本文主要是介绍Tokenize Anything via Prompting论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、摘要
- 二、引言
- 三、模型结构图解读
- 四、相关研究
- 1、Vision Foundation Models
- 2、Open-Vocabulary Segmentation
- 3、Zero-shot Region Understanding
- 五、模型方法解读
- 1、Promptable Tokenization
- Pre-processing
- Promptable segmentation
- Concept prediction
- Zero-shot transfer
- 2、Promptable Captioning
- Task
- Visual encoder
- Text decoder
- Causal modeling
- Caption inference
前言
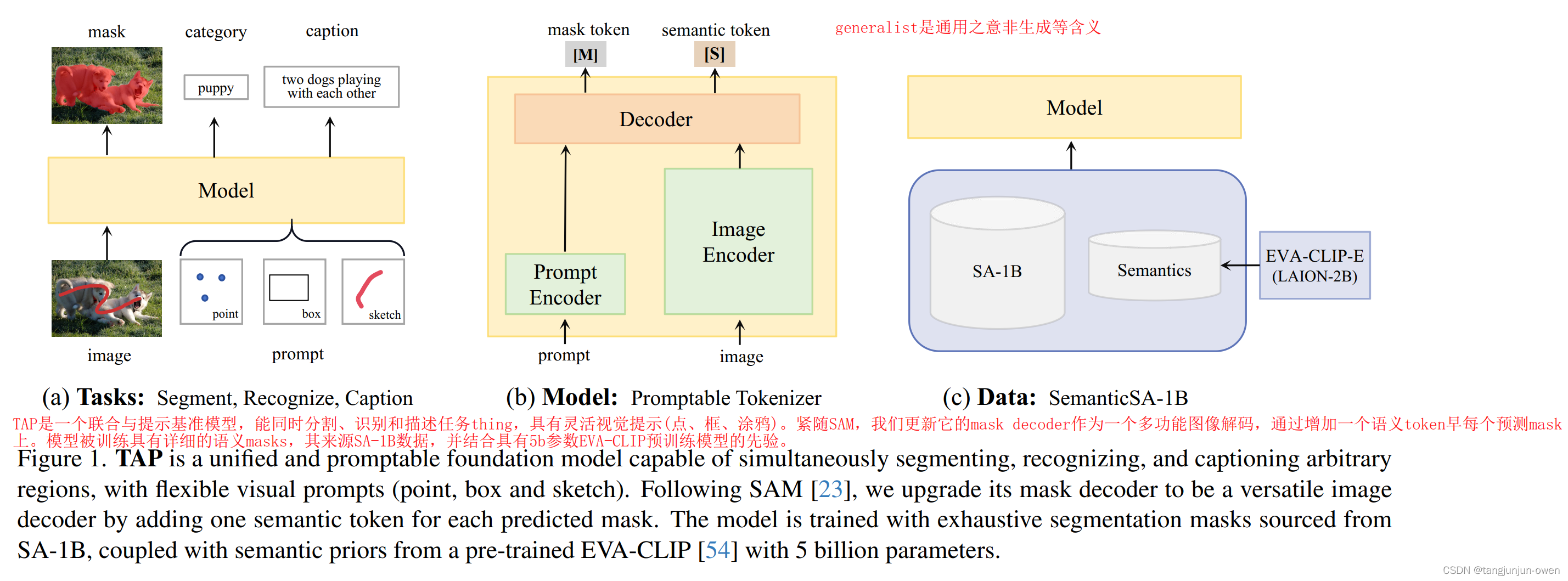
随着分割一切的SAM模型基准,紧接着tag一切的RAM模型基准,又紧接着Tokenize Anything via Prompting,提出了一个unified and prompt模型能够同时分割、识别和描述anything。不同与SAM模型,我们目的是视觉prompt构建一个多功能区域表征。为了实现这个,我们使用大量语义分割mask数据(如SA-1B)以及来自有5b参数预训练CLIP模型先验分割信息,训练一个泛化模型。特别地,我们构建了一个promptable 图像解码块,增加了语义token到每个mask token。该模型能实现目标级别的描述与分割。基于此,本文将解读该论文,我基本是精度了一遍,感觉很有意思,我将其记录,并分享。
一、摘要
我们提出了一个unified and prompt模型能够同时分割、识别和描述anything。不同与SAM模型,我们目的是野外环境通过视觉prompt构建一个多功能区域表征。为了实现这个,我们使用大量语义分割mask数据(如SA-1B)以及来自有5b参数预训练CLIP模型先验分割信息,训练一个泛化模型。特别地,我们构建了一个promptable 图像解码块,增加了语义token到每个mask token。语义token负责在预定义概念空间学习语义先验。通过联合优化mask tokens的语义与semantic tokens概念预测,我们的模型展现了更强区域识别与定位能力。列如,一个额外38m参数因果文本解码训练以CIDEr 150.7分在Visual Cenome区域描述任务创造了新记录。我们相信这个模型可以成为一个通用的区域级图像标记器,能够为广泛的感知任务编码通用的区域上下文。

注:一个unified和generalizable模型,能同时语义、识别与描述anything。
二、引言
视觉感知一个关键目标是有效定位与识别任意感兴趣区域。单个视觉模型是有能力理解区域内容,同时执行感知任务,如语义分割、识别与描述任务。然而,存在模型经常聚焦在定位不区分类别masks,如SAM,要不仅提取视觉语义如CLIP以及类似它的区域级变体。特别地,SAM发展了语义基准模型,能通过prompt分割anything语义信息,能够实现更强像素定位生成。在另一方面,CLIP在web-scale图像文本对数据集通过对比学习训练识别基准模型,证明了区域级别的泛化能力。相应的,具有SAM架构的CLIP模型学习语义先验在复杂视觉感知中提供了一个有前途路径。
在我们研究中,我们目的是构建一个prompt模型和在一个大数据集中预训练,能在定位与识别中有很强泛化能力。我们首先引入一个提示token任务,它足够通用,可以作为一个强大的预训练目标,同时促进广泛的下游应用。这个任务需要一个有概括通用表达能力模型,如给mask tokens与semantic tokens是给出灵活prompt关于感兴趣区域提示。然后,提取区域表达能直接解码相应任务输出,实现视觉感知任务目的。
训练这样一个高性能和概括性基准模型需要多样化大量数据。然而,当前没有网页规模数据资源同时具有语义与识别价值数据。SA-1B构建了1.1B高质量mask注释数据,使用11M数据对于语义基准训练模型,如SAM。另一方面,LAION-2B在网上收集了2B图像文本对数据,能够训练通用识别模型如CLIP。为了解决数据缺乏问题,我们引入SemanticSA-1B数据集。这个数据集实现整合web-scale语义从LAION-2B数据集为SA-1B。特别地,在SA-1B每个语义区域,我们使用有5B参数CLIP强大模型提取预测概念词汇分布,CLIP模型在大量LAION图像文本对数据训练而来。
使用SemanticSA-1B数据集,我们训练一个unified和generalizable模型,能同时语义、识别与描述anything。这就实现合并CLIP能力到SAM架构中,利用web-scale语义与分割masks。我们把这个模型叫做TAP,名称为Tokenize Anything via Prompting,如同图1b。特别地,给一个图像和视觉prompt,TAP tokenizes感兴趣区域转为一个mask token和一个segment token。mask token查询逐限速语义类似SAM,而语义token将负责区域级的语义预测。我们的TAP模型是端到端联合mask与语义token从头训练。通过利用语义token,我们能解决open-vocabulary分类任务,只用一个MLP头,和有提示描述任务,用一个轻量文本解码具有自动回归过程。
我们广泛评估TAP模型和他部件。TAP证明了更强泛化新能在实列分类任务,在LVIS为59AP,也维持可观竞争力,42.6 VS43.1 AP 对于TAP与SAM。明显我们获得新的记录对于CIDEr 150.7分数在区域藐视任务中。我们发现tokenized区域特征是通用的在语义与分类任务,甚至能直接促进因果语言模型。以上,我们相信TAP模型是一个多功能区域级图像tokenizer,能编码区域内容对于广泛视觉语言任务。
三、模型结构图解读
TAP是一个联合与提示基准模型,能同时分割、识别和描述anything,具有灵活视觉提示(点、框、涂鸦)。紧随SAM,我们更新它的mask decoder作为一个多功能图像解码,通过增加一个语义token在每个预测mask上。模型被训练具有详细的语义masks,其来源SA-1B数据,并结合具有5b参数EVA-CLIP预训练模型的先验。
四、相关研究
1、Vision Foundation Models
视觉基准模型目的是实现更强泛化通用能力在广泛的视觉任务中。CLIP开始同时训练图像文本对校准2个模态,更多学者努力于训练一个通用视觉语言表征。除此之外,一些研究者构建视觉通用模型,列如SAM引入大规模数据,并训练一个提示分割模型。让用户使用提示交互,SAM在通用语义任务上证明了很强泛化性能。与SAM同时的SegGPT统一各种语义任务到一个in-context语义问题。训练后,SegGPT使用in-context推理缺乏执行任意分割任务能力。另外一些研究者寻找构建通用模型,通过利用多模态数据集。在这个工作中,我们目的是构建一个视觉基准模型,作为一个多功能区域图像tokenzier,能编码通用区域内容在视觉感知任务中。
2、Open-Vocabulary Segmentation
不像先前实列分割与语义分割模型,使用一个有限vocabulary,open-vocabulary语义目的去分类区域,超越closed-vocabulary训练。大量研究努力聚焦利用预训练视觉模型像CLIP,关系设计特别校准技术有效整合VLM知识到存在语义模型。列如Lseg使用文本和像素embedding到一个共同特征空间,校准label到每个pixel中。MaskCLIP构建一个2阶段模型取无缝地整合到CLIP视觉编码器。ZegFormer使用VLM把问题解耦看成无分类组任务和一个区域级分类任务。通过利用描述数据,一些研究校准视觉与文本特征在一个弱监督方法上[13,19,32,65,68]。对于instance,Group ViT直接在没有像素级注释使用图像描述对训练,基于文本监督直接分组masks。OVSeg fine tune CLIP在masked 图像带有来自图像描述模型生成的伪标签。在另一方面,CGG合并grounding和generation loss探索图像描述知识。除此之外,别的研究用单个模型联合学习任务或者研究图像文本融合模型。我们研究校准基于CLIP方法而不同与2阶段模型是典型依赖图像级CLIP分类任务。相反,我们方法聚焦develop一个但模型具有区域级语义感知。
3、Zero-shot Region Understanding
先前研究聚焦VLM模型延伸open-vocabulary能力去做目标检测任务。近期研究目的是在open-vocabulary分类熟练合并CLIP,实现分类与具有sam分割能力。对于实列,SAM-CLIP从SAM与CLIP模型中蒸馏知识,使用一部分数据重新训练视觉编码,重新训练原始模型SAM与CLIP优势。RegionSpot统一prompt,在检测数据集上增加一个训练adapter适应器,是SAM的mask tokens能和CLIP的特征交互,而CLIP特征来源maskde图像语义。一些研究试图构建统一模型能力识别目标在任意区域。省略一些模型。不像依赖手工注释模型,我们模型利用已有分割masksSA-1B和莱斯高性能CLIP模型语义对,目的是构建一个提示图像tokenizer来理解任意区域语义文本。
五、模型方法解读
1、Promptable Tokenization
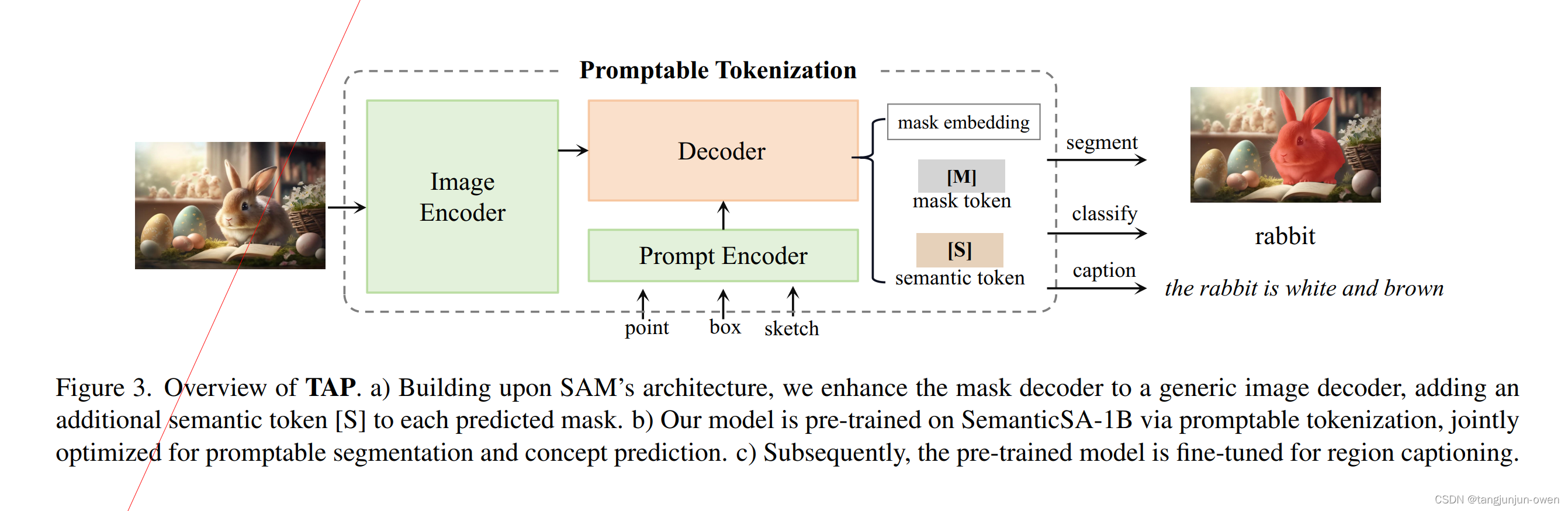
我们首要聚焦是使用一个有prompt语义模型SAM结构校准视觉语言,增强模型区域级的语义感知能力。传统视觉语言校准方法依赖图像文本对,限制了细粒度区域理解。对比先前方法依赖收集好的或近似区域文本数据,我们方式校准mask到语言语义,使用CLIP和存在语义数据,我们利用现成的CLIP嵌入在人为的概念空间,并校准概念词汇分布在SAM约与CLIP的projection中。最终,我们预训练多功能编解码器在2个子任务。第一是提示语义和第二概念预测。整体方法介绍如图3.
Pre-processing
不同与先前方法,我们排除文本提示,其原因在于他们不明确和点提示对比,特别是小物体mask。先前研究利用现有CLIP校准经常使用预训练区域提取网络的box proposals提取图像embed。相反,SA-1B数据对图像的每个目标提供高质量mask。这样,我们自然使用gt masks计算图像embed,避免特别数据注释偏差或者bx预测误差。特别地,我们利用搞新能开源CLIP模型(具有5B参数)从masked凸显crops计算图像embe,并本地保存为最终数据。
Promptable segmentation
mask的解码在SAM采用一个Mask2Former架构,合并变形mask注意力响应交互语义prompt输入。因此,我们认为提示分割是语义能力的必要前奏。紧跟SAM,我们模型默认对每个prompt预测4个masks,任然一个路线策略选择解决模棱两可问题。因此,我们图像解码生成9个输出token。4个语义token,4个mask token和1个iou token。为了改善模型在大规模SA-1B数据训练效率,我们实现一个2阶段采样策略,使用最大9个prompt点,因为它是在原始SAM 11个交互阶段执行。第一阶段,我们在gt mask中同等概率采样一个框或一个点。在随后的阶段,在256个gpu上执行,我们从预测和真值mask之间的误差区域均匀取样1到8个点。为了能够sketch或mask作为提示prompt,sam未研究,我们引入一个概率为50%的非交互采样方法。这个采样统一从gt mask取1到9个点,提供一个更广prompt空间。在推理时候,9个点从mask或sketch展平2d坐标的线性空间被选择。至于mask监督,一个线性组合focal loss与dice loss,使用20:1比列,follow SAM方法。
Concept prediction
为了增强我们模型语义感知,我们提出预测区域概念,使用semantic token。具体地,我们利用语义token去获得一个1024维度视觉embed,通过一个3层MLP(256到1024到1024)。这个视觉embed是进一步映射到2560维度分布logits。随后,我们优化KL loss在预测分布与CLIP模型获得target分布。该方法有效地缓解了成对概念引起的性能退化。对于实列,牛头犬的概念是狗类别的一个子集,因此它不应该在表示空间中偏离狗或猫等相关概念太远。更重要的是,图像-文本分布为监督提供了最大的信息,防止基础模型学习硬标签的偏差
Zero-shot transfer
在预训练之后,我们模型能对语义提示实现open-vocabulary分类。被给视觉prompt,我们图像解码生成4个masks和9个tokens。最后一个mask和关联语义token使用启发路线策略选择。特别,我们对边界box选择第一个mask,并对loose points选择排名第一,类似于专家混合(MoE)技术的简化实现。最终语义token被用来泛化实列分类在特别概念词汇中。
2、Promptable Captioning
我们受到近期先进大语言模型启发,next token预测被遇到替代人为预测任务。在这部分,我们引入一个文本生成范式目的激发语义token潜力。
Task
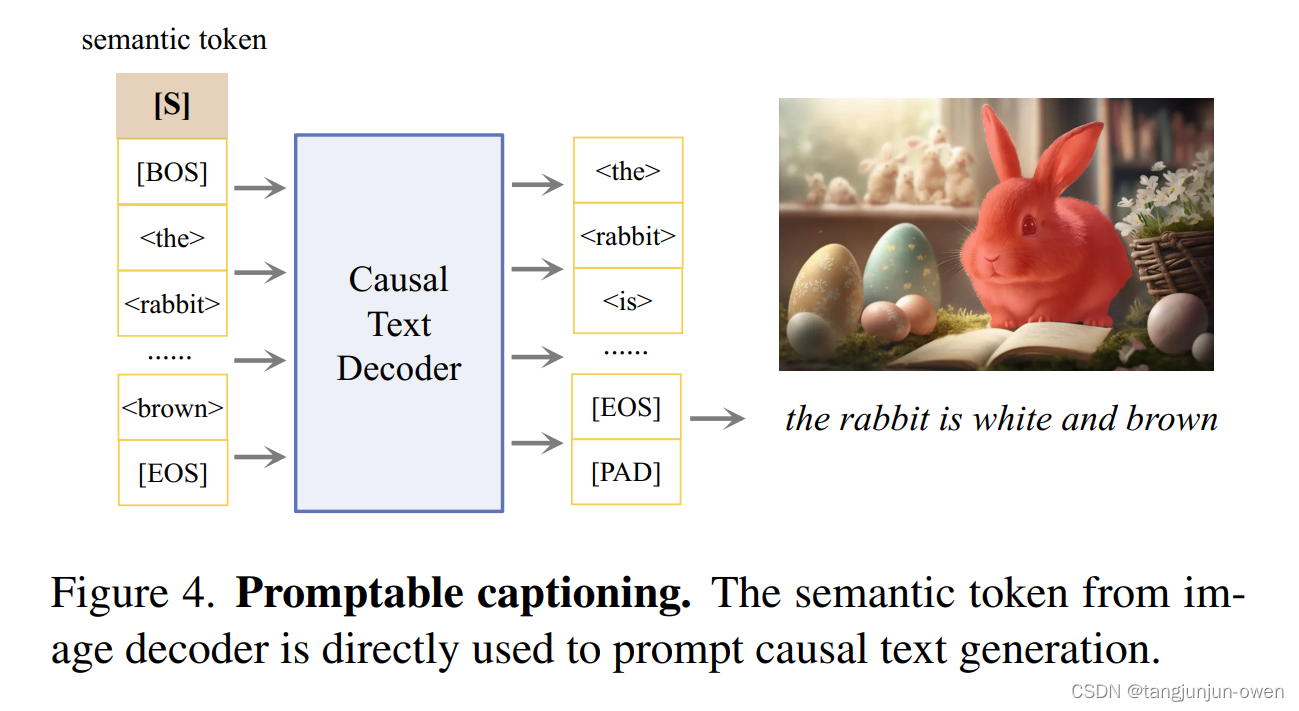
很多先前研究通过在大规模vocabulary数据集生成伪标签来finetune预训练模型。这种方式落后NLP对话场景。在我们努力下构建视觉基准模型,我们通过因果语言模型构建通用视觉语言模型。特别地,我们使用带有semantic token的因果transformer提示,从图像解码生成区域描述。不同与先前方法,冻结三个模型,我们模型是能实现端到端任务。文本通用架构如图4描述。
Visual encoder
使用提示tokenizer(如图3)生成语义tokens,我们仅用线性projection在语义token中去校准与文本embed的维度。这个视觉编码,包含一个提示tokenizer和一个线性projector,与先前方法相比,显示了显著效率,涉及到感兴趣特征区域参数。因此,感知编码了复杂视觉理解区域语义。
Text decoder
我们使用一个32k tokens词汇的字节编码预测tokenized区域描述。对于文本解码,我们使用8层标准transformer结构,embed维度是512维度去聚集简要描述(最大内容长度为40)。这个有25M参数轻量化文本解码,与T5-small模型相关,如果给出提示tokens,将足以执行mask到text转化。
Causal modeling
我们把语义token放在序列重要位置,仅跟一个BOS token和使用交叉熵loss监督下一个token预测。我们使用rorary embed为多模态序列整合位置编码
Caption inference
对于描述生成,我们迭代生成40 tokens,对每个mask使用最大概率。为加速attention计算,我们使用标准实践的自动回归,缓存key与value对值。最终生成对每个prompt多个输出中选择,利用预3.1部分相同策略。
这篇关于Tokenize Anything via Prompting论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





