本文主要是介绍RTL书写与延迟、面积、功耗、布线,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RTL书写与延迟、面积、功耗、布线
延迟
设计方法
- 将延迟较大的信号放在最后一个选择器上,从而隐藏其较大的延迟。
- 对电路的修改不应该影响其原有的逻辑。
if语句输入信号延迟
- 提取输出
- 提取条件
//修改前
module mult_if(
input a,b,c,d,
input [3:0] sel,
output reg z);
always@(*)beginz = 1'b0;if(sel[0])z = a;if(sel[1])z = b;if(sel[2])z = c;if(sel[3])z = d;
end
endmodule
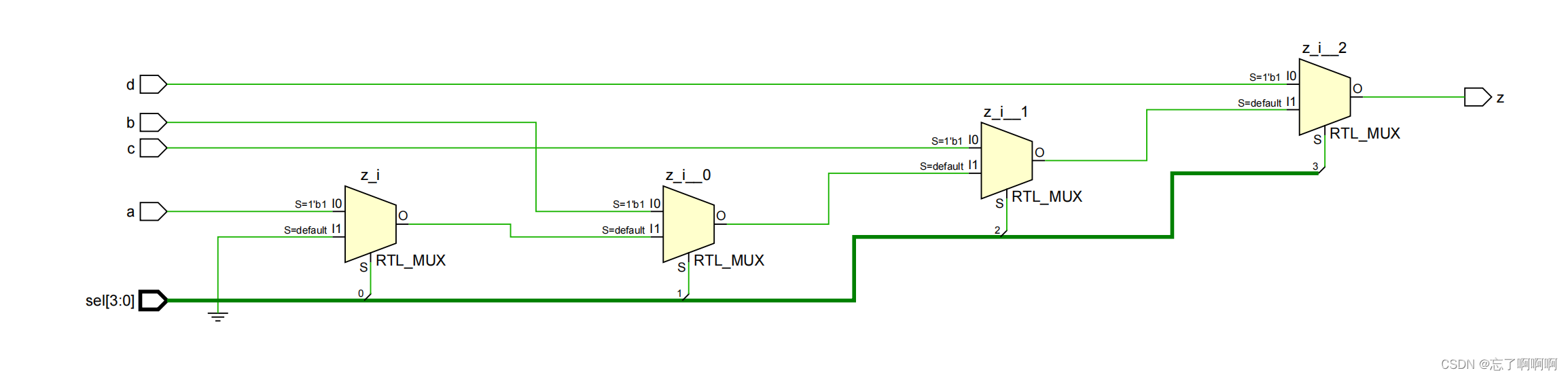
//如果如果b信号来的最晚
//修改后
always@(*)beginz = 1'b0;if(sel[O])z = a;if(sel[2])z = c;if(sel[3])z = d;if(sel[1]&~(sel[2] | sel[3]))z = b;//提取了分支输出和分支条件,不影响原电路的优先级,但增加了电路的面积。
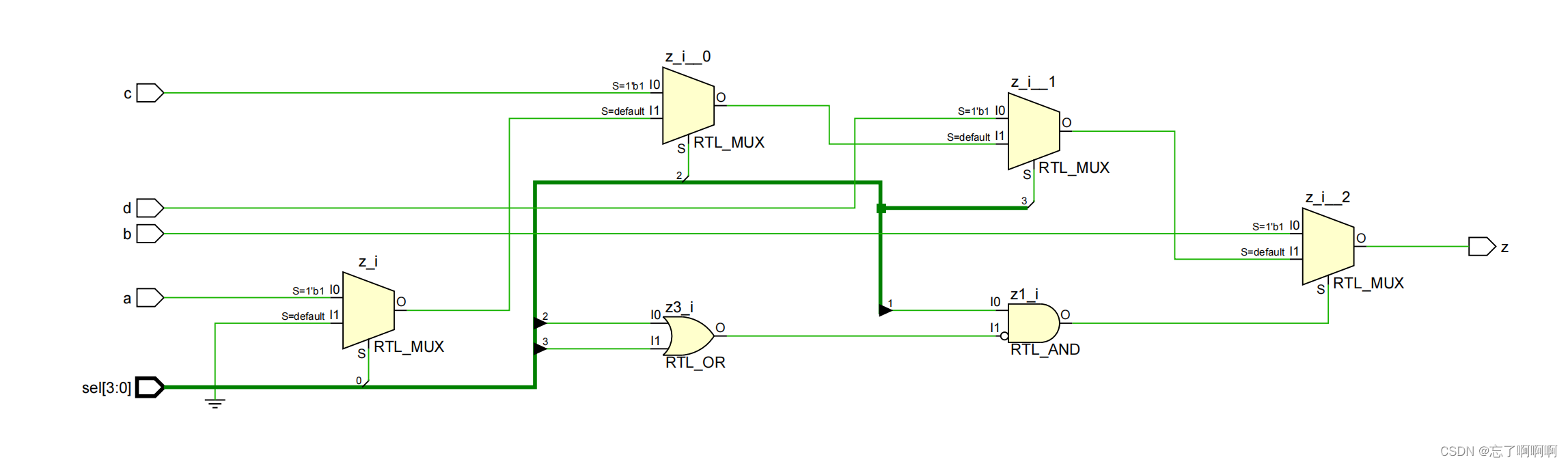
if语句控制信号延迟
- 提取延迟信号所在分支输出,作为最后一级的选择器的一个输入信号。
- 提取出去延迟分支后的电路输出,作为最后一级选择器的一个输入信号。
- 提取延迟信号所在分支的执行条件,作为最后一级选择器的选择信号。
单if语句嵌套case语句,case语句的分支来的比较晚。
-
将case中延迟最大的数据支路,放到最后一级MUX中作为一个输入信号。
-
提取延迟信号所在分支的执行条件,作为最后一级选择器的选择信号。
-
对if else和case中的其他支路条件进行提取,作为最后一级选择器的选择信号。
先加后选和先选后加
- 如果选择信号来的较晚可以选择先加后选
调整信号计算顺序
module mult_if(
input [3:0] A,B,C,D,
//input [3:0] sel,
output reg [3:0] Z);
always@(A,B,C,D) beginif(A + B < 'd24)Z <= C;elseZ <= D;
end
endmodule
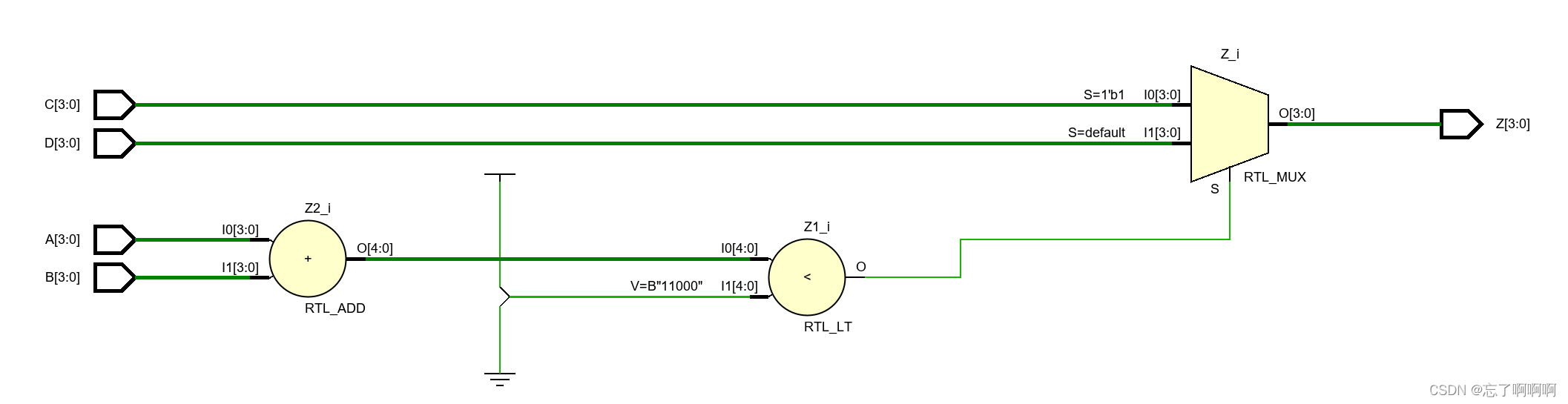
//如果A信号晚到,对计算顺序进行优化
module mult_if(
input [3:0] A,B,C,D,
//input [3:0] sel,
output reg [3:0] Z);
always@(A,B,C,D) beginif(A<'d24 - B)Z <= C;elseZ <= D;
end
endmodule
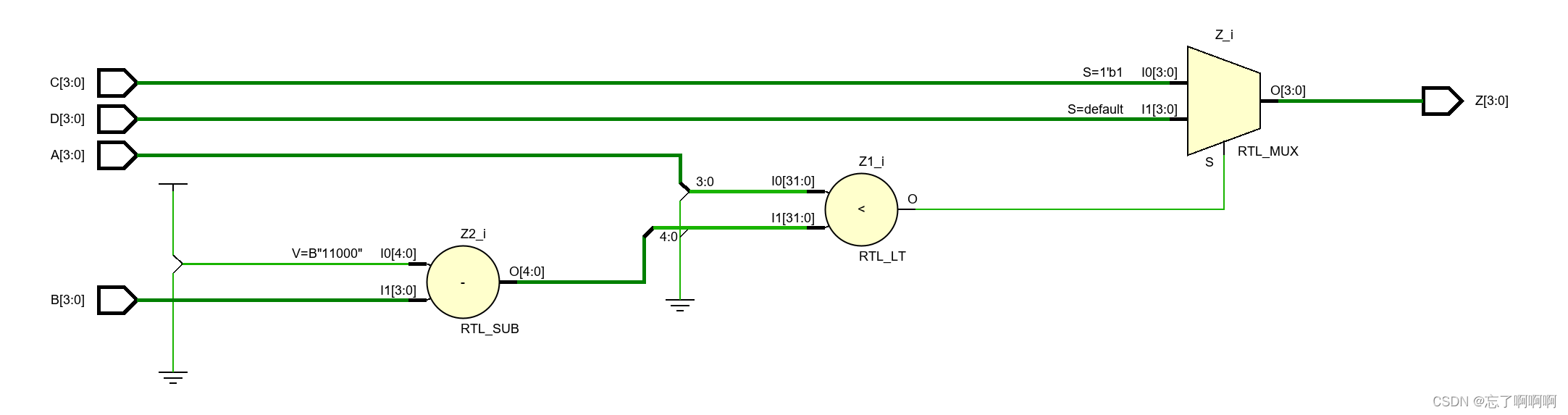
面积
-
减少设计面积意味着成本降低、功耗降低。
-
减少面积的方法:
-
了解使用资源的数量(使用了多少个触发器、加法器、乘法器)。
-
触发器的数量由功能决定,很难减少。
-
了解各种操作符会产生的电路,对组合逻辑进行优化。
-
优化设计中的操作符
-
会产生较大电路的操作符:”+”、“-"、“×”、“÷”。
-
条件语句中的比较运算。
-
设计方法:对于这些操作,首先应该判断其必要性,是否能用更简单的运算代替。
对定值数据优化
-
32的二进制表示:6’b10_0000;
-
对于一个位宽为6的数据A,如果A<32,说明A[5]<0;
-
使用了一个1bit的逻辑门代替了6bit的比较器。
资源共享优化
如果,必须使用复杂的运算符,则应考虑是否可以资源共享。
if(y1>a+b+q)statement1;
if(y2>a+b+r)statement2;
if(y3>a+b+s)statement3;
//优化后,减少了两个加法器sum<=a+b;
if(y1>sum+q)statement1
if(y2>sum+r)statement2
if(y3>sum+s)statement3;
多比特信号
多比特的信号也往往会占用较大的资源,因为使用这些信号的操作都是对所有的比特进行的,相当于成倍使用资源。
观察操作是否需要多比特信号的所有位宽,如果不是,则可以只对需要的部分比特进行操作。
//访问一RAM的地址有8比特,而写入操作时从0开始,每隔32个地址写入一 个值,地址的产生可以有两种写法。//优化前
addr<=addr+'d32
//优化后
addr[7:5]<=addr[7:5]+1'b1;
addr[4:0]<=addr[4:0]+1'b0;功耗
P d = ∑ a f C V 2 P_d=\sum_{}^{}{afCV^2} Pd=∑afCV2
P d P_d Pd:电路割点的功耗总和, a a a:该点电路的反转次数, f f f:电路的工作频率, C C C:该点的电容, V V V:电压值。
-
负载电容c和工作电压v是RTL设计无法改变的因数。
-
RTL级设计降低功耗主要考虑降低电路的翻转频率。
-
组合逻辑产生的毛刺也会大量消耗功耗,但毛刺在设计中无法避免,只能尽量减少毛刺在电路中的传播从而降低功耗。
功耗控制主要措施:
-
使用门控时钟,门控时钟是电路设计最常用也是最有效的方法,在逻辑综合阶段可以让综合工具自行插入。
-
增加使能信号,使得部分电路只有在需要工作时才工作
-
对芯片各个模块进行控制,在需要工作时才工作
-
减少毛刺在电路中的传播,尽量把产生毛刺的电路放在传播路径的最后。另外,可以使用一些减少毛刺的技术。
-
对于有限状态机,可以通过低功耗编码来减少电路的翻转。
//状态转移
A:0101
B:1010
每次转移四个信号发生翻转
A:0101
B:0100
每次转移一个信号发生翻转
门控时钟和增加使能控制的区别:
-
增加使能:电路的信号不在翻转,但时钟每个周期还会继续翻转。
-
门控时钟:直接关掉时钟。(效果更好)
布线
-
布线(routing):根据门级网表的描述实现各个单元的连接,是芯片设计的最后阶段。
-
布线(routing) 是否成功,布局 (placement) 是最关键的因素
-
但即使使用最好的布局工具,还是可能出现无法布通的情况。 出现这种问题,往往要去修改RTL级设计。
-
在RTL编码阶段考虑代码可能对布线产生的影响,从而避免无法布通的情况。
热点
- 热点是指设计的功能需要在一个面积内占用大量的布线资源,会影响布线质量。
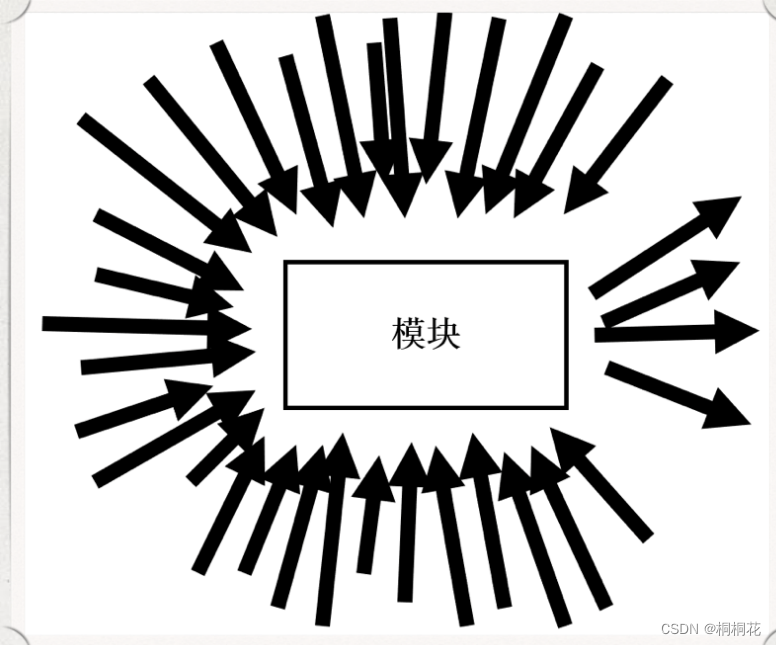
- 热点产生原因:RTL编码时使用了特定的结构,如很大的 MUX。
- 这种结构产生的热点,在综合时导致的延迟无法看出 ,只有到了布线阶段才能给看到其负面影响。
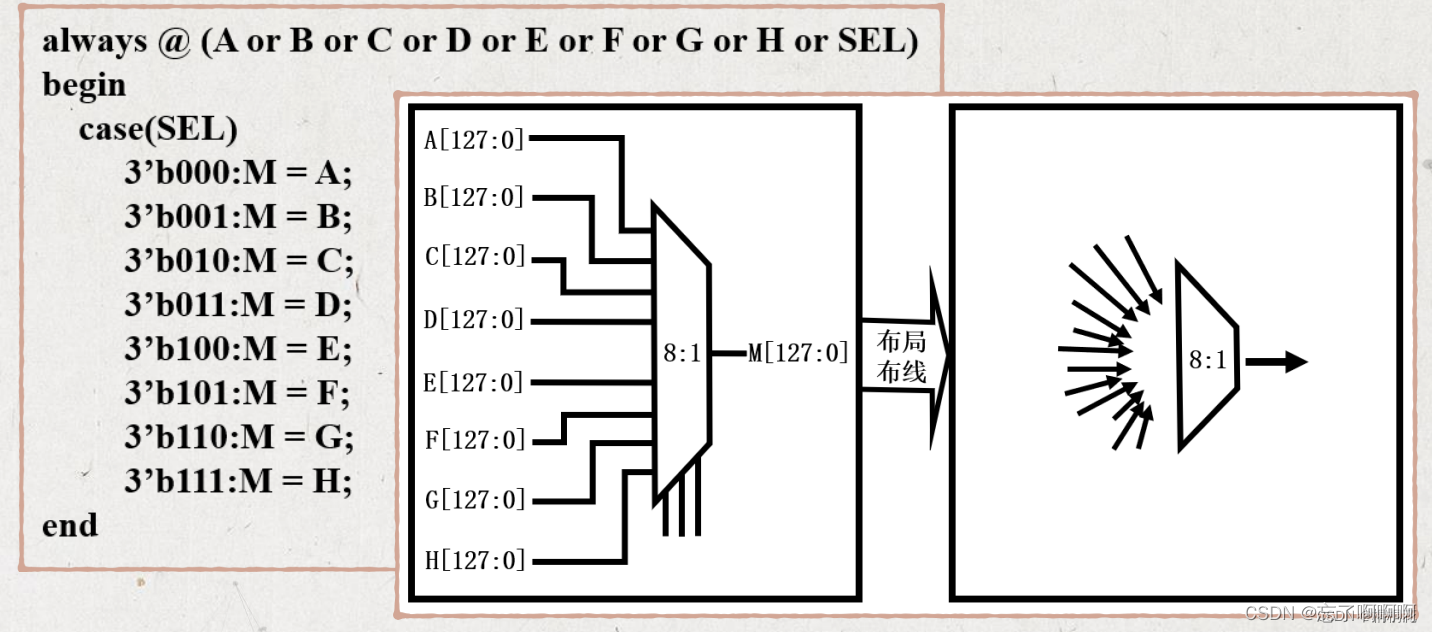
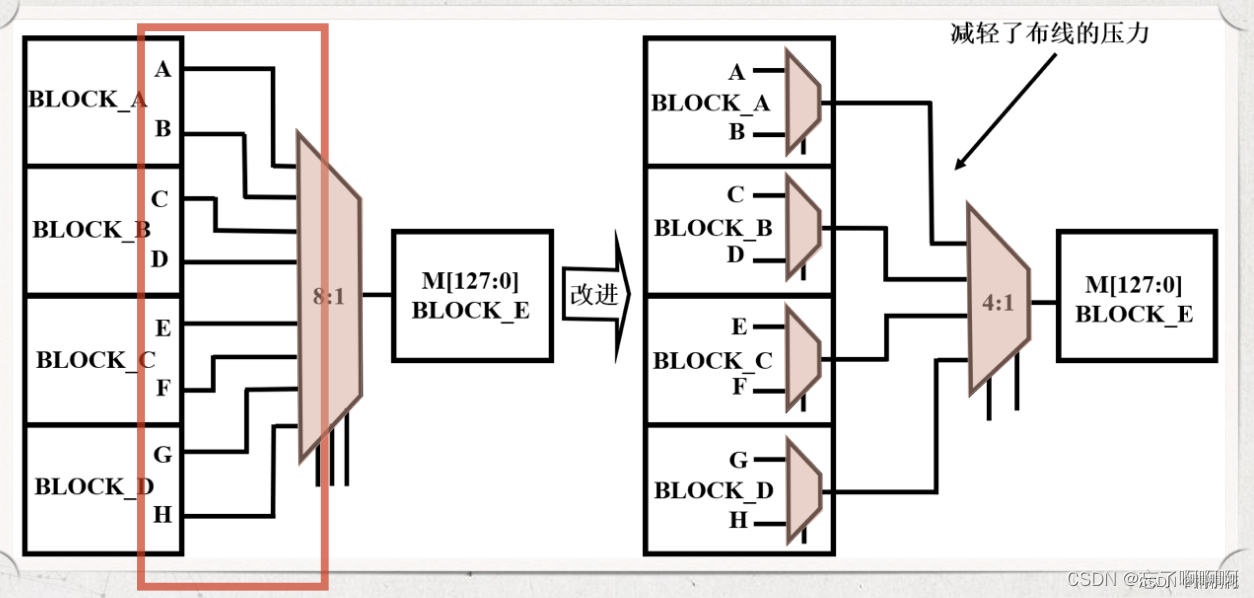
- 设计方法:将一个大的mux分解为多级较小的mux。
参考资料:
芯动力——硬件加速设计方法
可综合风格——在RTL书写中如何考虑延迟、面积、功耗、布线
这篇关于RTL书写与延迟、面积、功耗、布线的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




