本文主要是介绍【提示学习论文】ProGrad:Prompt-aligned Gradient for Prompt Tuning论文原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Prompt-aligned Gradient for Prompt Tuning(CORR2022 / ICCV2023)
1 Motivation

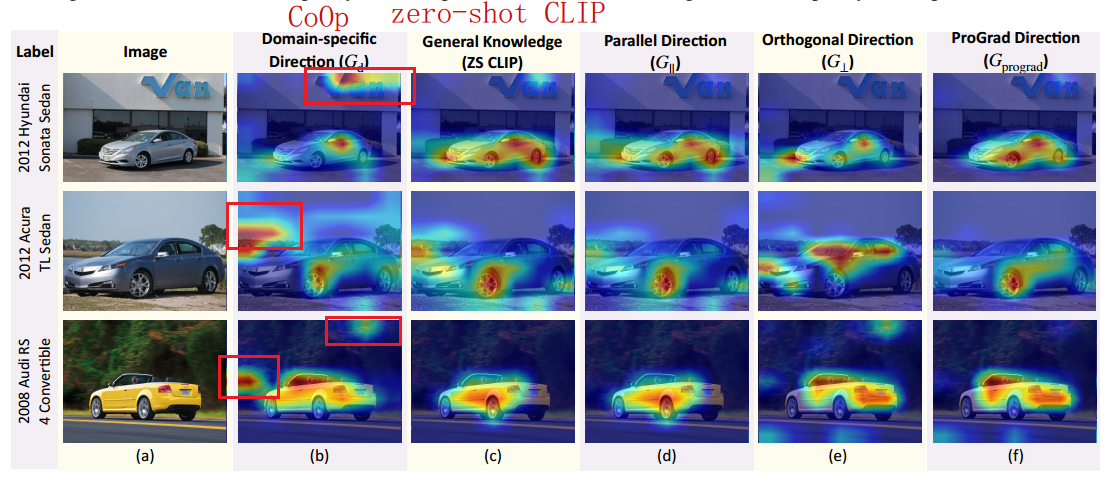
- 经过CoOp微调过的prompt会导致模型更关注背景而不是前景对象,对于分类任务不利
2 Contribution

提出了一种基于prompt对齐的梯度的引导方法(ProGrad),来应对prompt学习中添加的不正确偏置的问题。在tuning的过程中进行一种正则化,来确保这一步的tuning不和原本的知识(zero-shot CLIP)产生冲突。
- 一般方向(general direction):zero-shot CLIP
- 域特殊方向(domain-specific direction):CoOp计算得出
- 垂直向量 G ⊥ G_⊥ G⊥
- 平行向量 G ∥ G_∥ G∥
3 具体方法
由CoOp进行学习的域特殊方向,加强其在当前数据下的精度的优化方向,但是这可能导致过拟合。用一个一般普通的prompt和zero-shot CLIP的logits计算一个KL散度,这个KL散度回传的梯度作为一般方向。
3.1 交叉熵损失

L c e L_{ce} Lce:模型预测 p ( t i ∣ x ) p(t_i|x) p(ti∣x)与真实值 y y y的交叉熵损失
3.2 KL散度

L k l L_{kl} Lkl:模型预测 p ( t i ∣ x ) p(t_i|x) p(ti∣x)与zero-shot CLIP预测 p z s ( w i ∣ x ) p_{zs}(w_i|x) pzs(wi∣x)的KL散度
3.3 梯度
- 将 L c e L_{ce} Lce的梯度表示为 G d = ∇ v L c e ( v ) G_d =∇_vL_{ce}(v) Gd=∇vLce(v)
- 将 L k l L_{kl} Lkl的梯度表示为 G g = ∇ v L k l ( v ) G_g =∇_vL_{kl}(v) Gg=∇vLkl(v)

G d G_d Gd和 G g G_g Gg的关系:
- 夹角小于90°:说明下游知识优化方向与一般知识不冲突,此时安全地更新梯度 G p r o g r a d G_{prograd} Gprograd作为 G d G_d Gd
- 夹角大于90°:说明下游知识优化方向与一般知识冲突,此时,将 G d G_d Gd投影 G g G_g Gg的正交方向,避免增加 L k l L_{kl} Lkl
3.4 ProGrad策略公式

在本文CoOp中,我们没有使用 G d G_d Gd来更新上下文向量,而是使用 G p r o g r a d G_{prograd} Gprograd来优化,可以避免过拟合:
- λ=1:将 G d G_d Gd投影到 G g G_g Gg的正交方向
- λ=0:使prograd退化为CoOp
3.5 总体流程
- 可学习上下文和类别输入文本编码器,图像输入图像编码器
- 将文本特征与图像特征计算相似概率,得到 p p p
- p p p与 y y y计算 C E L o s s CE Loss CELoss,得到 G d G_d Gd
- p p p与 p z s p_{zs} pzs计算 K L L o s s KL Loss KLLoss,得到 G g G_g Gg
- 将 G d G_d Gd和 G g G_g Gg反传回去,使用 G p r o g r a d G_{prograd} Gprograd更新可学习参数
这篇关于【提示学习论文】ProGrad:Prompt-aligned Gradient for Prompt Tuning论文原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





