本文主要是介绍Tokenize Anything via Prompting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SAM的延续,把SAM输出的token序列用来进行分类,分割和一个自然语言的decoder处理,但其实现在多模态的图像的tokenizer也几乎都是用VIT来实现的。一开始认为这篇文章可能是关于tokenize的,tokenize还是很重要的,后来看完,整体思路大概就是一般来做带类别的sam,目前是grounding dino+sam的思路,先用一个开放词汇检测的目标检测算法通过text将区域框出来再使用sam,本文呢,保留了sam的整体架构,实现了分割分类和描述的三种输出,主要还是通过mask decoder来实现,训练中结合clip。

1.Introduction
旨在构造一个可要求输入的模型,并在大规模数据集上进行预训练。首先介绍了一个可要求输入的标记化任务,该任务要求模型能够在可提取感兴趣区域提示的情况下,提取出通用表示。提取的区域表示可以直接解码成相应任务的输出,用于通用的视觉感知任务。
SA-1B构建了11M张图像上1.1B个高质量的mask,用于训练sam,Laion-2B从网络上收集了2b个图像文本对,训练clip,引入了SemanticSA-1B数据集,在SA-1B的每个分割区域,使用一个具有5B参数的强大clip模型提取出一个词汇,该模型在LAION图像文本对上训练。
利用SemanticSA-1B数据集,训练了一个统一和可推广的模型,能够同时对任何物体进行分割、识别和标题生成,在SAM的架构内合并CLIP的功能,即通过prompt对任何物体进行token的模型。

2.related work
2.1 Vision foundation models
clip,sam
2.2 Open-Vocabulary segmentation
开放词汇语义分割旨在对超出训练中用于训练的封闭词汇范围的区域进行分类,基于clip,并设计特定的对齐技术,以有效的将VLM的知识集成到现有的分割模型中。
2.3 Zero-shot region understanding
将clip和sam结合。
3.Approach
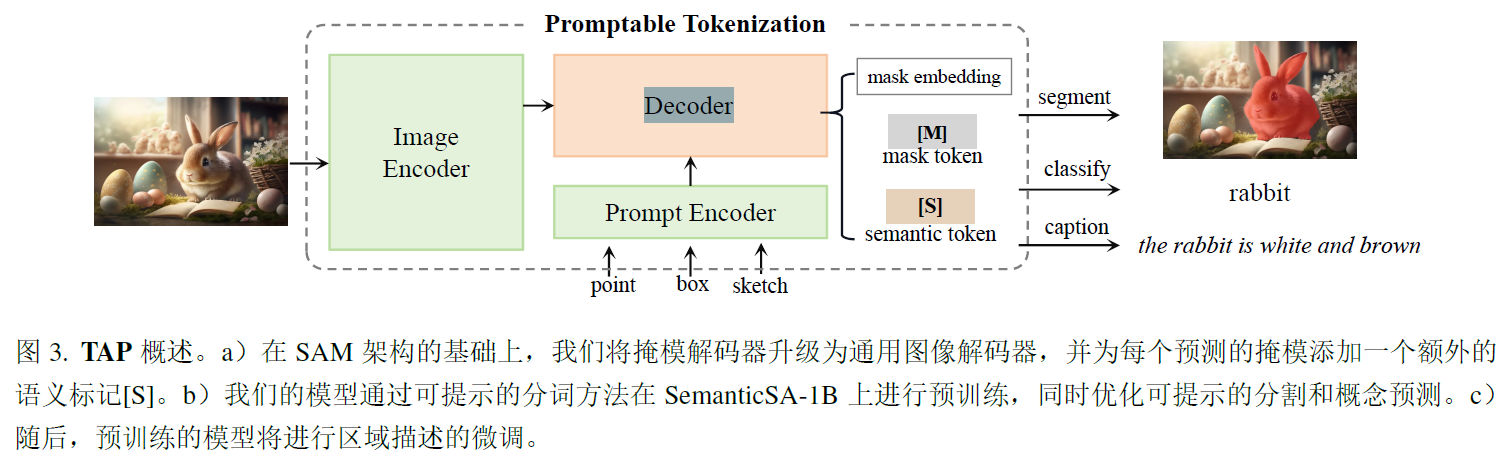
3.1 promptable tokenization
在promptable的分割模型sam中对视觉和语言进行对齐,传统视觉-文本对齐方法依赖于图像-文本对,这限制了对细粒度区域的理解。使用clip和来自SA-1B的分割数据来将掩码与语言对齐,由于SA-1B是一个无类别数据集,利用clip embedding对sam的预测和clip的投影之间的概念词汇分布进行对齐。
3.1.1 预处理
排除了文本提示,使用点提示,5B的EVA-CLIP,从mask裁剪中计算image embedding。
3.1.2 Promptable segmentation
SAM的掩码解码器采用了Mask2Former,根据输入提示对交互分割进行了deformable masked attention,默认为每个提示预测四个掩码,但是路由策略选择一个来解决歧义,因此,图像解码器产生9个ouotput tokens,4个segmentic tokens,4个mask tokens和1个IOU token。为了提高在大规模SA-1B数据集上的训练效率,实现了一个二阶段采样策略,最多包括9个prompt points,在第一阶段,从gt mask中等概率抽样一个box或者point,之后,在256个gpu上执行,预测mask和gt之间的错误区域中均匀采样1-8个点,。。。
3.1.3 Concept prediction
用语义token来预测region,我们利用语义token,通过一个3层mlp(256->1024->1024)获取1024维的视觉embedding,这个视觉embedding进一步投影到2560维的分布logits,通过kl散度损失函数来优化从clip中获取的目标分布和预测分布之间的差异。
3.2 Promptable Captioning
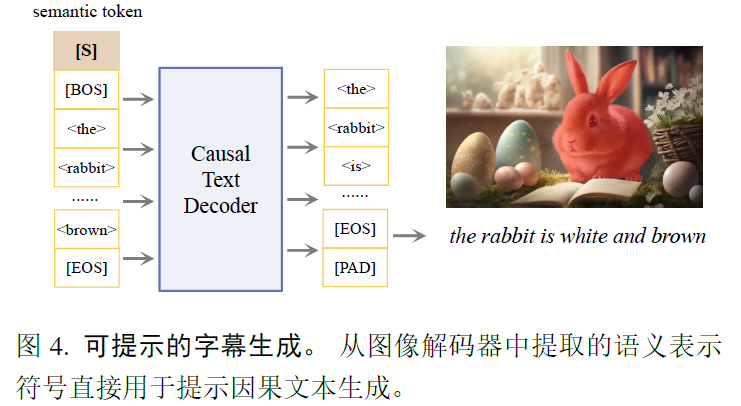
文本编码器,32ktoken,512维的8层transformer,2500w参数的轻量级文本解码器参考了T5-small。
这篇关于Tokenize Anything via Prompting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![[论文笔记]Arbitrary-Oriented Scene Text Detection via Rotation Proposals](https://img-blog.csdn.net/20171124154517721?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMzI1MDQxNg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)