series专题

【HDU】4927 Series 1 高精度
传送门:【HDU】4927 Series 1 题目分析:公式很好推,到最后就是C(n-1,0)*a[n]-C(n-1,1)*a[n-1]+C(n-1,2)*a[n-2]+...+C(n-1,n-1)*a[n]。 用C(n,k)=C(n,k-1)*(n-k+1)/k即可快速得到一行的二项式系数。 我看JAVA不到1000B 15分钟就能过。。。我又敲了大数模板然后将近2个小时才过T U

【HDU】4928 Series 2 模拟
传送门:【HDU】4928 Series 2 题目分析: 代码如下: #include <cstdio>#include <cstring>#include <algorithm>using namespace std ;#define REP( i , a , b ) for ( int i = ( a ) ; i < ( b ) ; ++ i )#

PostgreSQL 中的 `generate_series` 函数使用
1. 概述 在 PostgreSQL 中,generate_series 是一个非常实用的内置函数,它能够根据给定的起始值和结束值生成一系列连续的数字。这一功能对于需要生成大量连续数据或进行批量操作的场景非常有用。本文将详细介绍 generate_series 函数的基本用法,并通过一些简单的示例帮助你更好地理解和应用这一函数。 2. 基本用法 generate_series 函数的基本语法

echarts中series中的数据如何如何循环显示数据
echarts中的数据格式如下 var option = { title : { text: '月份对比', subtext: '' }, tooltip : { trigger: 'axis' }, legend: { data:['3月','4月','5月','6月'] }, toolbox: { show : false, feature : { dataView : {show: tru

Pandas-高级处理(六):map()【将自定义函数作用于Series的每个元素】、apply()【将自定义函数作用于DF的行或者列】、applymap()函数【将自定义函数作用于DF的所有元素】
一、map map()是Series对象的一个函数,DataFrame中没有map(),map()的功能是将一个自定义函数作用于Series对象的每个元素。 现在使用map()函数来将data1这一列的数据改为保留三位小数显示 df['data1'] = df['data1'].map(lambda x : "%.3f"%x) 二、apply apply()函数的功能是将一个自定

论文笔记:Estimating future human trajectories from sparse time series data
sigspatial 2023 humob竞赛paper hiimryo816/humob2023-MOBB (github.com) 1 数据集分析 这里只分享了HuMob数据集1的内容 1.1 假日分析 对HuMob数据集#1地理数据的方差分析显示了非工作日的模式 在某些天的y坐标方差中有显著的峰值,这是非工作日的象征【x坐标有相似的模式】 ——>识别了任务1数据集中最有可能是
Cisco 2500 Series Access Server User Guide开头
读到Preparing to Install the Cisco 2500 Series Access Server 2-3

【读论文】Learning perturbations to explain time series predictions
文章目录 Abstract1. Introduction2. Background Work3. Method4. Experiments4.1 Hidden Markov model experiment4.2 MIMIC-III experiment 5. ConclusionReferences 论文地址:Learning Perturbations to Explain

《A DECODER-ONLY FOUNDATION MODEL FOR TIME-SERIES FORECASTING》阅读总结
介绍了一个名为TimeFM的新型时间序列预测基础模型,该模型受启发于自然语言处理领域的大语言模型,通过再大规模真实世界和合成时间序列数据集上的预训练,能够在多种不同的公共数据集上实现接近最先进监督模型的零样本预测性能。 该模型使用真实世界和合成数据集构建的大型时间序列语料库进行预训练,并展示了在不同领域、预测范围和时间粒度的未见数据集上的准确零样本预测能力。 1、引言 时间序列在零售、金融、
LLMs:《A Decoder-Only Foundation Model For Time-Series Forecasting》的翻译与解读
LLMs:《A Decoder-Only Foundation Model For Time-Series Forecasting》的翻译与解读 导读:本文提出了一种名为TimesFM的时序基础模型,用于零样本学习模式下的时序预测任务。 背景痛点:近年来,深度学习模型在有充足训练数据的情况下已成为时序预测的主流方法,但这些方法通常需要独立在每个数据集上训练。同时,自然语言处理领域的大规模预训练
【Python数据分析】Pandas_Series如何转变为DataFrame
1.使用 pd.DataFrame()构造函数 可以使用pd.DataFrame()构造函数将 Series 转换为 DataFrame。在构造函数中,将 Series 作为一个列传递给 DataFrame,并且可以通过指定列名来为 DataFrame 的列命名。 代码示例: import pandas as pddata=[10,20,30,40,50]index = ['A','B'
POJ 3233 Matrix Power Series 矩阵快速幂求A+A2+A3+…+Ak
题意 :给出n k m 和一个n*n的矩阵A 求A + A2 +A3 + … + Ak 参考http://blog.csdn.net/wangjian8006/article/details/7868864 构造矩阵很重要啊!!! 弱菜不会啊 #include <cstdio>#include <cstring>const int mod = 10000;const int maxn

Pandas 报错 TypeError: ‘Series‘ objects are mutable, thus they cannot be hashed
一、需求 根据原始 CSV 文件的列 A 的值,添加一列 B。 二、尝试 1 1. 将 A 列与 B 列对应的值写入字典 dict,A 列为 key,B 列为 value。 2. 将 CSV 文件处理为 DataFrame。 3. import pandas as pd# 如果 df['A']存在于 dict_a 中,则取 value,值,否则使用默认值 15dict_a = {'
PostgreSQL 如何使用generate_series()函数
什么是generate_series()函数? generate_series()是PostgreSQL中一个非常实用的函数,它可以生成指定范围内的连续整数序列。该函数有多个用途,其中之一是在表中填充多个列。 在表中填充多个列 让我们以一个具体的例子开始。假设我们有一个名为”employees”的表,该表包含员工的姓名、年龄和部门信息。现在,我们想在表中添加一个新的列,用于记录员工的工作经验

Echats-wordcloud 文字云图的踩坑点【Unknown series wordCloud】
在词云渲染时遇到渲染不出来的问题: 原因分析: 1、echart和wordcloud版本不匹配(我的是匹配的) 解决方案: 1、echart和wordcloud版本要匹配: echart4x 使用wordcloud@1x版本 echart5x 使用wordcloud@2x版本 echart5版本需要单独按照wordcloud,安装插件不要使用cnpm,正常使用npm 可以参

已解决Error || KeyError: ‘The truth value of a Series is ambiguous‘
已解决Error || KeyError: ‘The truth value of a Series is ambiguous’ 🚀 原创作者: 猫头虎 作者微信号: Libin9iOak 作者公众号: 猫头虎技术团队 更新日期: 2024年6月6日 博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试
POJ - 3233 Matrix Power Series (矩阵等比二分求和)
Description Given a n × n matrix A and a positive integer k, find the sum S = A + A2 + A3 + … + Ak. Input The input contains exactly one test case. The first line of input contains three
python的DataFrame和Series
Series、DataFrame 创建 pd.Series()pd.DataFrame() # 字典{'列名':[值1,值2],} [[]] [()] numpy Pandas的底层的数据结构,就是numpy的数组 ndarray 常用属性 shape (行数,) (行数,列数) values → ndarray index 索引名 size columns 列名

echarts-series的x,y轴的规则
series的data与x,y轴的匹配规则 如果series的data为[1,2,3,4,5,6] 1.如果x,y轴都是类目轴,且data没有与x,y轴的值匹配上,则无效。 2.如果x,y轴都为类目,data中能够跟类目轴上的字符串对应上,轴,有效。 3.如果都为value.,则按数值生成x,y轴然后按数值标在对应的位置上。 x,y轴都是类目轴,data没有与x,y轴的值匹配上 let o

Keras: list、ndarray、Series、DataFrame
list: https://foofish.net/python-list-top10.html 列表是最常用的数据类型之一,本文整理了 StackOverflow 上关于列表操作被访问最多的10个问答,如果你在开发过程中遇到这些问题,不妨先思考一下如何解决。 In [55]: s1 = [] In [56]: x1 = [1,2] In [57]: y1 = [3,4] In [58
UVA 10253 - Series-Parallel Networks(数论+计数问题+递推)
题目链接:10253 - Series-Parallel Networks 白书的例题。 这题也是需要把问题进行转化,一个并联可以分为几个串联,然后串联可以分成边。 如此一来,最后叶子结点种数会是n,问题转化为去分配叶子结点,使得总和为n。 书上有两种方法,一种直接去递归,利用组合数学的方式去计算答案。 一种是推出递推式: 设dp[i][j]为一共j个

数据分析-day04-pandas-dataFrame、series的复合索引的操作
#!usr/bin/env python#-*- coding:utf-8 _*-'''@author:Administrator@file: pandas_dataframe_series_index_demo.py@time: 2020-01-05 下午 1:33'''import pandas as pd;import numpy as npa = pd.Data

influxdb启动报错:open tsdb store: mkdir /var/lib/influxdb/data_internal/_series: permission denied
在技术群看到有人遇到了这个问题,好奇的问了他是怎么解决的,这里做个记录 influxdb启动的时候报错:open tsdb store: mkdir /var/lib/influxdb/data_internal/_series: permission denied。 解决
矩阵十题【二】 poj 1575 Tr A poj 3233 Matrix Power Series
poj 1575 Tr A 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1575 题目大意:A为一个方阵,则Tr A表示A的迹(就是主对角线上各项的和),现要求Tr(A^k)%9973。 数据的第一行是一个T,表示有T组数据。 每组数据的第一行有n(2 <= n <= 10)和k(2 <= k < 10^9)两个数据。接下来有n行,每行有n
pandas-series总结
#pandas的学习#Series 一组数组已经与这组数组的数据标签(索引)完成的import pandas as pdobj=pd.Series([4,7,-5,3])print(obj)#可以自己建立索引obj2=pd.Series([4,7,-5,3],index=['a','b','c','d'])print(obj2)#可以通过索引的方式选取对应的数值print(obj
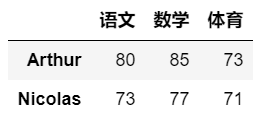
Python 科学计算库 — Pandas 基本数据结构:Series 和 DataFrame
导入Pandas模块:import pandas as pd Panda有两种数据结构,分别是Series 和DataFrame。 Series:类似于一维数组的对象,是由一组数据(各种NumPy数据类型)及一组与之相关的数据标签(索引)组成。仅由一组数据也可产生Series 对象。注意:Series 中的索引值是可以重复的。DataFrame:表格型的数据结构,由一组有序的列组成,每列可以是不