本文主要是介绍StockTrading AI小模型股票自动交易系统 转载,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Stock-Trading
StockTrading AI小模型股票自动交易系统
项目文档
Stock-Trading · 语雀
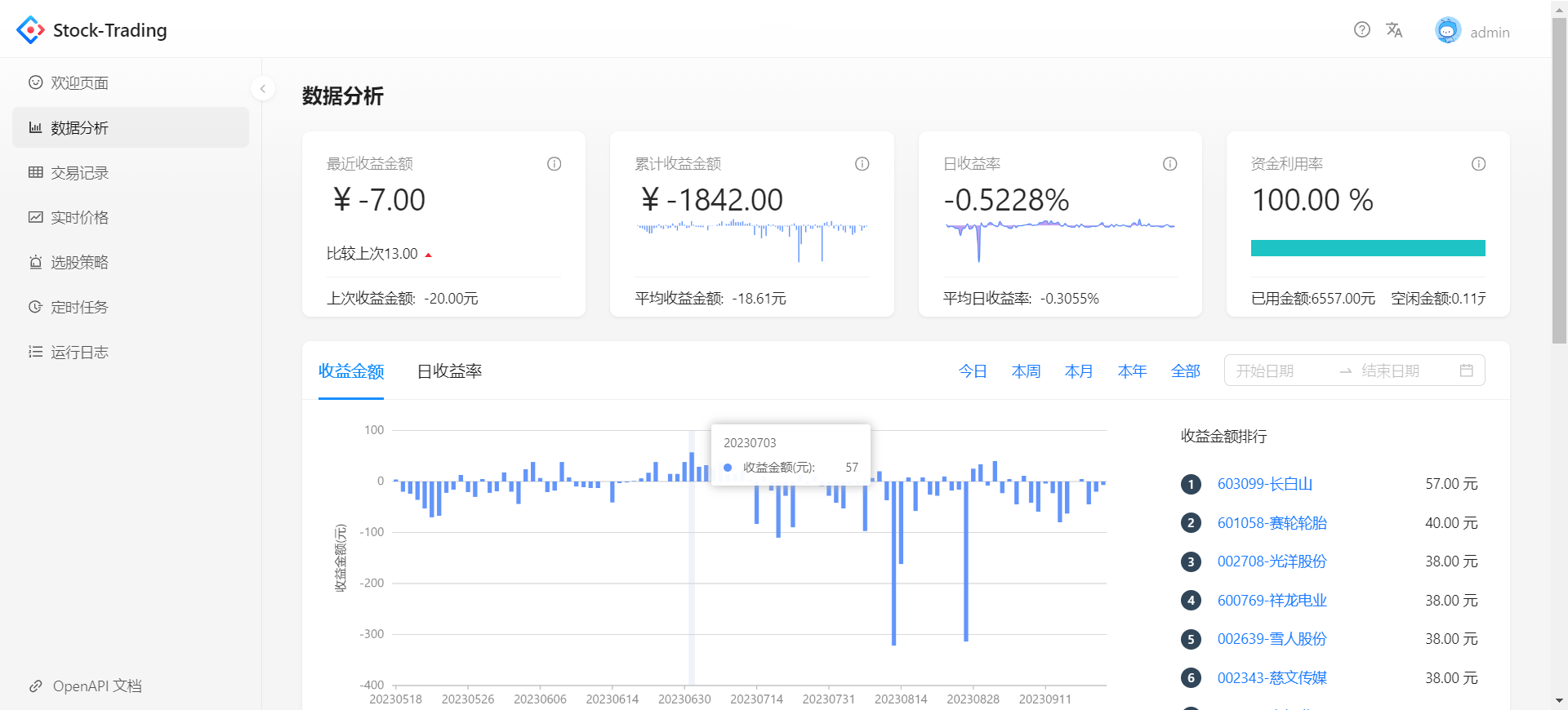
项目展示
功能介绍
- 对接证券平台,实现股票自动化交易
- 使用QuartZ定时任务调度,每日自动更新数据
- 使用DL4J框架实现LSTM模型指导股票买入,采用T+1短线交易策略
- 利用K8S+GithubAction实现DevOps
后期优化方向
- 获得更多股票历史数据用于训练
- 模型超参数调优
- 实现增量训练
- DL4J代码框架优化
项目简介Stock-Trading是一款股票自动交易管理系统,根据人工智能算法模型预测价格来自动买入卖出以获得收益后台项目地址:https://github.com/mwangli/stock-trading前端项目地址:https://github.com/mwangli/stock-front页面展示地址:http://124.220.36.95/user/login
项目背景项目设计原则:最小化设计原则:在满足业务需求的情况下,尽可能地以最简单的方式实现,来减轻项目的复杂度,节约服务器资源,尽可能的使得项目 "精致小巧"技术是为业务服务的,技术是手段而非目标,脱离了业务技术将一文不值工作时间越长,越能体会这句话的含义,学习目的除外本项目是一个面向业务的项目,区别于传统的toB, toC项目,是一个toP(To Person)面向个人的项目业务背景理论:从T+1短线交易的角度来看股票收益是由买入和卖出时的价格来决定,只要卖出时的价格比买入高(不考虑手续费),就能获得正向收益。将某一支股票的交易看做是一个猜大小或者抛硬币猜正反的数字游戏来看待,只要猜对了就赢,猜错了就输,依据概率论,假如能提高股票猜涨跌的准确率,那么就会收益就会越高使用深度学习算法,LSTM长短期记忆人工神经网络,就是为了提猜涨跌的准确率,能根据历史价格走势来预测明天的价格是涨还是跌,选择理论涨幅较高的股买入该项目的的核心出发点,是用机器学习算法,来代替人的决策,来进行股市交易,算法能有效避免人性的弱点,比如永远想等到更高价格再买,结果崩盘,而机器学习算法决策不会。股票市场的价格是由买卖市场决定的,而买卖是由人来进行的,因为人性是共通的,所以价格波动是有规律的,机器学习算法的目的就是为了学习这些规律来做出判断将参与股票交易,看做一场猜大小博弈,参与博弈的双方是自我和其他所有参与股票交易的人,只要我猜对了,我便盈利,盈利的来源便是对方的亏损,至于是谁亏,我并不关心;如果我猜错了,那么我就亏,显然是对方盈利,至于是谁赚了也不重要上面理论的前提是从T+1短线交易的角度出发,针对某一天来看,对比前一天,总是有股票在涨,也总会有股票在跌,只要猜对了就能盈利如果从长期角度来看股票价格会受到国家政策,经济形势,实时新闻等多方面的总和因素影响,这个输入足够庞杂,如果机器学习算法需要学习到里面的规律并做出准确的判断穷尽整个人类现有的计算资源也未必能做到运行环境jdk1.8:不建议使用9及其以上,以为DL4J框架大概率会用到plot画图,会依赖JFrame等高版本被删除的工具centos7.6:腾讯云服务器,2核4G,部署了一套单节点的完整K8S集群以供学习测试,部署过程参考redis, mysql, mongdb:用于进行数据持久化技术框架前端:React, AntDesignPro, Umi等后端:Springboot, Mybatis-plus, QuartZ, WebSocket等模型:DL4J,java环境下的深度学习算法支持库部署方式java -jar 命令后台启动docker + Jenkins流水线部署k8s devOps自动部署功能说明对接证券平台,实现真实的股票自动化交易使用QuartZ定时任务调度,每日自动执行交易流程使用DL4J框架实现LSTM模型指导股票买入,采用T+1短线交易策略包含简单认证授权功能利用K8S+GithubAction实现CICD+DevOps利用WebSocket实现后台日志实时推送前端集成用户登录,数据分析,任务调度,日志查询等功能目录说明
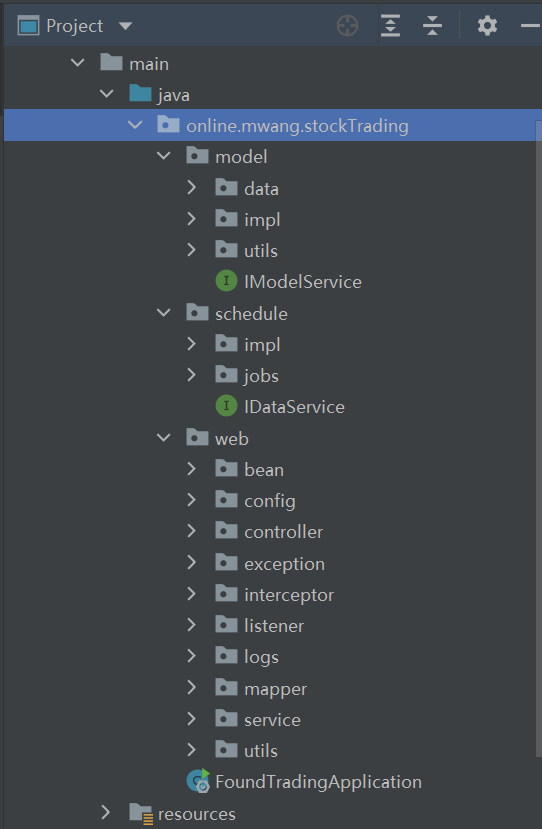
模型部分:包含LSTM模型训练和预测的相关代码工作流部分:负责调度每天的任务,来实现买入卖出逻辑Web部分:包含SpringBoot Web项目的常见项目结构业务说明采用工作流驱动,每个流程按照时间线互相独立执行,有自己的输入输出,工作流之间解耦合为什么采用这种设计:在早期的版本中,将所有的业务流程写在一个方法中,按照时间线顺序执行,下一个流程依赖上一个流程的输出或者结果,比如买入需要先卖出,否则没有可用资金;买入之前还需更新实时价格,计算评分等等;这写流程执行的过程中,如果前面的流程执行出错或者没有产生对应的输出,就会导致后面的流程也出错,为了保证程序的健壮性,嵌套了大量IF-ELSE的逻辑判断,核心流程方法代码长达一千二百行,代码的可读性非常差,设计不够简洁优雅采用工作流模式的目的,是为了将这些相对独立的流程解耦合,哪怕前面的流程出错,对后面的流程影响也不大,因为每个流程的输入输出已经进行了持久化。例如,今天的价格预测任务执行失败了,评分数据更新不及时,仍然可以使用上次预测的评分来执行买入工作流,虽然不准但是不会出错将这些独立的工作流按照合理的时间线组织起来,就能完成每天的业务流程正常运转且程序不会出错导致异常崩溃任务执行时序图:
实时价格同步任务
股票卖出任务
模型预测任务
股票买入任务
订单同步任务
历史价格同步任务
模型训练任务
MySQL
Mongo
MySQL
Mongo
磁盘
MySQL
MySQL
股票信息同步任务
数据清理任务
数据初始化任务
每日执行任务
周期执行任务
MySQL
MySQL
Mongo
9:30
12:00
13:30
13:00
15:30
全局一次
每周六一次
每月一次
权限刷新任务
每三天一次
每半月一次
股市交易时间段为:90:30-11:30 13:00-15:00
9:00
MySQL
每日执行任务:实时价格同步任务:每个交易日早上执行,同步所有股票最新的价格,更新到Redis股票卖出任务:每个上午交易时间段执行,卖出完毕后将交易记录和交易订单写入到MySQL历史价格同步任务:每个交易日的中午执行,将所有股票今天最新的开盘收盘价,写入Mongo模型预测任务:每个交易日的中午执行,预测明天的开盘收盘价格。将数据写入MySQL股票买入任务:每个交易日的下午执行,买入成功后将交易记录和订单记录写入MySQL同步订单任务:每个交易日的晚上执行,将今天产生的成交订单,同步到MySQL周期执行任务:股票信息同步任务:每三天同步一次,补充新上市的股票和标记已经退市的股票模型训练任务:每周的非交易日(周六周日)执行,将本周最新产生的数量与历史数据叠加,用于模型的增量迭代训练,训练完成后将模型保存到磁盘权限刷新任务:更新每支股票的交易权限,每半年一次数据清理任务,每个月执行一次,请里系统运行产生的无用数据和过量历史数据数据初始化任务:项目初始化或者历史价格数据丢失的时候执行,只需全局执行一次问题说明技术选型问题为什么使用DL4J而不是Tensorflow或PyTorch来做深度学习模型实现?这是一个面向业务的项目,使用Java的深度学习框架能够更好的与业务集成,对于开发者来说,使用一门熟悉的语言来能更快的实现业务,如果是初学者,没有语言负担的话,建议使用Python+Tensorflow,更加简单易上手为什么使用QuartZ而不是xxlJob或者SpringSchedule?根据项目需求以及最小化设计原则,Schedule不能满足动态修改执行时间和主动触发的需求,而分布式调度显然又太重了,这个项目不需要用到分布式,单节点就足够了,而使用分布式调度的话会引来新的分布式调度同步问题,增加了系统的复杂度,违背项目设计原则为什么不使用mini-cube或者docker?根据最小化设计原则,确实应该使用docker或者jar包来运行,但这是出于学习的目的,因为我工作所接触的项目都是K8S的微服务项目,所以我自己部署一套单节点的K8S集群,以供我学习实验或者跑一些自己的项目为什么不使用Security+JWT来做认证授权?基于最小化设计原则,我的目标用户是个人及访客,基于Web拦截器就可以实现,项目中甚至不包含用户表,目前只有admin, guest, test三个用户,如果是出于学习或者做toB项目,使用Shiro/Security+RBAC,是更常见的做法如何对接其他证券平台或者其他模型预测算法?在Job模块目录下,预留了一个IDataService接口,只要实现该接口,能提供对应平台的数据,model模块下也预留了个IModelService接口,使用其他算法模型实现该接口,利用Java多态和Spring注入功能,即可无缝对接业务策略问题为什么采用T+1短线交易策略而不是T+N?在改项目的2.0版本中,我采用的是T+N的交易模式,即今天买入等到合适的时间点卖出,但是实际的交易结果并不理想,10000元本金,运行不到1个月,亏损约为1200元,持股时间长的,基本亏损较多,可以在交易记录中查到因为股票市场本身是T+1周期的,而LSTM模型由于神经网络本身的特点,在T+N周期上的预测并不理想,只能采用T+1的预测模式。而这跟股市的T+1周期本身是冲突的,所以拆成了两个T+0.5的模式,来完成每日买卖的业务流运转到底应该采用"大"模型还是"小"模型?尝试过针对每只股票训练独有的"小"模型来进行预测,但是模型的测试结果并不理想,因为针对单只股票可供训练的历史数据太少了,通过平台接口获取到的历史数据只有500条,这对人工神经网络的训练来说太少了,不足以让机器学到样本数据特征,于是放弃了独有模型,训练统一模型,用4000支股票,每支500条,每天4个价格,共8,000,000数据量来进行模型训练有没有资金风险或者账号泄露安全问题(待优化)?本项目的出发点是用机器和算法来代替人执行买卖动作,需要用到个人资金账号,需要在Redis导入资金账号和加密后密码,执行登录后的逻辑,所以会有账号泄露的风险,但是不会有资金风险,就算账号泄露,资金提现也只能提现到该账户对应实名银行卡下为什么是采用每天的上午开盘收盘价来实现预测,输入输出维度是2->2?参阅过很多LSTM模型股票预测模型的代码,主流方式大致相同,有以下三种方案:用每天的开盘价,收盘价,最高价,最低价4条样本特征来预测明天的4个价格,输入输出维度为:4->4用每天的开盘价,收盘价,最高价,最低价4条样本特征来预测明天的1个价格,输入输出维度为:4->1用每天的开盘价,收盘价,最高价,最低价1条样本特征来预测明天的1个价格,输入输出维度为:1->1因为我是对明天卖出价格进行预测来指导今天的股票买入,如果采用4->4或者4->1的预测方案,则需等到当天的4个数据全部产生才能进行预测,此时已经过了当天的交易时间段,所有只能等第二天才能买入,股票买入后又要等一天才能卖出,所以实际交易时间段为T+2,失去了LSTM价格预测的准确性尝试过采用1->1方式进行预测,在测试集上表现的结果并不理想,故此采用2->2的输入输出预测模型
这篇关于StockTrading AI小模型股票自动交易系统 转载的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








