本文主要是介绍文章解读与仿真程序复现思路——电力系统自动化EI\CSCD\北大核心《提升光储充电站运行效率的多目标优化配置策略》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》
论文与完整源程序_电网论文源程序的博客-CSDN博客![]() https://blog.csdn.net/liang674027206/category_12531414.html
https://blog.csdn.net/liang674027206/category_12531414.html
电网论文源程序-CSDN博客电网论文源程序擅长文章解读,论文与完整源程序,等方面的知识,电网论文源程序关注python,机器学习,计算机视觉,深度学习,神经网络,数据挖掘领域.https://blog.csdn.net/LIANG674027206?type=download
这份文件是一篇关于提升光储充电站运行效率的多目标优化配置策略的研究论文。以下是该论文的核心内容概述:
-
研究背景与意义:光储充电站的运行效率直接影响其经济效益和电网侧的电能质量。在进行容量配置时,对运行效率考虑不足可能导致不必要的电能损耗。
-
研究目标:提出一种提升光储充电站运行效率的多目标优化配置策略,以提高充电站的经济性和电网侧电能质量。
-
方法论:
- 运行效率评估:分析光储充电站变换器与内源线路功率损耗对运行效率的影响,提出评估指标与计算方法。
- 优化配置策略:建立以充电站经济效益、运行效率、电网侧峰谷供电功率补偿能力最佳为优化目标的多目标容量优化配置策略。
- 算法改进:提出一种改进的非支配排序遗传算法(NSGA-II)用于求解优化策略。
-
仿真算例:选取中国西南地区某典型光储充电站运营场景进行算例验证,通过算例分析优化策略的有效性与优越性。
-
结论:所提出的多目标优化配置策略能够有效提升光储充电站的运行效率,降低电能损耗,提高经济效益,并且对电网侧电能质量有积极影响。
-
关键词:光储充电站;运行效率;容量优化配置;多目标优化;改进非支配排序遗传算法。
这篇论文为光储充电站的优化配置提供了新的视角和方法,特别是在提升运行效率和经济效益方面,对于促进新能源汽车的普及和电网的可持续发展具有重要的理论和实践价值。
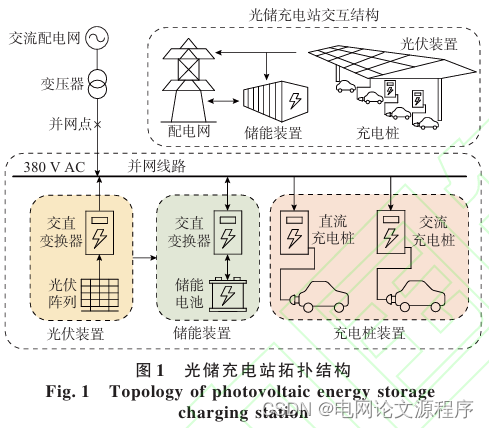
为了复现论文中的仿真算例,我们需要遵循以下步骤,并将其表示为伪代码:
-
初始化参数:设置光储充电站的初始参数,包括光伏装置、储能装置、充电桩、变换器、输电线路等的参数。
-
运行效率评估:根据论文中的方法,计算光储充电站的运行效率。
-
建立优化模型:构建多目标优化模型,包括经济效益、运行效率和电网侧峰谷供电功率补偿能力。
-
算法实现:实现改进的非支配排序遗传算法(NSGA-II),用于求解多目标优化问题。
-
执行仿真:运行算法,进行仿真实验,并记录结果。
-
结果分析:分析仿真结果,验证优化策略的有效性。
以下是伪代码表示的复现思路:
# 伪代码:提升光储充电站运行效率的多目标优化配置策略# 1. 初始化参数
def initialize_parameters():# 设置光储充电站的初始参数# 此处省略具体参数设置代码return params# 2. 运行效率评估
def evaluate_operation_efficiency(params):# 根据论文中的方法计算运行效率# 此处省略具体计算代码return efficiency# 3. 建立优化模型
def build_optimization_model(params):# 构建多目标优化模型# 此处省略具体模型构建代码return model# 4. 算法实现
def improved_NSGA_II(model):# 实现改进的非支配排序遗传算法# 此处省略算法具体实现代码return pareto_front# 5. 执行仿真
def run_simulation(model, pareto_front):# 运行算法进行仿真# 此处省略仿真执行代码return simulation_results# 6. 结果分析
def analyze_results(simulation_results):# 分析仿真结果# 此处省略结果分析代码return analysis# 主函数
def main():params = initialize_parameters()efficiency = evaluate_operation_efficiency(params)model = build_optimization_model(params)pareto_front = improved_NSGA_II(model)simulation_results = run_simulation(model, pareto_front)analysis = analyze_results(simulation_results)# 输出最终分析结果print(analysis)if __name__ == "__main__":main()请注意,上述伪代码仅为复现论文仿真的大致思路框架,实际编程时需要根据具体的数据格式、模型细节和算法实现进行详细实现。特别是运行效率评估、多目标优化模型构建和改进NSGA-II算法的实现部分,需要根据论文中的算法描述和数学模型进行编程实现。此外,实际应用中还需要考虑模型的验证和测试,确保复现的结果与论文中的结果一致。
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》
论文与完整源程序_电网论文源程序的博客-CSDN博客![]() https://blog.csdn.net/liang674027206/category_12531414.html
https://blog.csdn.net/liang674027206/category_12531414.html
电网论文源程序-CSDN博客电网论文源程序擅长文章解读,论文与完整源程序,等方面的知识,电网论文源程序关注python,机器学习,计算机视觉,深度学习,神经网络,数据挖掘领域.https://blog.csdn.net/LIANG674027206?type=download
这篇关于文章解读与仿真程序复现思路——电力系统自动化EI\CSCD\北大核心《提升光储充电站运行效率的多目标优化配置策略》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



