本文主要是介绍论文笔记:TEST: Text Prototype Aligned Embedding to ActivateLLM’s Ability for Time Series,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 intro
1.1 背景
- 时间序列 TS 和大模型 LLM 的结合
- 设想了两种实现TS+LLM的范例
- LLM-for-TS
- 针对TS数据,从头开始设计并预训练一个基本的大型模型,然后为各种下游任务相应地微调模型
- TS-for-LLM
- 基于现有的LLM,使它们能够处理TS数据和任务。
- 不是创建一个新的LLM,而是设计一些机制来为LLM定制TS。
- LLM-for-TS
- 论文承认第一种方法是最基本的解决方案,因为预训练是向模型灌输知识的关键步骤。而第二种方法实际上很难超越模型的原始能力
- 然而,由于以下三个考虑,论文仍然关注第二种方法:
- 数据
- LLM-for-TS需要大量的累积数据。由于TS更加专业且涉及隐私,与文本或图像数据相比,尤其在非工业领域,它更难以大量获取
- TS-for-LLM可以使用相对较小的数据集,因为其目标仅仅是协助现有的LLM推断TS
- 模型
- LLM-for-TS侧重于垂直行业。由于TS在各个领域的主要差异,针对医疗TS、工业TS等的各种大型模型必须从头开始构建和训练
- TS-for-LLM需要很少甚至不需要训练。通过使用插件模块,它使得使用更加通用和便捷
- 用途
- LLM-for-TS适合涉及专家的情况
- TS-for-LLM保持了LLM的文本能力,同时提供丰富的补充语义,易于访问和用户友好
- 数据
- 然而,由于以下三个考虑,论文仍然关注第二种方法:
- 设想了两种实现TS+LLM的范例
- 基于预训练的LLM,最自然的方法是将TS视为文本数据
- 可能的对话是:[Q] 通过以下平均动脉压力序列(单位:毫米汞柱)判断患者是否患有败血症:88、95、78、65、52、30。[A] 是的
- 然而,TS通常是多变量的,而文本是单变量的
- 处理单变量文本的LLM会将多变量TS转化为多个单变量序列并逐一输入它们
- 这将导致三个缺点
- 不同的提示、顺序和连接语句会产生不同的结果
- 长输入序列可能使LLM效率低下,难以记住前一个单变量TS
- TS中的多变量依赖性的关键方面将被忽略
- 这将导致三个缺点
- ——>论文对TS进行了token化,设计了一个嵌入TS token的模型,并替换了LLM的嵌入层
- 核心就是创建能够被LLM理解的嵌入
1.2 论文思路
- 提出了一个嵌入方法(TEST),用于将时间序列标记与LLM的文本嵌入空间对齐
- 在对比学习的基础上,TEST使用正交的文本嵌入向量作为原型来约束TS的嵌入空间,并通过识别特征原型来突出模式,从而激活LLM的模式机器的能力
- 尽管TS-for-LLM不能显著地超越当前为TS任务定制的SOTA模型,但它是一个具有前瞻性的测试,论文希望它能为未来的研究奠定基础
2 related work
2.1 TS+LLM
- 目前有三种做法
- PromptCast和 Health Learner将TS视为文本序列。他们直接将单变量数值TS输入到LLM中,并设计提示来实现TS任务。
- 很明显,他们受到了在引言部分总结的三个困境的限制
- METS将临床报告文本和ECG信号对齐。它满足了ECG-text的多模态条件,但不能推广到大多数没有段注释的TS数据
- PromptCast和 Health Learner将TS视为文本序列。他们直接将单变量数值TS输入到LLM中,并设计提示来实现TS任务。
2.2 TS嵌入(对比学习)
- 多数方法都集中在实例级对比上
- 将实例(全长TS、TS段等)独立对待
- 将anchor的增强视图视为正样本,其余视图视为负样本
- 考虑到固有的时间依赖性,研究人员已经探索了在精细的时间级别区分上下文信息的可行性
- 实例的选择包括跨时间序列和时间序列内部
- 直接对比不能将TS嵌入和LLM的可理解空间联系起来
- 论文冻结预训练的LLM,训练TS的嵌入
- 使用LLM中的文本标记嵌入来限制和引导TS标记嵌入
- LLM的本质实际上是通用的模式机器(Mirchandani等人 2023)
- 因此,无论token列表的组合是否有可以被人类理解的语义,都强行对齐TS token的模式和文本token的模式
- ——>一个TS token列表可以被一个没有语义信息的句子近似地表示
3 方法
3.0 总览
- 方法有两个关键步骤
- 将TS token化,并使用对比学习训练一个编码器来嵌入TS token
- 创建提示使LLM更加接受嵌入并实现TS任务
- 将TS token化,并使用对比学习训练一个编码器来嵌入TS token
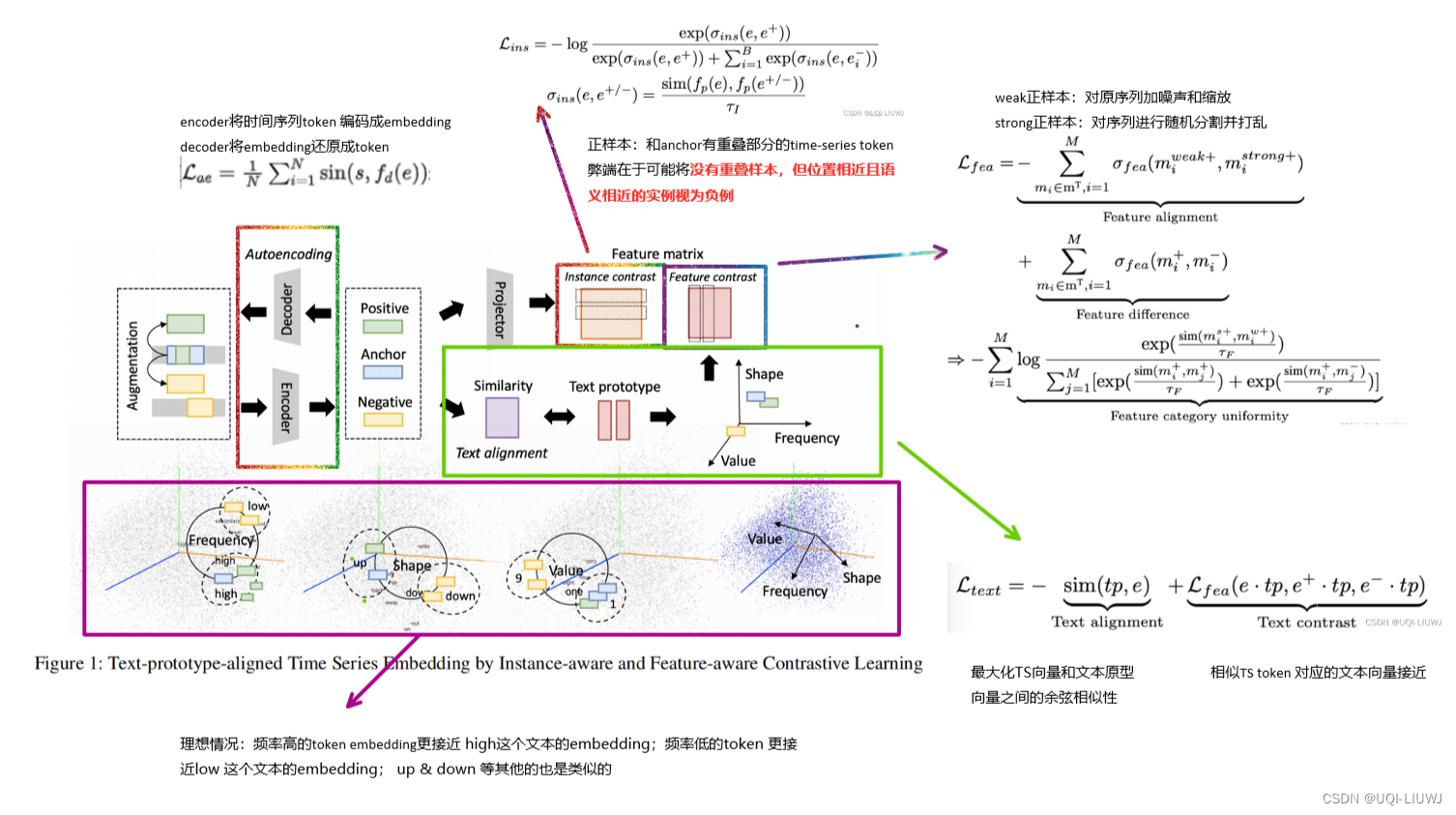
3.1 TS token增强和编码
3.1.1 tokenize和embedding
- 一个多变量时间序列
有D个变量和T个时间点
- 被分割函数Fs: x →s分割成 K个不重叠的子序列
组成的列表
- 每一段
长度是随机的
- s 为时间序列x的token列表
- Fs 通常是滑动窗口
- 使用随机的长度分割TS,得到许多标记 s
- 被分割函数Fs: x →s分割成 K个不重叠的子序列
- 每个token 都可以通过一个嵌入函数
嵌入到一个M维的表示空间中

3.1.2 对比学习正负样本
- 定义一个TS标记 s 作为锚点实例
- 正样本s+,定义两个获取来源
- 第一个是重叠实例
- 使用与 s 有重叠样本的实例
- 第二种是增强实例
——对原序列加噪声和缩放
——对序列进行随机分割并打乱
- 第一个是重叠实例
- 负样本:与s不具有重叠样本的实例
- 接着,利用映射函数
- 对于获得的token,首先通过目标函数
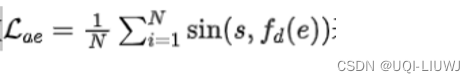 来保证e能够充分表征原始序列信息
来保证e能够充分表征原始序列信息 - fd是decoder,将embedding还原成token
- 对于获得的token,首先通过目标函数
3.2 instance-wise contrast learning (第一类正样本)
- 对于构造的正负实例,保证目标anchor instance 与其对应的正token instance 尽可能相似,与负 token instance 差异尽可能大
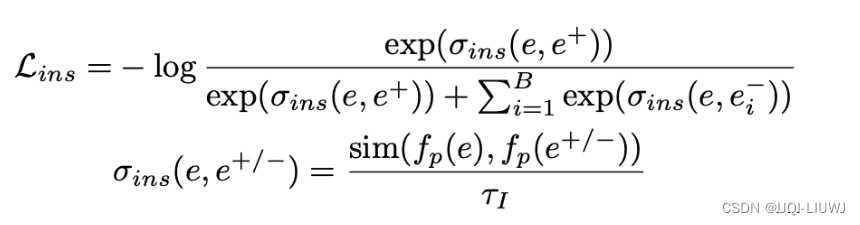
- fp是一个一层的MLP
- instance-wise contrast learning的弊端在于可能将没有重叠样本,但位置相近且语义相近的实例视为负例
- ——>文章进一步设计了feature-wise contrast learning,关注不同列所包含的语义信息
3.3 feature-wise contrast learning
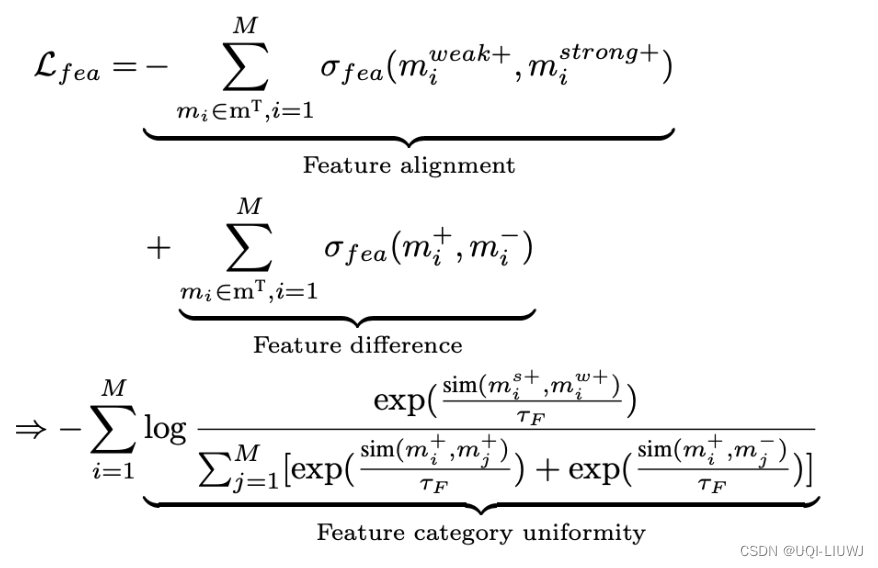
![]() embedding的embedding
embedding的embedding
weak+和strong+都是m+的一部分
- 上述目标函数保证对于每个feature级别,正样本间尽可能相似,负样本间差异尽可能大
- 但是这样容易导致特征表示收缩到一个较小的空间,因此目标函数的最后一项最大化不同特征间差异
3.4 text-prototype-aligned contrast learning
- 为了让LLM更好地理解构建的TS-embedding,文章设计了text-prototype-aligned contrast learning,将其与文本表示空间进行对齐
- 目前预训练的语言模型已经有了自己的 text token embedding
- 例如,GPT-2 将词汇表中的文本token嵌入到维度为 768、1024 和 1280 的表示空间中
- 文章强制地将时间序列标记 e 与文本标记 tp 进行对齐
- 比如,虽然TS-embedding可能缺少对应相关的文本表述,但是可以拉近其与例如数值、形状和频率等描述文本的相似度。
- 通过这种形式的对齐,TS token 就有可能获得表征诸如时间序列大、小、上升、下降、稳定、波动等丰富信息的能力。
- 然而在实际情况中,因为无法提供监督标签或者真实数据作为基准,上述文本时序对齐的结果很可能无法完全符合现实。
- 例如,具有上升趋势的子序列的嵌入可能非常接近下降文本的嵌入,甚至可能是不描述趋势的文本的嵌入
- 但对论文来说,语义是否可以被理解是不相关的
- ——>为了更好地匹配TS-embedding和文本token,文章设计了如下的对比损失函数
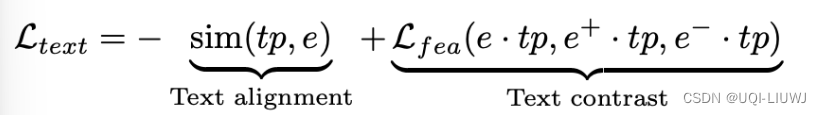
- 第一项text alignment,约束向量的相似性(最大化TS-embedding 与text embedding之间的余弦相似性)
- 第二项text contrast,使用文本原型作为坐标轴将TS嵌入映射到相应的位置,从而保证相似的实例在文本坐标轴中有着类似的表示
- 【注:需要保证两个空间大小类似】
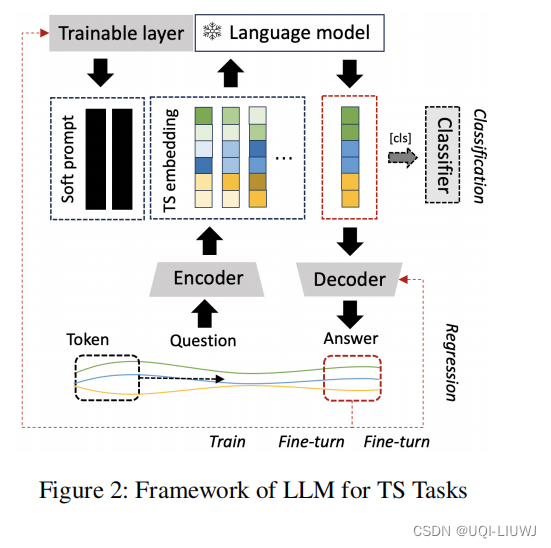
3.5 soft prompt
- 通过上述过程,文章构造了语言模型能够理解的embedding e表示来描述时间序列TS
- 但是语言模型仍然需要被告知如何进行接下来的时间序列任务
- 目前prompt engineering 和 COT(chain of thought)直观且易于理解,能够指导LLM获得较好的结果
- 但这些方法需要连贯的上下文语义,TS-embedding并不具备这样的特效
- ——>本文进一步训练了针对于时序数据的soft prompt,使得语言模型能够识别到不同序列的模式,从而实现时间序列任务
- 这些软提示是针对特定任务的embedding,可以从均匀分布中随机初始化,或从下游任务标签的文本嵌入中获取初始值、从词汇表中最常见的词汇中获取初始值等
- 获取prompt的目标函数如下:
- 文章提到有监督微调方法能有效提高下游TS任务的准确性
- 但训练成本高昂,同时无法保证微调后的语言模型能够有效理解TS-embedding中的语义信息
- ——>文章放弃了有监督微调而采用了训练soft prompt的方式
- 同时文章也证明了经过训练soft prompt能够达到有监督微调相似的效果
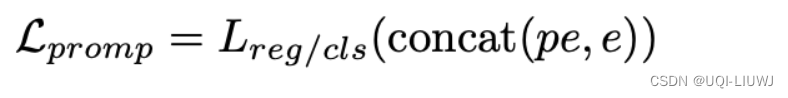
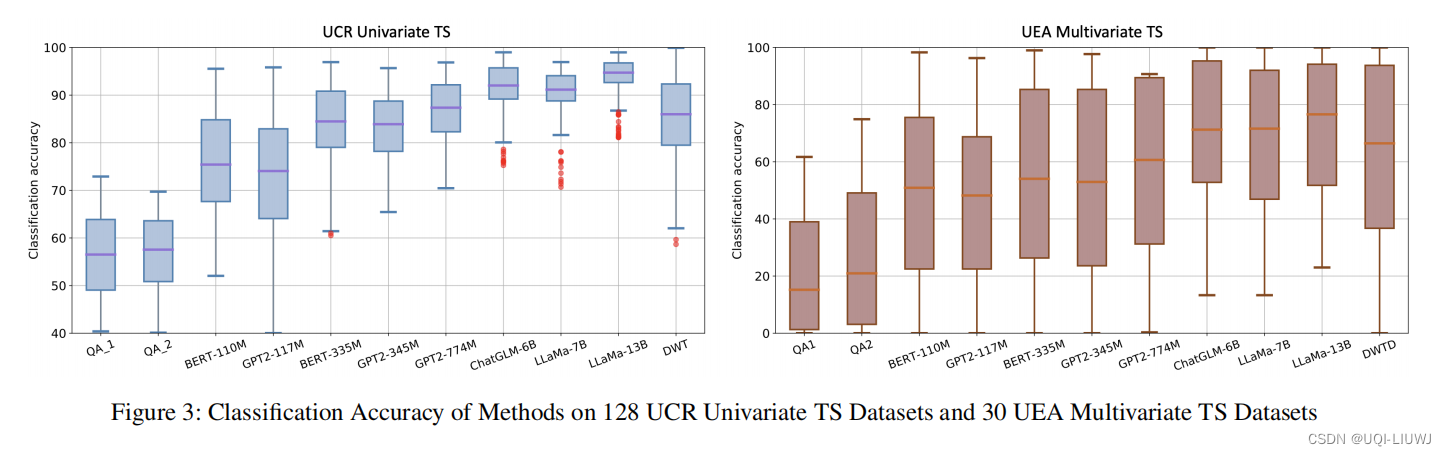
4 实验
4.1 实验结果
分类
预测

QA指的是直接给大模型prompt,让他回答问题
1) [Q] Forecast the next value of the given [domain] sequence: [numerical sequence]. [A] ;
2) [Q] Forecast the next value of sequence with average of [numerical value], variance of [numerical value], and sampling rate of [numerical value]. [A]
4.2 案例研究
- 使用最近邻方法在冻结的LLM的词嵌入空间中找到一个TS标记匹配的文本
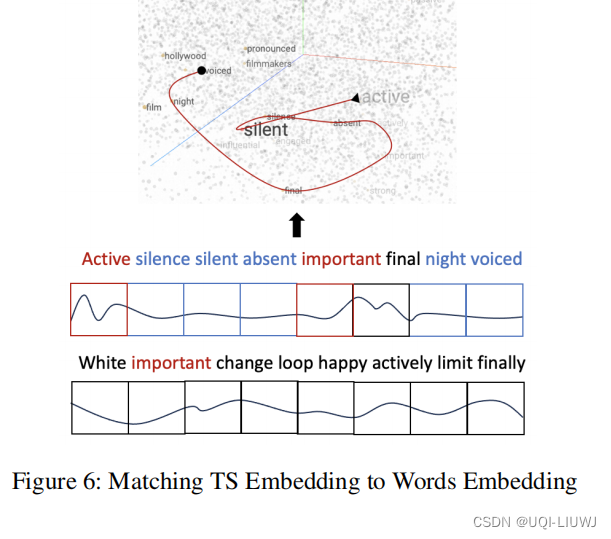
大多数单词都是关于情感的形容词和名词
通过提示,模型将把TS分类任务视为一个情感分类任务
这篇关于论文笔记:TEST: Text Prototype Aligned Embedding to ActivateLLM’s Ability for Time Series的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




