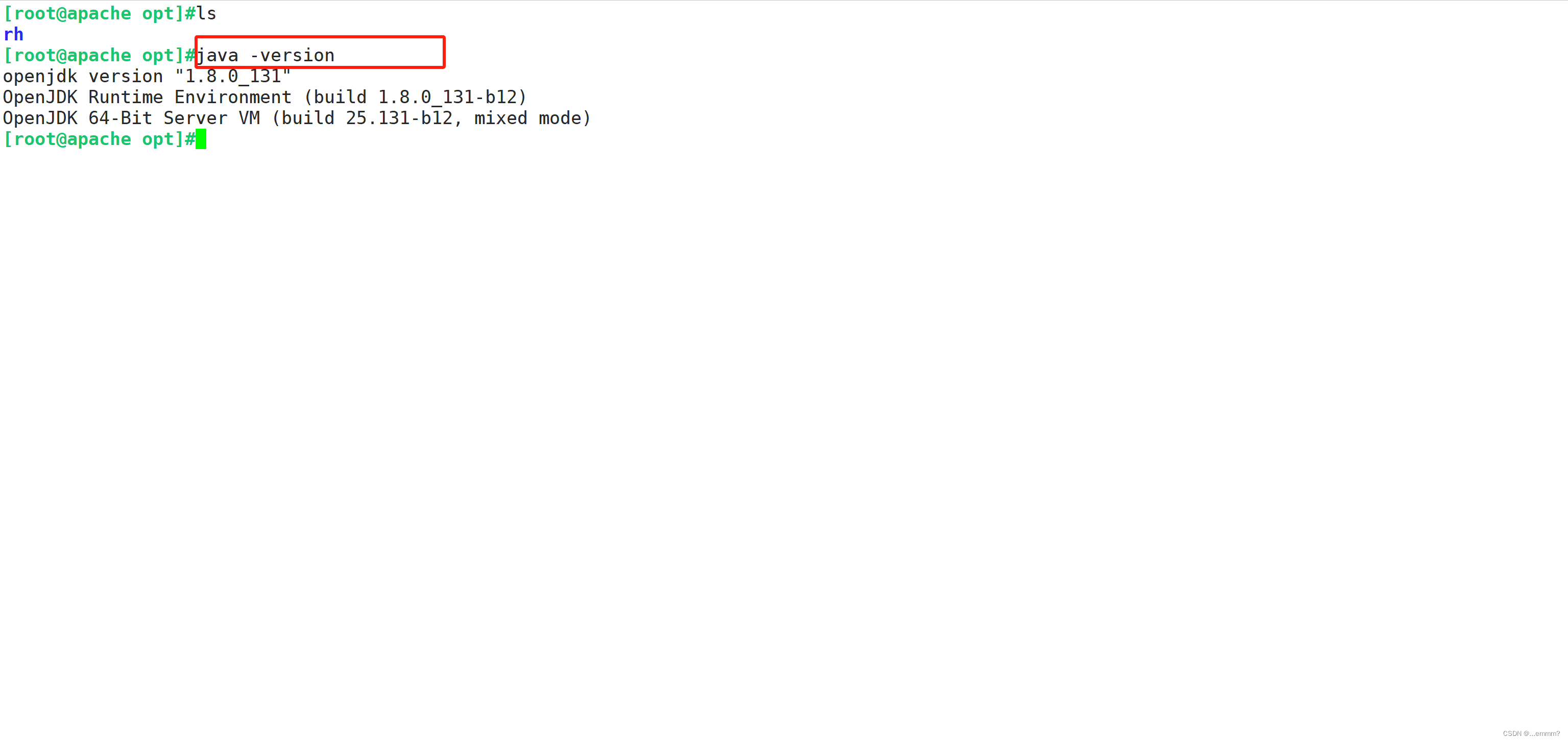
cd /opt#检测java环境,openjdk即可
java -version #将rpm包放在opt下,安装logstash,没有可以去官网获取
cd /opt
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
systemctl enable logstash.service#为logstash 做软连接
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/#测试 LogstashLogstash 命令常用选项:
-f:通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。
-e:从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。
-t:测试配置文件是否正确,然后退出。定义输入和输出流:
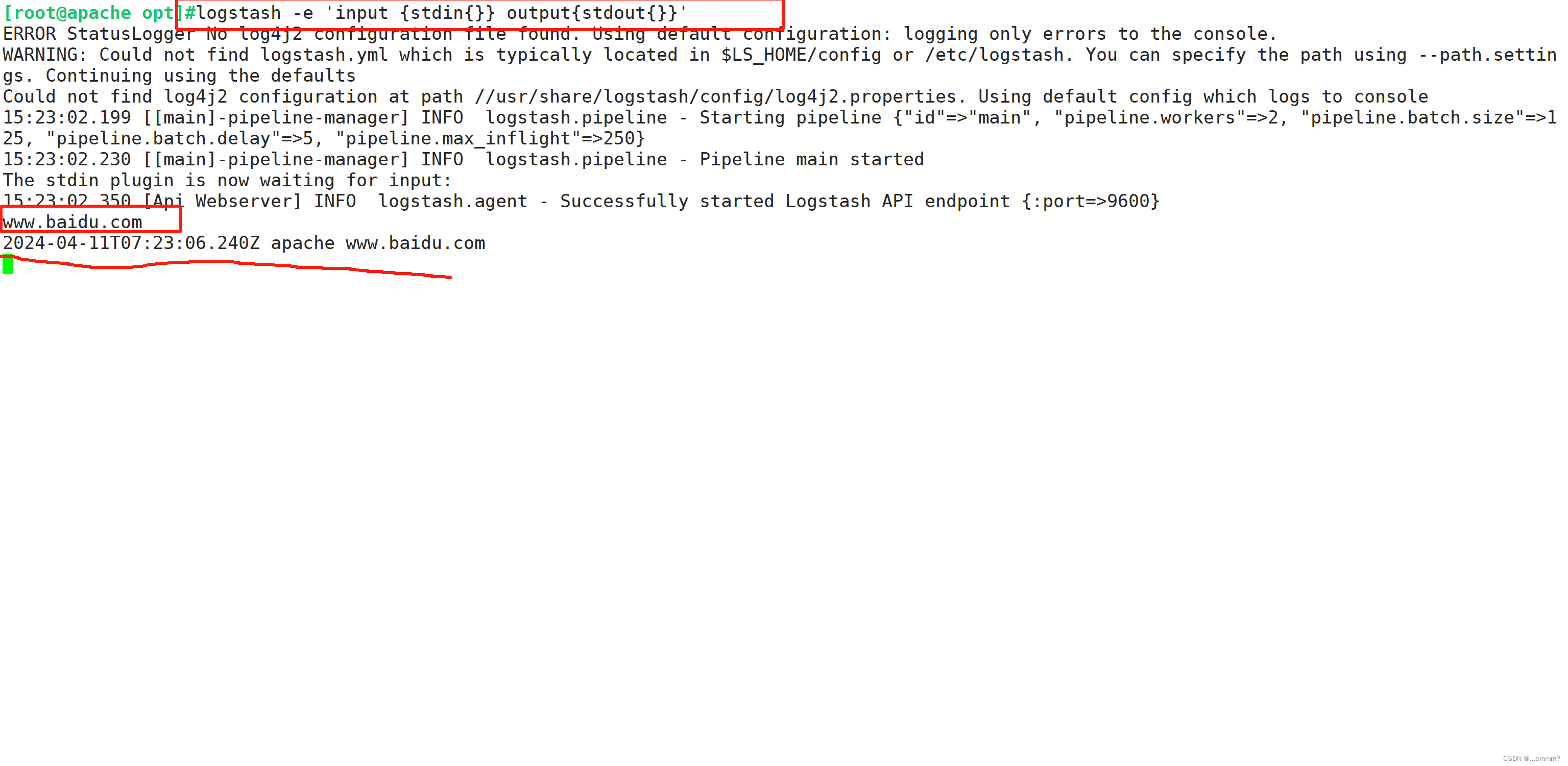
#输入采用标准输入,输出采用标准输出(类似管道)
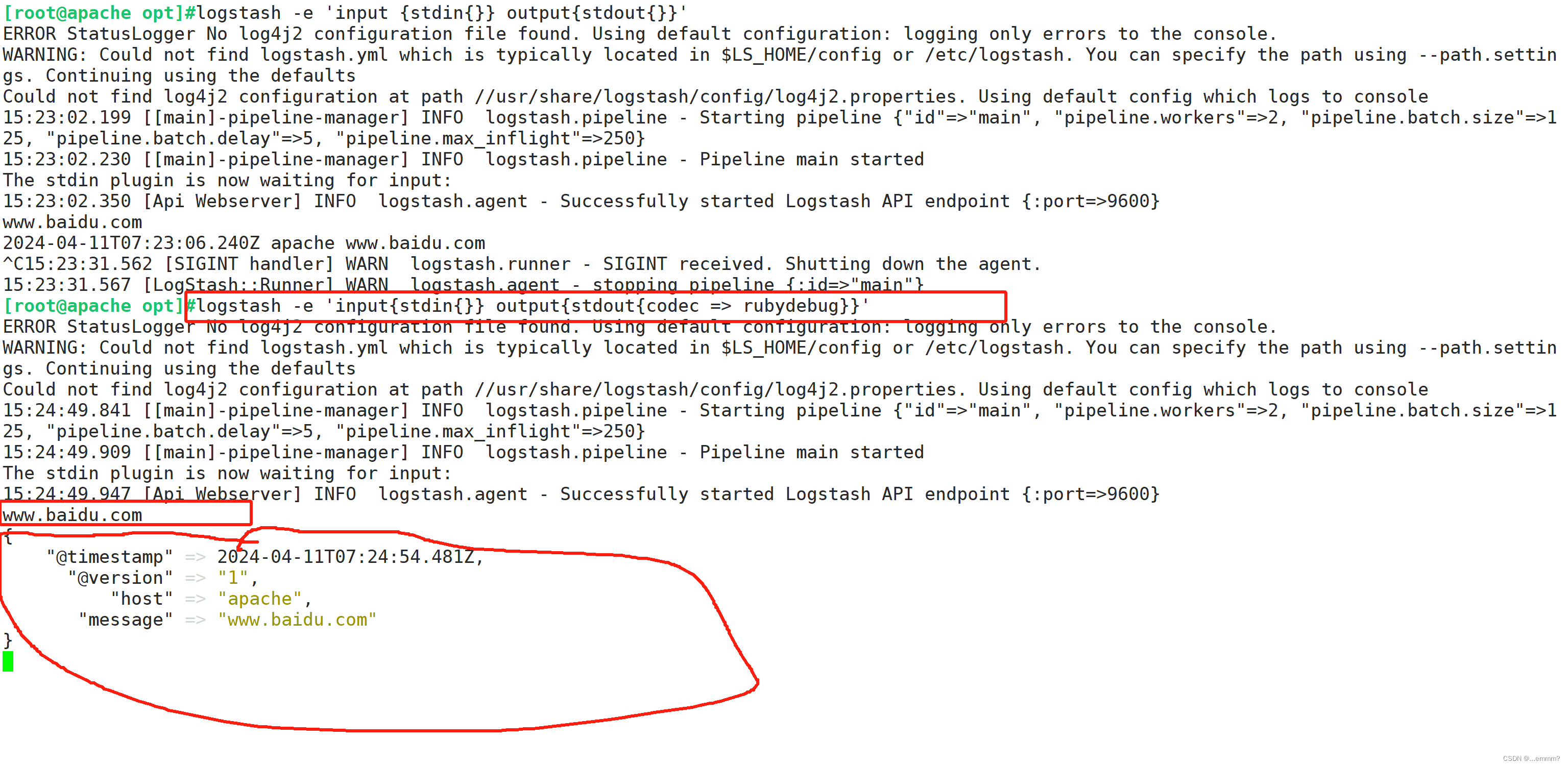
logstash -e 'input { stdin{} } output { stdout{} }'
......
www.baidu.com #键入内容(标准输入)
2020-12-22T03:58:47.799Z node1 www.baidu.com #输出结果(标准输出)
www.sina.com.cn #键入内容(标准输入)
2017-12-22T03:59:02.908Z node1 www.sina.com.cn #输出结果(标准输出)#使用 rubydebug 输出详细格式显示,codec 为一种编解码器
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
......
www.baidu.com #键入内容(标准输入)
{"@timestamp" => 2020-12-22T02:15:39.136Z, #输出结果(处理后的结果)"@version" => "1","host" => "apache","message" => "www.baidu.com"
}使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.10.13:9200"] } }'输入 输出 对接
......
www.baidu.com #键入内容(标准输入)
www.sina.com.cn #键入内容(标准输入)
www.google.com #键入内容(标准输入)//结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器访问 http://192.168.10.13:9100/ 查看索引信息和数据浏览。#修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。
#让logstash可以读取文件
chmod +r /var/log/messages #编写配置文件
vim /etc/logstash/conf.d/system.confinput{file{path => "/var/log/messages" #指定要收集的日志的位置type => "system" #自定义日志类型标识 start_positionn => "beginning" #表示从这开始}
}output{elasticsearch{ #指定输出到elasticsearchhosts => ["192.168.94.7:9200"] #指定elastisearch服务器地址和端口index => "system-%{+YYYY.MM.dd}" #指定输出到elasticsearch的索引格式 }
}#重新启动logstash
systemctl restart logstash 浏览器访问 http://192.168.10.13:9100/ 查看索引信息




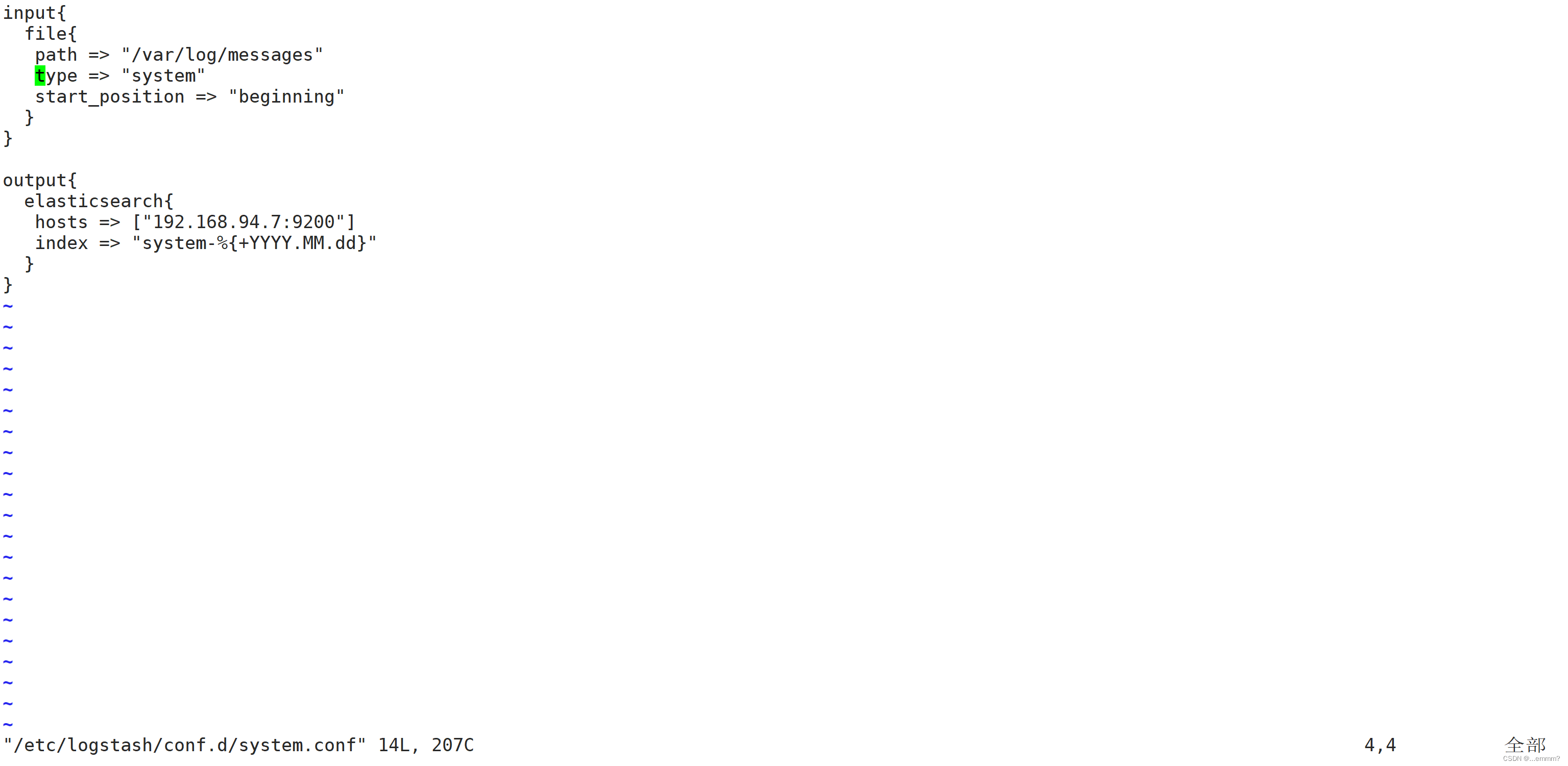


在node1节点搭建kibana(也可以找一台新机器)
#在node1节点安装kibana
cd /opt
#将rpm包放在opt下
#安装kibana
rpm -ivh kibana-5.5.1-x86_64.rpm#设置kibana的配置文件
#打开配置文件
vim /etc/kibana/kibana.yml#具体配置
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.url: "http://192.168.94.7:9200"
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"#启动kibana服务
systemctl start kibana.service
systemctl enable kibana.service#查看端口号
netstat -natp|grep 5601#验证
在浏览器输入 192.168.94.7:5601
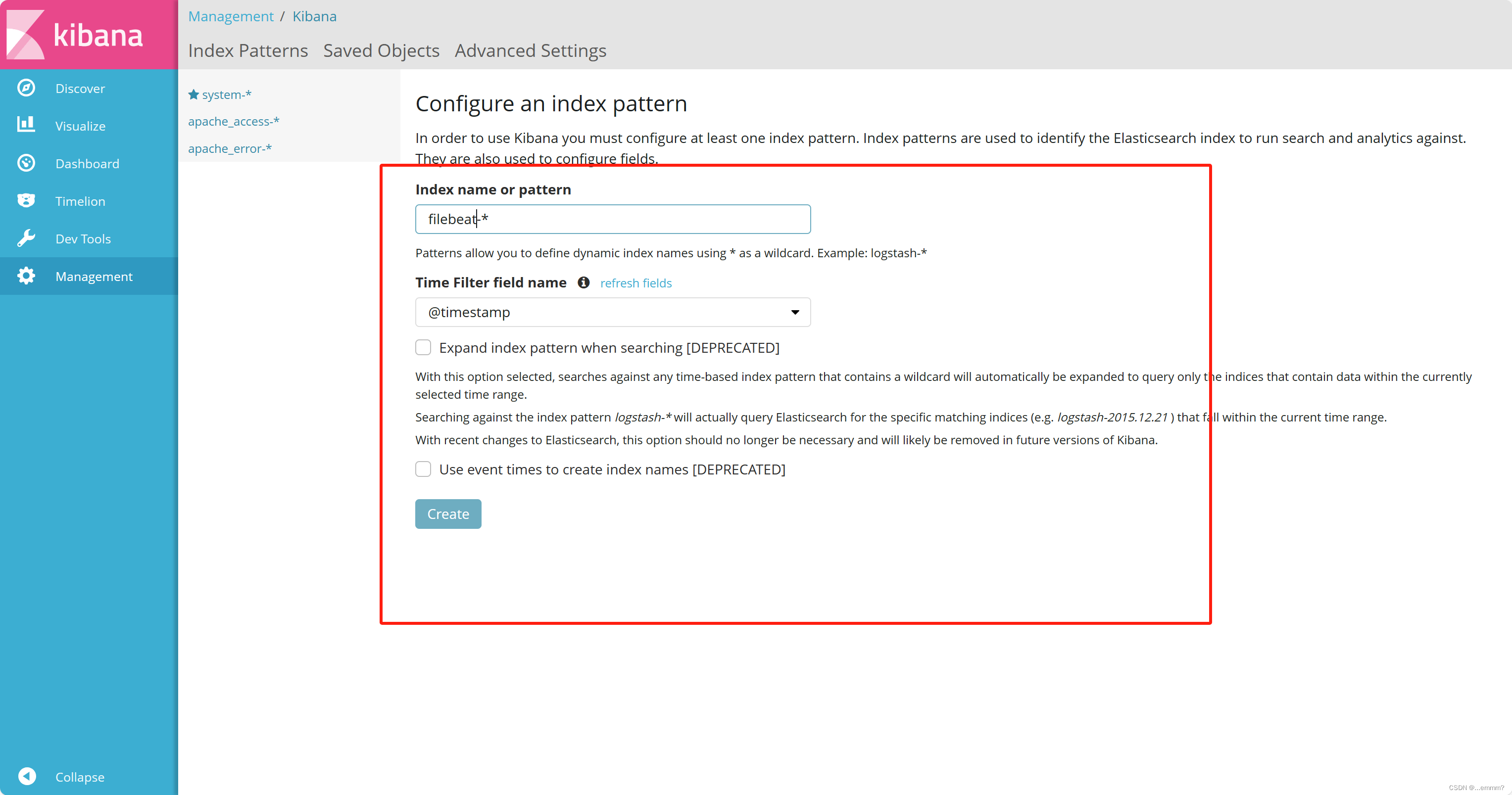
在 Index name or pattern 的框内输入 system-*单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果





配置apache端
#将Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
#编辑配置文件
vim /etc/logstash/conf.d/apache_log.confinput {file{path => "/etc/httpd/logs/access_log"type => "access"start_position => "beginning"}file{path => "/etc/httpd/logs/error_log"type => "error"start_position => "beginning"}
}
output {if [type] == "access" {elasticsearch {hosts => ["192.168.10.13:9200"]index => "apache_access-%{+YYYY.MM.dd}"}}if [type] == "error" {elasticsearch {hosts => ["192.168.10.13:9200"]index => "apache_error-%{+YYYY.MM.dd}"}}
}#热加载新的子配置文件apache
logstash -f /etc/logstash/conf.d/apache_log.conf#前往kibana查看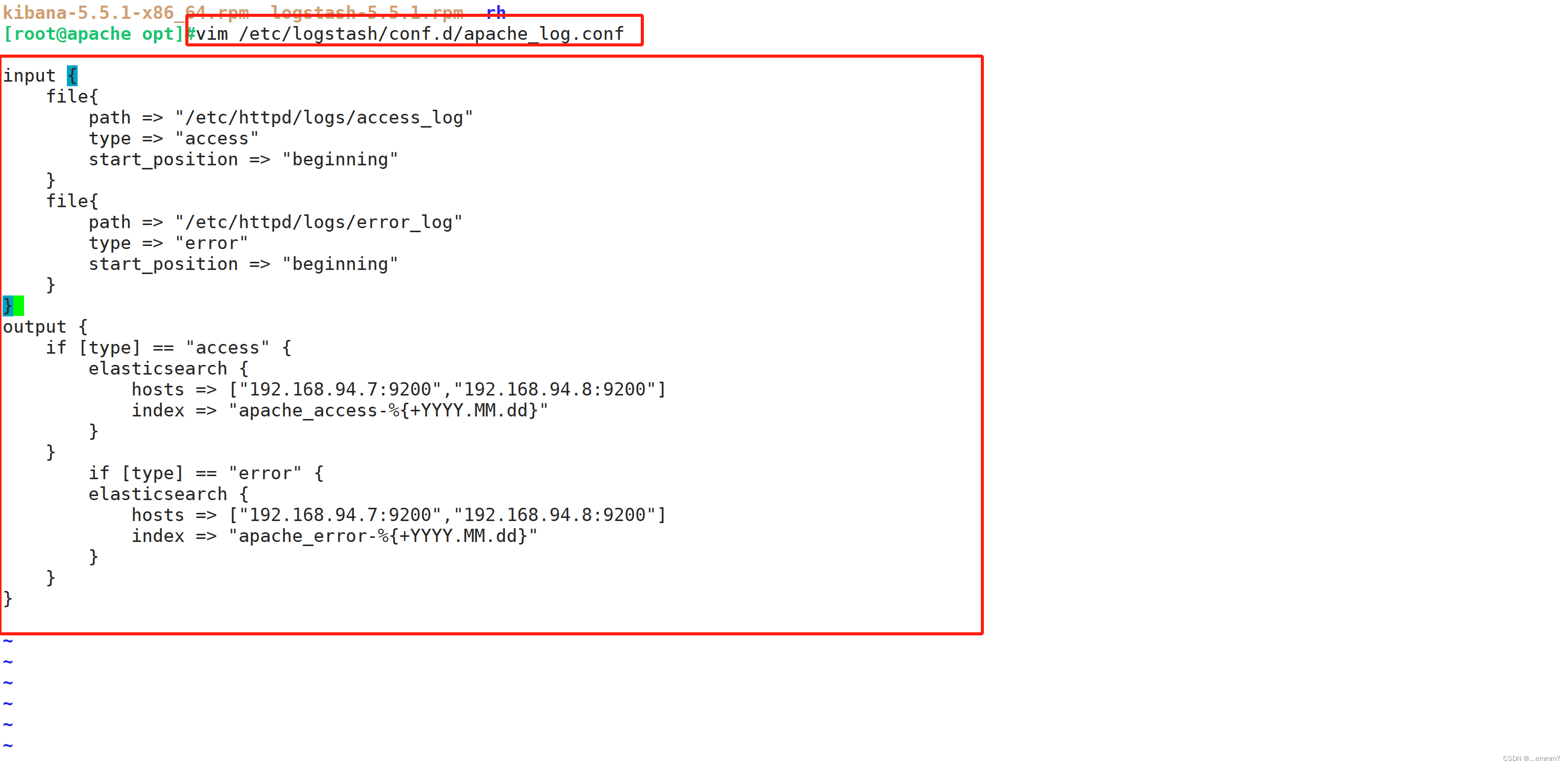

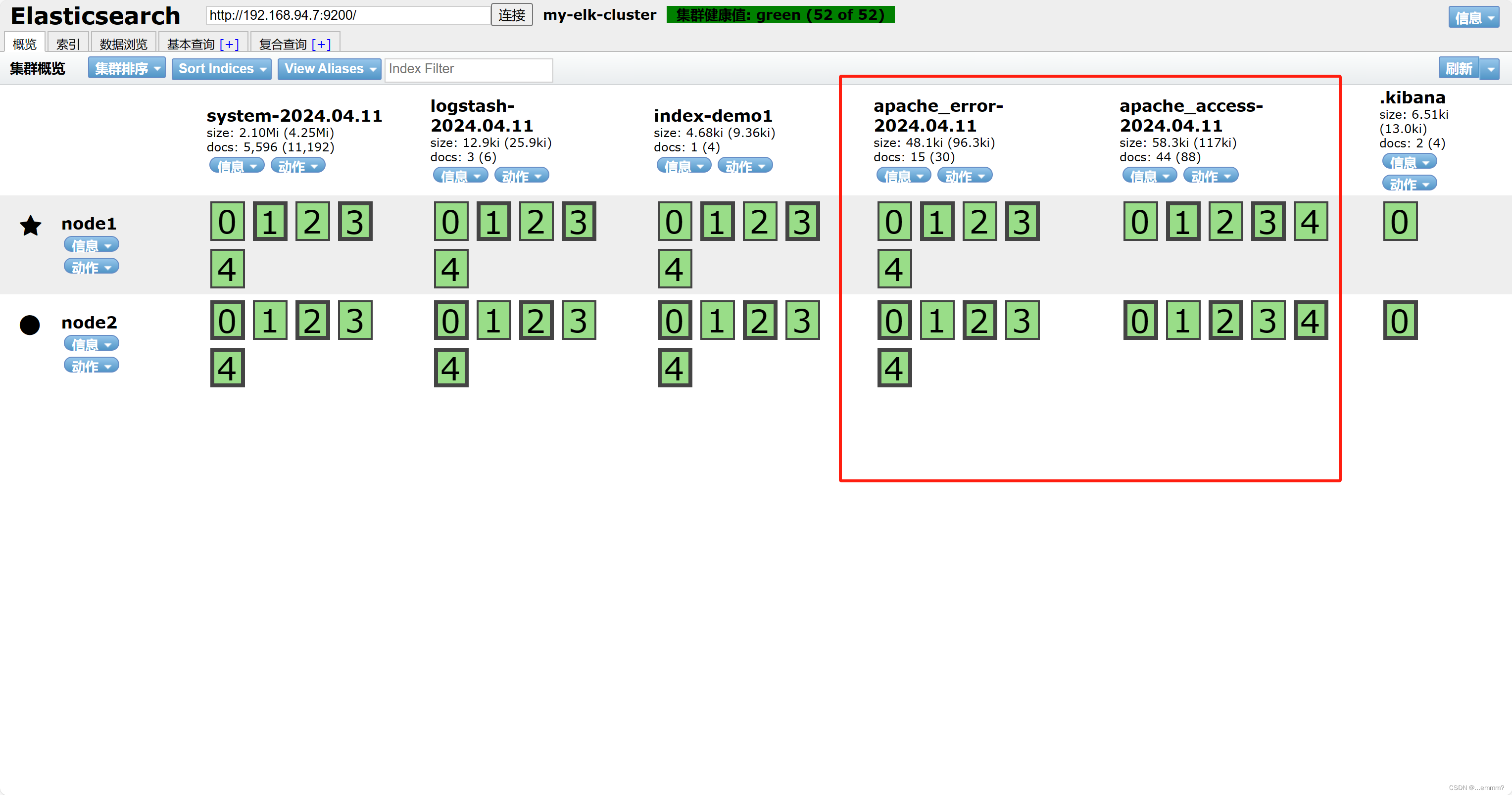
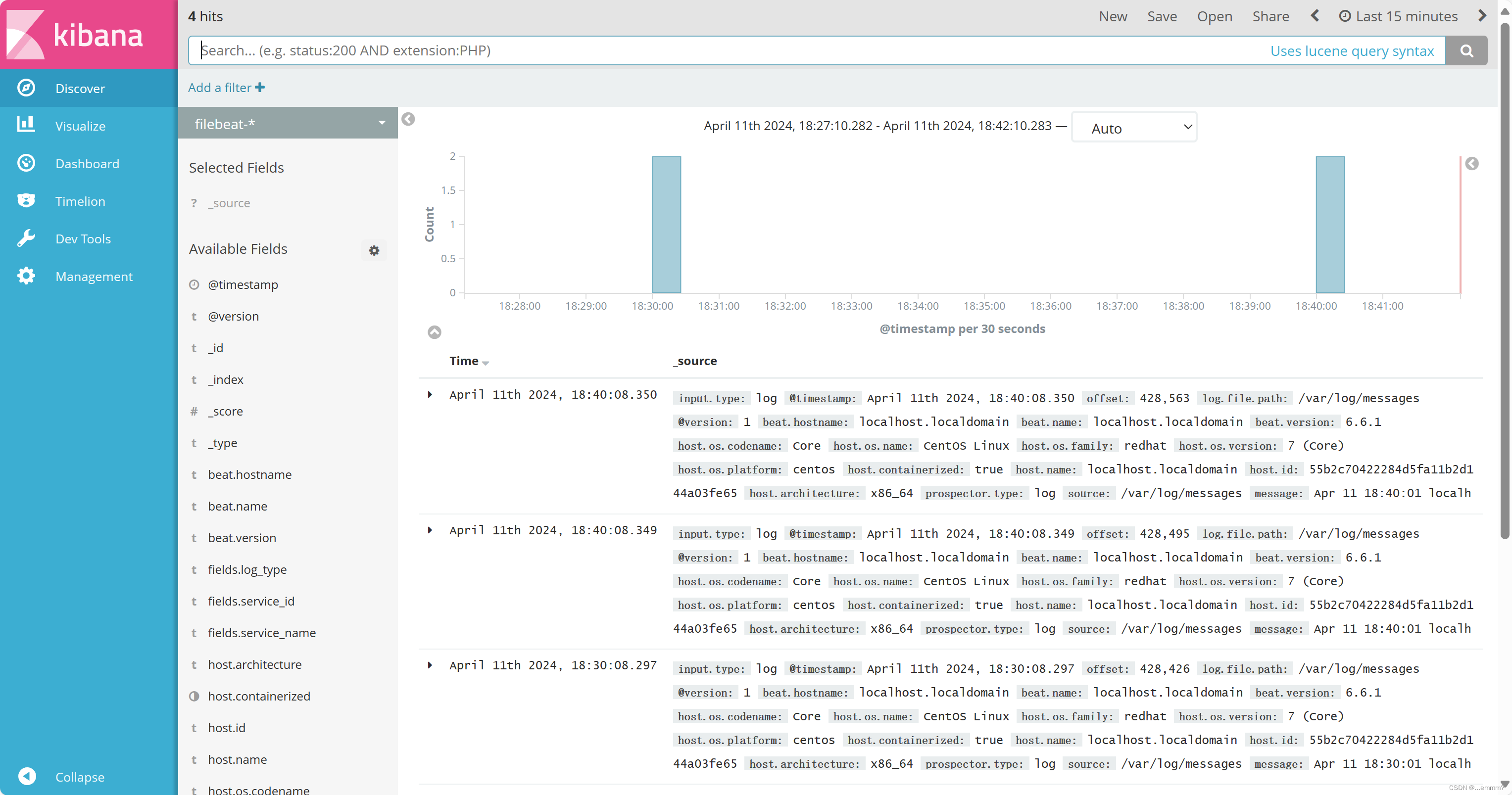
看看elasticsearch是否添加了apache
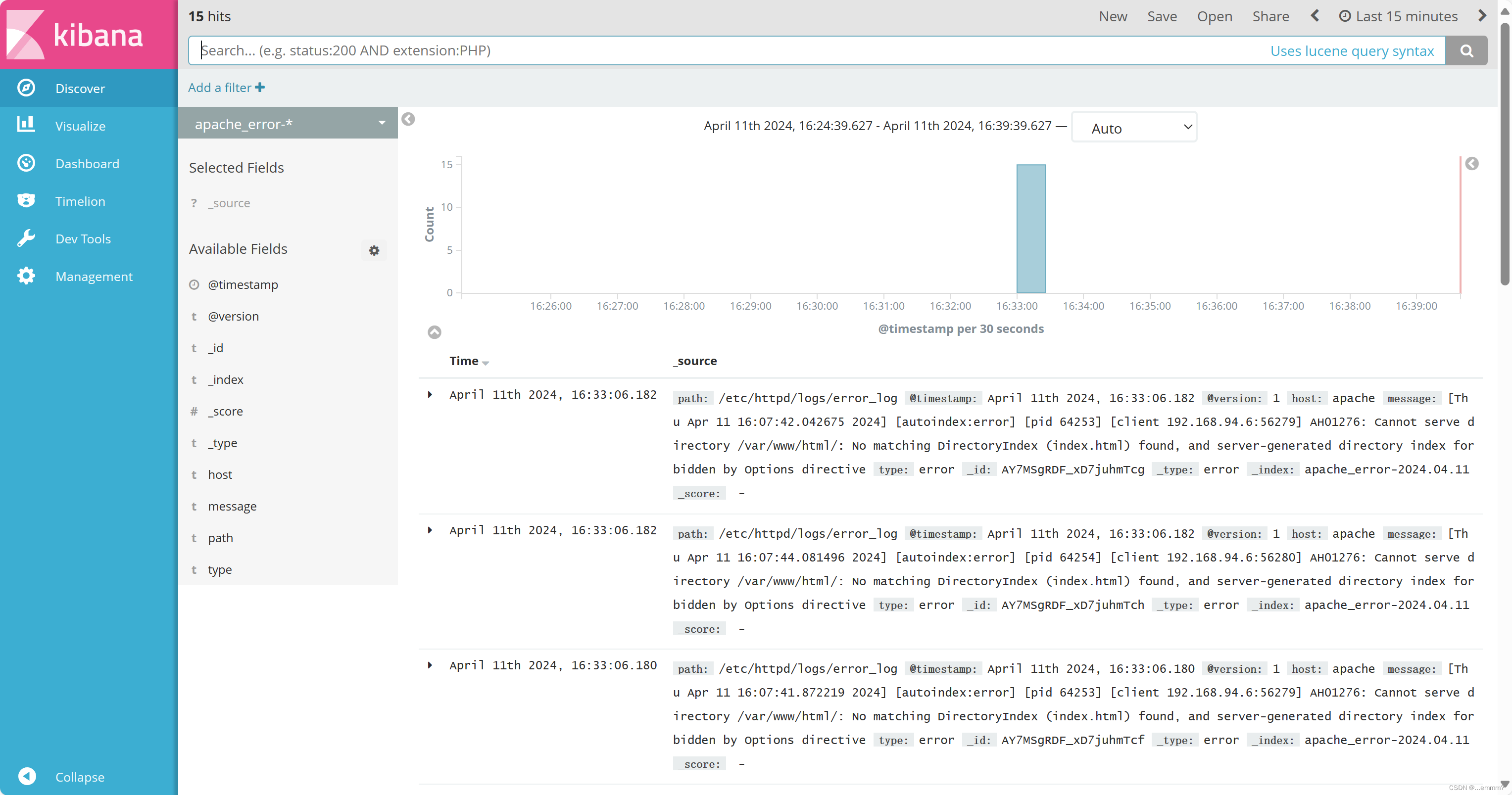
查看kibana



搭建ELFK
Filebeat 的作用
由于 logstash 会大量占用系统的内存资源,一般我们会使用 filebeat 替换 logstash 收集日志的功能,组成 ELFK 架构
ELFK 工作流程
filebeat 将日志收集后交由 logstash 处理
logstash 进行过滤、格式化等操作,满足过滤条件的数据将发送给 ES
ES 对数据进行分片存储,并提供索引功能
Kibana 对数据进行图形化的 web 展示,并提供索引接口
| 主机名 | ip地址 | 需安装的软件 |
| filebeat | 192.168.94.10 | filebeat |
#关闭防火墙和核心防护
systemctl stop firewalld
setenforce 0#切换到opt下,将rpm包放在此处
cd /opt#安装filebeat
rpm -ivh filebeat-6.6.1-x86_64.rpm#备份配置文件
cp /etc/filebeat/filebeat.yml /etc/filebeat/filebeat.yml_bak#修改配置文件
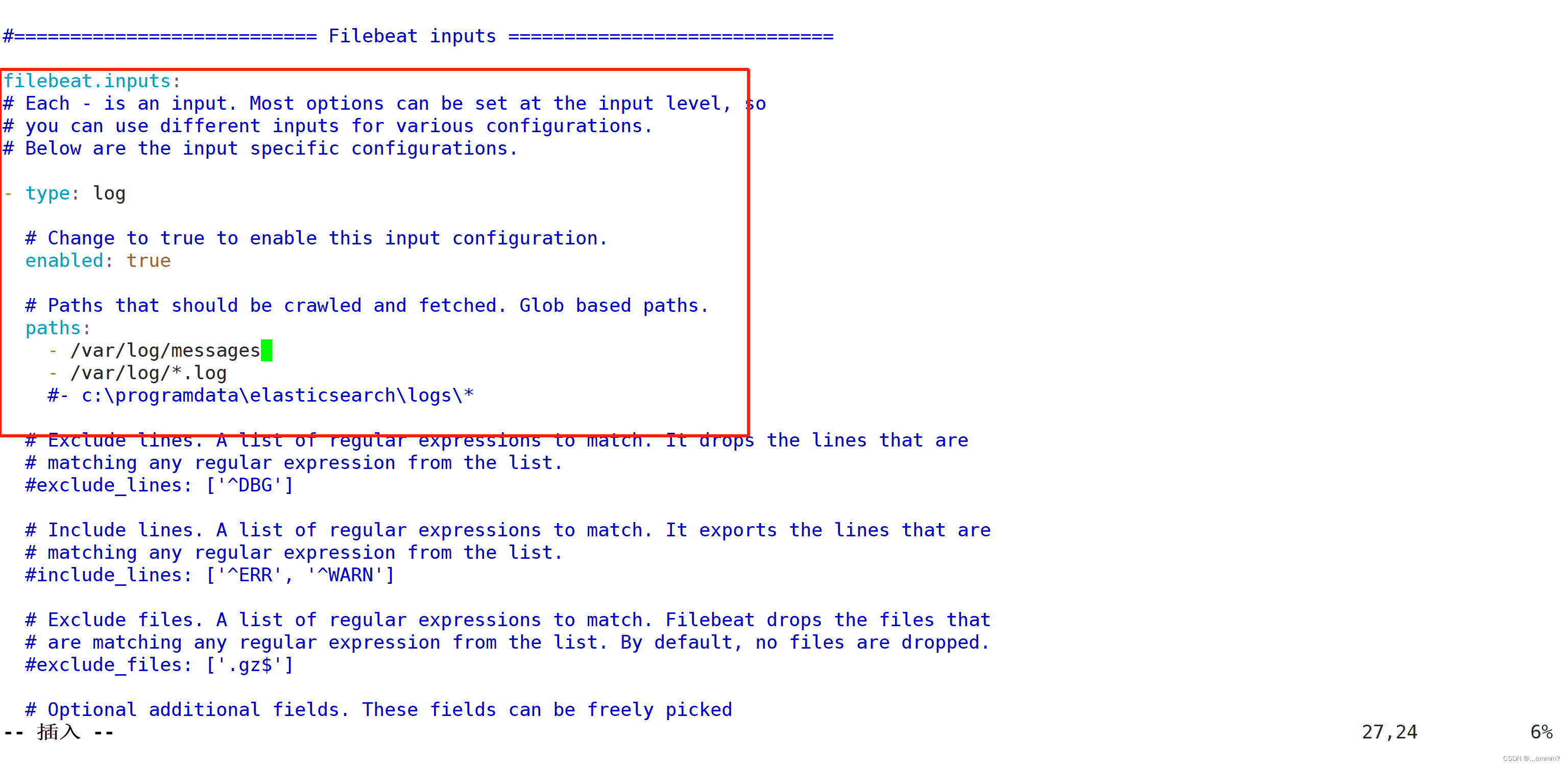
vim /etc/filebeat/filebeat.ymlfilebeat.prospectors:
- type: log #指定 log 类型,从日志文件中读取消息enabled: truepaths:- /var/log/messages #指定监控的日志文件- /var/log/*.logfields: #可以使用 fields 配置选项设置一些参数字段添加到 output 中service_name: filebeatlog_type: logservice_id: 192.168.94.10--------------Elasticsearch output-------------------
(全部注释掉)----------------Logstash output---------------------
output.logstash:hosts: ["192.168.94.9:5044"] #指定 logstash 的 IP 和端口#启动 filebeat
systemctl start filebeat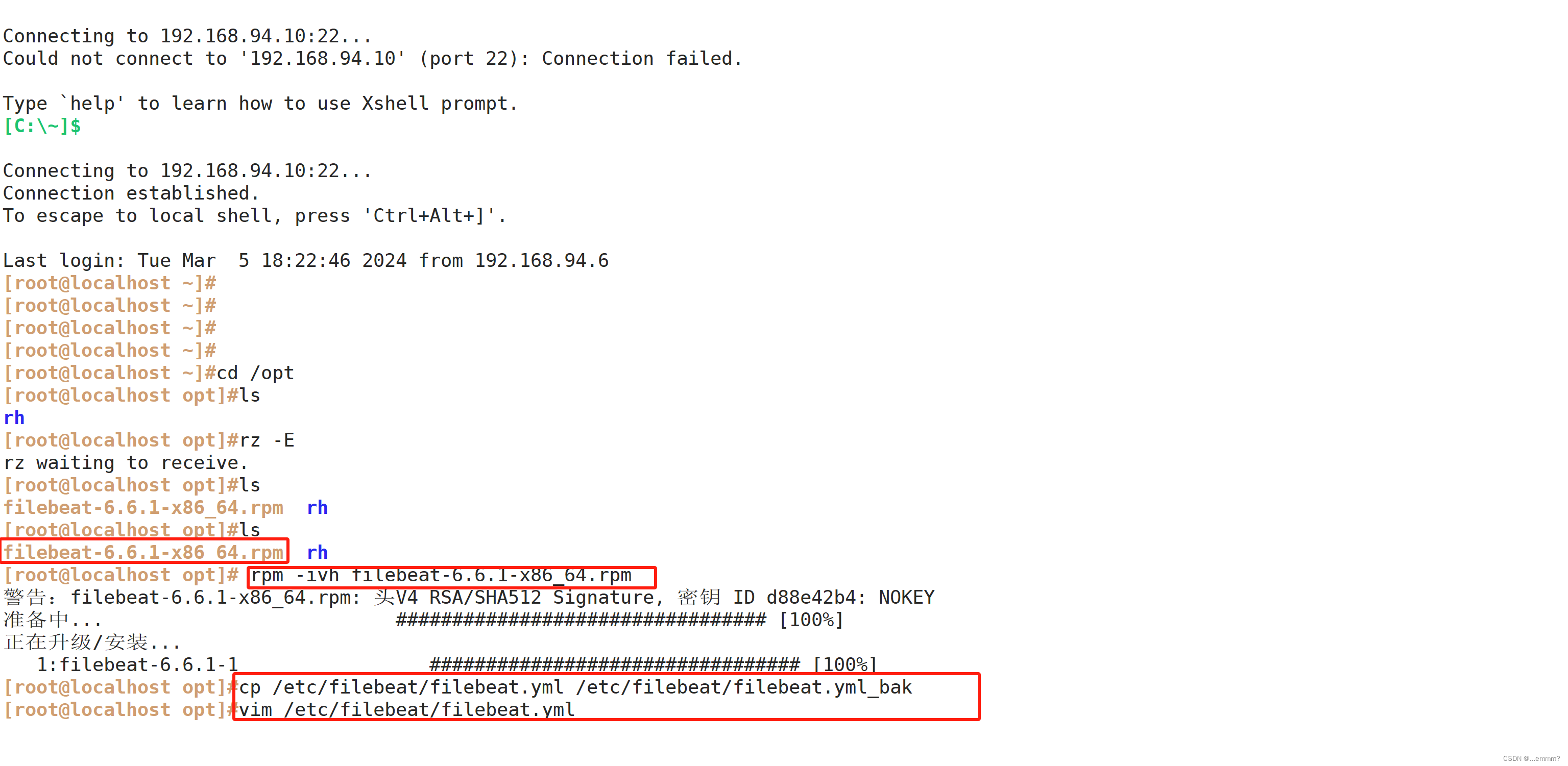


apache端配置
#在 Logstash 组件所在节点上新建一个 Logstash 配置文件
#新建一个配置文件
vim /etc/logstash/conf.d/logstash.conf#写入如下配置
input {beats {port => "5044"}
}
output {elasticsearch {hosts => ["192.168.94.7:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}#启动 logstash
logstash -f logstash.conf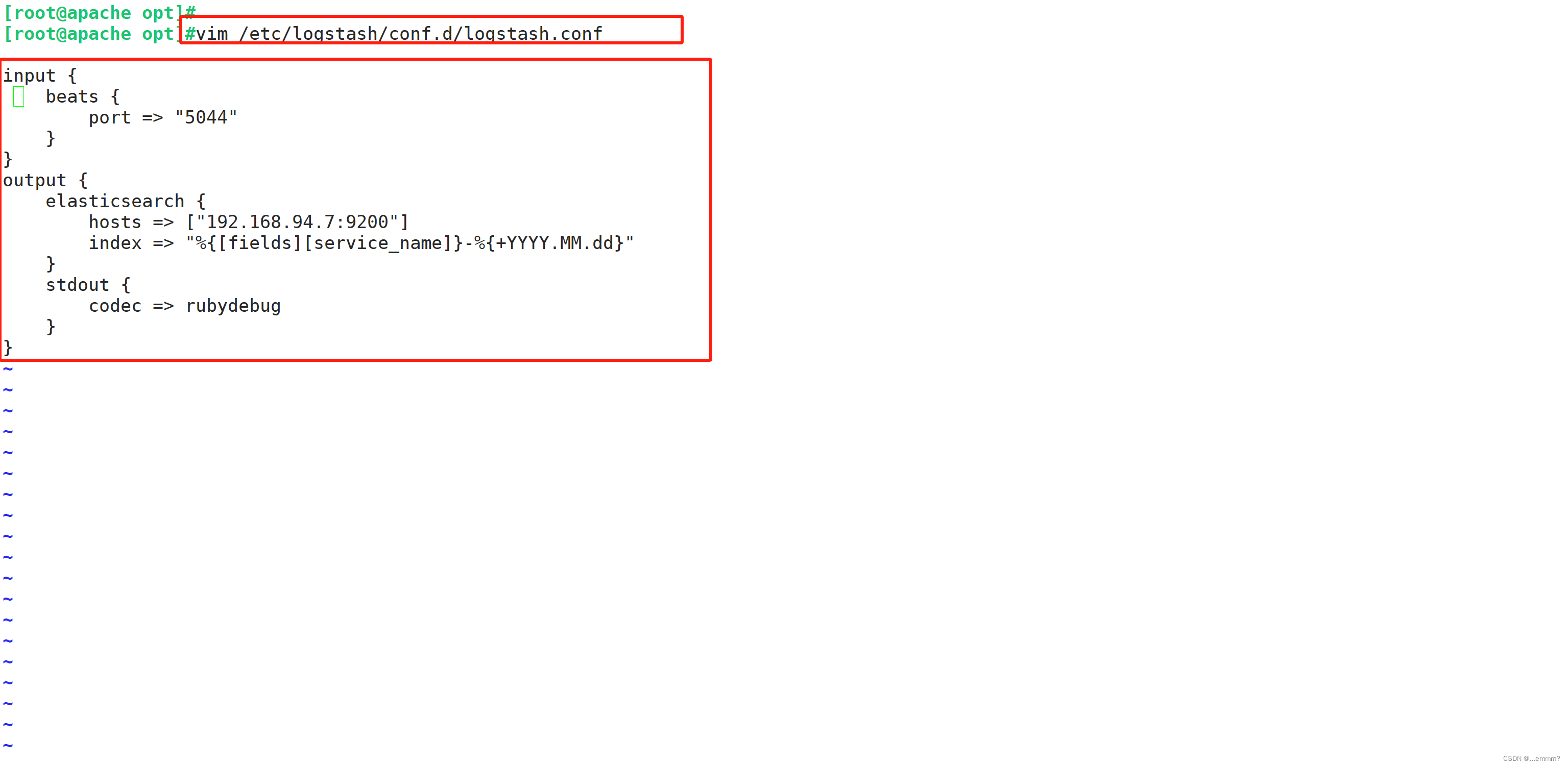


这篇关于ELK,ELFK日志收集分析系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





