tokenize专题

Jenkins高级篇之Pipeline实践篇-2-groovy中字符串操作split()和tokenize()区别
这篇来一个字符串切割的练习,很多人知道字符串切割是用split()方法,但是很少人知道在groovy中,有一个方法叫tokenize(),这两个方法其实都可以实现字符串切割,但是两者还是有区别的,本篇就来学习和掌握两者的共同点和区别。我也是,之前第一选择就是使用split()函数,直到知道有tokenize()方法, 1.split()得到结果是一个字符串数组,tokenise()得到结果是一个


NLP中常见的tokenize方式及token类型
目录 Tokenizer的细节与计算方式Tokenizer的计算方式各种Tokenizer的优缺点 NLP中常用的Tokens单词Tokens(Word Tokens)子词Tokens(Subword Tokens)字符Tokens(Character Tokens)字节Tokens(Byte Tokens)N-gram Tokens语法Tokens(Syntax Tokens)特殊Toke
Tokenize Anything via Prompting
SAM的延续,把SAM输出的token序列用来进行分类,分割和一个自然语言的decoder处理,但其实现在多模态的图像的tokenizer也几乎都是用VIT来实现的。一开始认为这篇文章可能是关于tokenize的,tokenize还是很重要的,后来看完,整体思路大概就是一般来做带类别的sam,目前是grounding dino+sam的思路,先用一个开放词汇检测的目标检测算法通过text将区域框出

Command “D:\Python\code\venv\Scripts\python.exe -u -c “import setuptools, tokenize;__file__完美解决方法
问题长这样子 输入pip list命令,查看目前pip当前的版本为19.0.3,因为存在python版本与pip版本会有不兼容的问题,我的是py3.8,把pip版本更新到为20版本以上的。 输入命令pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 切换镜像 打开pycharm,在
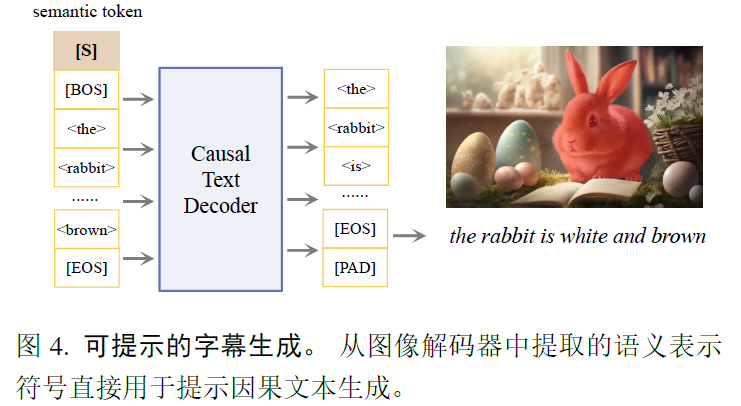
Tokenize Anything via Prompting论文解读
文章目录 前言一、摘要二、引言三、模型结构图解读四、相关研究1、Vision Foundation Models2、Open-Vocabulary Segmentation3、Zero-shot Region Understanding 五、模型方法解读1、Promptable TokenizationPre-processingPromptable segmentationConcept
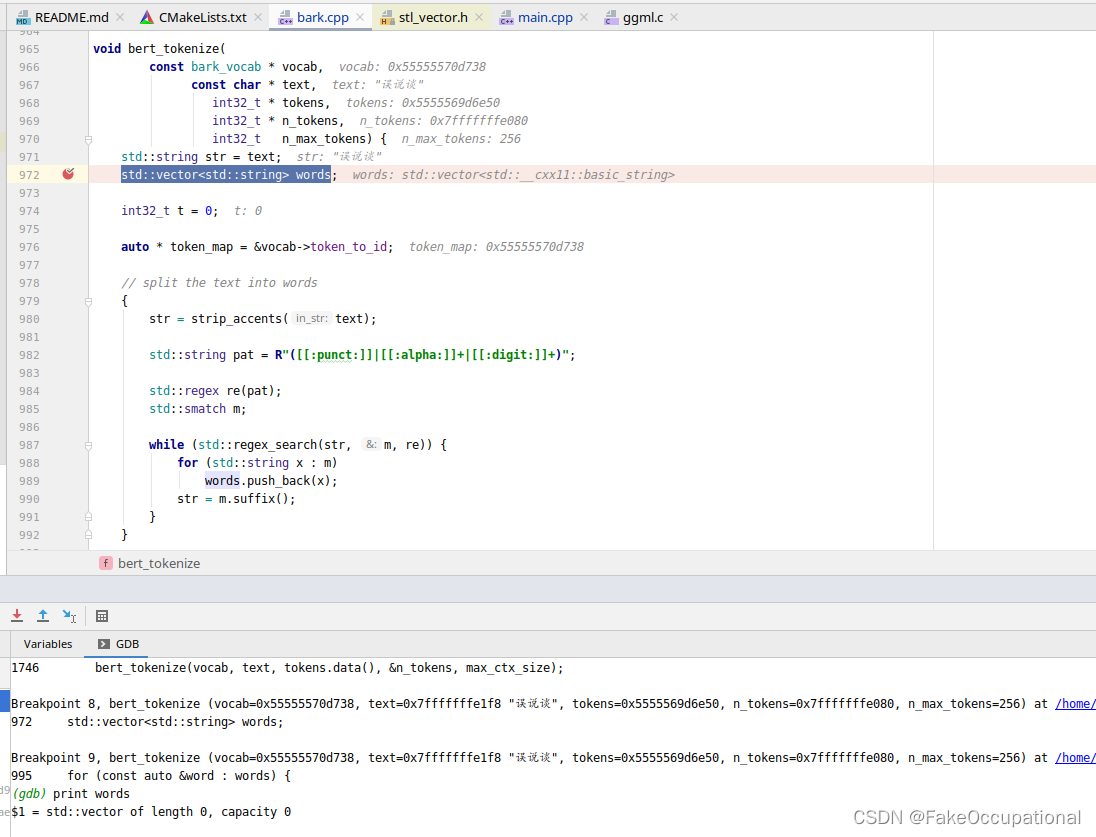
webassembly003 TTS BARK.CPP-02-bark_tokenize_input(ctx, text);
bark_tokenize_input函数 bark是没有语言控制选项的,但是官方的版本无法运行中文bark_tokenize_input会调用bert_tokenize函数,bark_tokenize_input函数对中文分词失效,也就是导致不支持中文的原因。 void bark_tokenize_input(struct bark_context * ctx, const char *