aligned专题

【译】PCL官网教程翻译(22):全局对齐空间分布(GASD)描述符 - Globally Aligned Spatial Distribution (GASD) descriptors
英文原文查看 全局对齐空间分布(GASD)描述符 本文描述了全局对齐的空间分布(GASD)全局描述符,用于有效的目标识别和姿态估计。 GASD基于表示对象实例的整个点云的参考系的估计,该实例用于将其与正则坐标系对齐。然后,根据对齐后的点云的三维点在空间上的分布情况计算其描述符。这种描述符还可以扩展到整个对齐点云的颜色分布。将匹配点云的全局对齐变换用于目标姿态的计算。更多信息请参见GASD。

__attribute__((aligned))
__attribute__ 语法的来源 GNU C 的一大特色就是__attribute__ 机制。attribute 可以设置函数属性(Function Attribute)、变量属性(Variable Attribute)和类型属性(Type Attribute)。 attribute 语法格式为: attribute ((attribute-list)) 当__attribute__

论文翻译:Are aligned neural networks adversarially aligned?
Are aligned neural networks adversarially aligned? https://proceedings.neurips.cc/paper_files/paper/2023/hash/c1f0b856a35986348ab3414177266f75-Abstract-Conference.html 对齐的神经网络是否对抗性对齐? 文章目录 对齐的神经网

gcc packeted and aligned的作用
在shared memory的驱动中看到一个诡异的现象,从AP侧看BP的写指针有时会变小,例如: read/write = 0x44f0, 但write忽然会变为0x4400,正常情况下是write增加,read在后面跟随。这样就会出现异常。 后来发现,读写操作不是按照预想的一次完成,而是按字节多次进行的。 假设AP 读却写指针(BP维护),当AP读第一个字节后,BP发生了变化,又更改了第一

_aligned_malloc函数以及对应linux版本函数
此函数是C标准新增的windows下动态申请对齐内存函数,原型: #include<malloc.h>void * _aligned_malloc( size_t size, size_t alignment ); 参数size是申请的内存大小;参数alignment为内存对齐大小,必须是2的幂; _aligned_malloc申请的内存可由free进行释放。 在linu
【转】C语言字节对齐 __align(),__attribute((aligned (n))),#pragma pack(n)
packed)) struct PACKED test { char x1; short x2; float x3; char x4; }GNUC_PACKED; 这时候sizeof(struct test)的值仍为8。 二、深入理解 什么是字节对齐,为什么要对齐? TragicJun 发表于 2006-9-18 9:41:00 现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任
#####好好好#####论文分享 | Learning Aligned-Spatial GCNs for Graph Classification
目前大部分GCN方法可以被归为两类:Spectral(基于频域)卷积和 Spatial(基于空域)卷积。前者主要基于 Spectral Graph Theory 将图信号变换到谱域与滤波器系数进行相乘再做逆变换[1][2],这种方法处理的图结构常常是固定大小的(节点个数固定)并且主要解决的是节点分类问题。然而现实中图数据的大小往往不固定,例如生物信息数据中的蛋白质结构、社交网络中的用户关系等,基于

【提示学习论文】ProGrad:Prompt-aligned Gradient for Prompt Tuning论文原理
Prompt-aligned Gradient for Prompt Tuning(CORR2022 / ICCV2023) 1 Motivation 经过CoOp微调过的prompt会导致模型更关注背景而不是前景对象,对于分类任务不利 2 Contribution 提出了一种基于prompt对齐的梯度的引导方法(ProGrad),来应对prompt学习中添加的不正确偏置的问题。

论文翻译 - Defending Against Alignment-Breaking Attacks via Robustly Aligned LLM
论文链接:https://arxiv.org/pdf/2309.14348.pdf Defending Against Alignment-Breaking Attacks via Robustly Aligned LLM Abstract1 Introduction2 Related Works3 Our Proposed Method3.1 Threat Model3.2 Our Pr
Allocate aligned memory
InterlockedCompareExchange128 要求目标操作数地址必须16字节对齐,否则会出访问异常。所以在分配目标操作数的时候需用特殊的分配函数: Windows 下用这个: http://msdn.microsoft.com/en-us/library/8z34s9c6(vs.71).aspx Linux 用这个: http://linux.die.net/man/3/posi
Java 3DES加密 javax.crypto.IllegalBlockSizeException: data not block size aligned
3DES算法 3DES算法是指使用双长度(16字节)密钥K=(KL||KR)将8字节明文数据块进行3次DES加密/解密。如下所示: Y = DES( KL[DES-1( KR[DES( KL[X] )] )] ) 解密方式为: X = DES-1( KL[DES( KR[DES-1( KL[Y] )] )] ) 其中,DES( KL[X] )表示用密钥K对数据X进行DES加密,DES-1
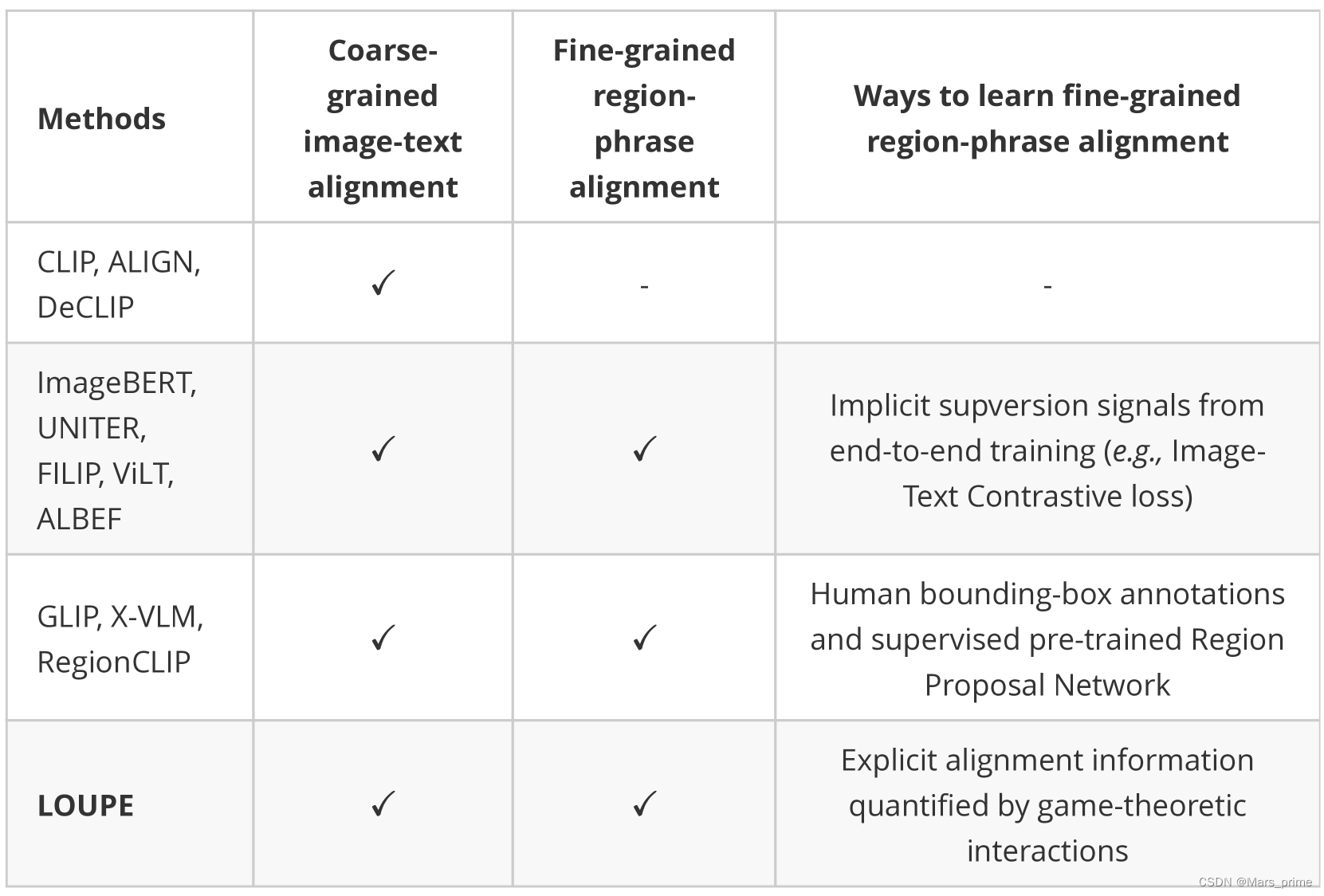
Fine-Grained Semantically Aligned Vision-Language Pre-Training细粒度语义对齐的视觉语言预训练
abstract 大规模的视觉语言预训练在广泛的下游任务中显示出令人印象深刻的进展。现有方法主要通过图像和文本的全局表示的相似性或对图像和文本特征的高级跨模态关注来模拟跨模态对齐。然而,他们未能明确学习视觉区域和文本短语之间的细粒度语义对齐,因为只有全局图像-文本对齐信息可用。在本文中,我们介绍放大镜,一个细粒度语义的Ligned visiOn-langUage PrE 训练框架,从博弈论交互的

<论文阅读> CorAl – 点云是否正确对齐? CorAl – Are the point clouds Correctly Aligned?
【摘要】:在机器人感知中,许多任务依赖于点云配准。然而,目前还没有一种方法可以在没有特定环境参数的情况下可靠地自动检测错位点云。我们提出"CorAl",一种用于点云对的对齐质量度量和对齐分类器,它有助于评估配准性能的能力。 CorAl 比较了两个点云的联合熵和分离熵。分离熵提供了可以认为是环境固有的熵的度量。因此,如果点云正确对齐,则联合熵应明显更低。计算期望熵使得该方法对小的对齐误差也很敏感,这
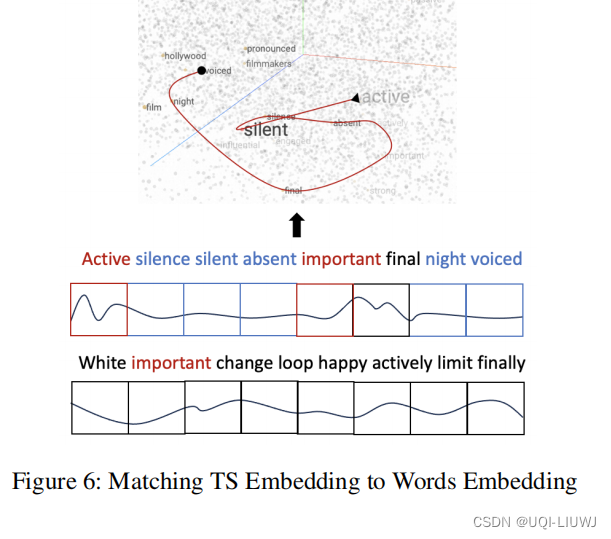
论文笔记:TEST: Text Prototype Aligned Embedding to ActivateLLM’s Ability for Time Series
1 intro 1.1 背景 时间序列 TS 和大模型 LLM 的结合 设想了两种实现TS+LLM的范例 LLM-for-TS 针对TS数据,从头开始设计并预训练一个基本的大型模型,然后为各种下游任务相应地微调模型TS-for-LLM 基于现有的LLM,使它们能够处理TS数据和任务。不是创建一个新的LLM,而是设计一些机制来为LLM定制TS。论文承认第一种方法是最基本的解决方案,因为预训练是向

Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
目录 Oscar Pre-trainingAdapting to V+L TasksExperimental Results & AnalysisPerformance Comparison with SoTAQualitative Studies References OSCAR: Object-SemantiCs Aligned pRe-training Oscar

Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks 解析+总结
paper: 2004.06165.pdf (arxiv.org) code: microsoft/Oscar: Oscar and VinVL (github.com) 多模态学习初入门 最近,视觉和语言预训练(Vision-Language Pretraining, 简称VLP)在解决多模态学习方面已显示出巨大的进步。这类方法最有代表性地通常包括如下两步: 预训练:是以自监督的方式在
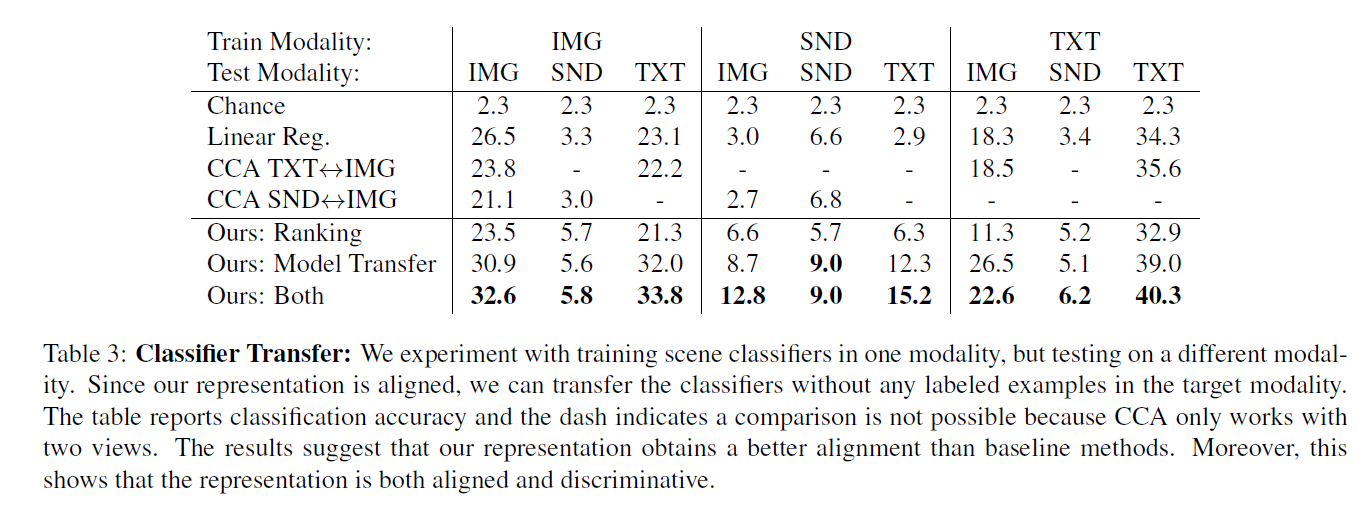
论文-See, Hear and Read: Deep Aligned Representations
See, Hear and Read: Deep Aligned Representations 本paper提出了可以在三种自然模态(视觉,声音,语言)下进行学习的深度判断特征表达,使用Deep Conv Network来进行对齐式的表达学习。 本paper使用的dataset: Cross-Modal Network 目标是对image X 和sound Y学习其对齐之后

(有源码)part-aligned系列论文:1711.AlignedReID- Surpassing Human-Level Performance in Person Re-Id 论文阅读
原 part-aligned系列论文:1711.AlignedReID- Surpassing Human-Level Performance in Person Re-Id 论文阅读 https://blog.csdn.net/xuluohongshang/article/details/79036440 xuluohongshang 阅读数:2032 <