本文主要是介绍表格存储最佳实践:一种用于存储时间序列数据的表结构设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在表格存储的数据模型这篇文章中提到:
在表格存储内部,一个表在创建的时候需要定义主键,主键会由多列组成,我们会选择主键的第一列作为分片键。当表的大小逐渐增大后,表会分裂,由原来的一个分区自动分裂成多个分区。触发分裂的因素会有很多,其中一个很关键的因素就是数据量。分裂后,每个分区会负责某个独立的分片键范围,每个分区管理的分片键范围都是无重合的,且范围是连续的。在后端会根据写入数据行的分片键的范围,来定位到是哪个分片。
表会以分区为单位,被均匀的分配到各个后端服务器上,提供分布式的服务。
在表格存储的最佳实践中提出,一个设计良好的主键,需要避免访问压力集中在一个小范围的连续的分片键上,也就是说避免热点分片。设计良好的表结构,整张表的访问压力能够均匀的分散在各个分片上,这样才能充分利用后端服务器的能力。
那在使用表格存储来存储时间序列数据时,我们应该如何设计表的结构,避免热点分片的问题?
假设我们需要设计一张表,用于存储监控信息,监控信息包括:时间戳(timestamp)、监控指标名称(metric)、主机名(host)和监控指标值(value)。而我们的查询场景为,指定监控指标名称和时间范围,查询该监控指标的所有值。通常我们会这样设计我们的表结构:
表设计一:
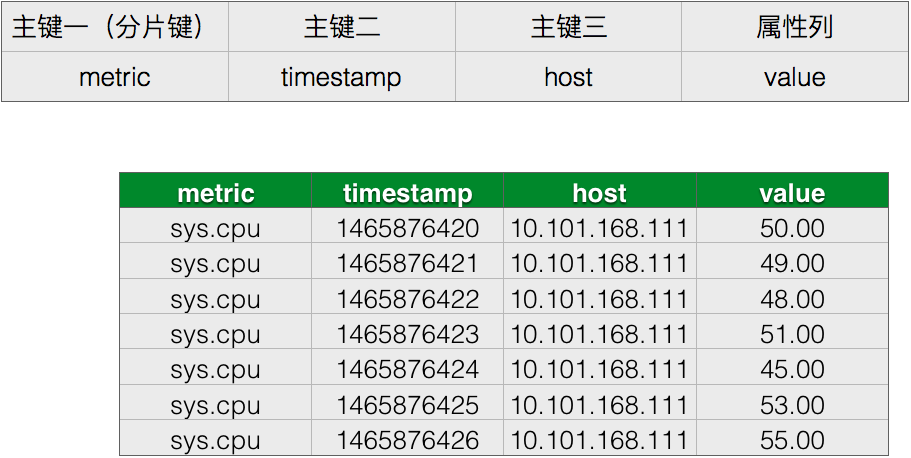
该设计以metric列为分片键,能够满足查询的场景,但是有很严重的分片热点问题。假设一个metric下每秒采集一个点,而我们有上百台设备,则该分片每秒需要能够提供上百的写入能力,这点也没有问题。但是由于使用了metric作为分片键,metric的值为常量,随着数据量的上涨,其无法再进行分裂,会导致该分片下的数据量不断膨胀,可能超过一台物理机所能承受的上限,存在分片数据量的热点。
为了解决这个问题,我们对分片键做一个调整:
表设计二:
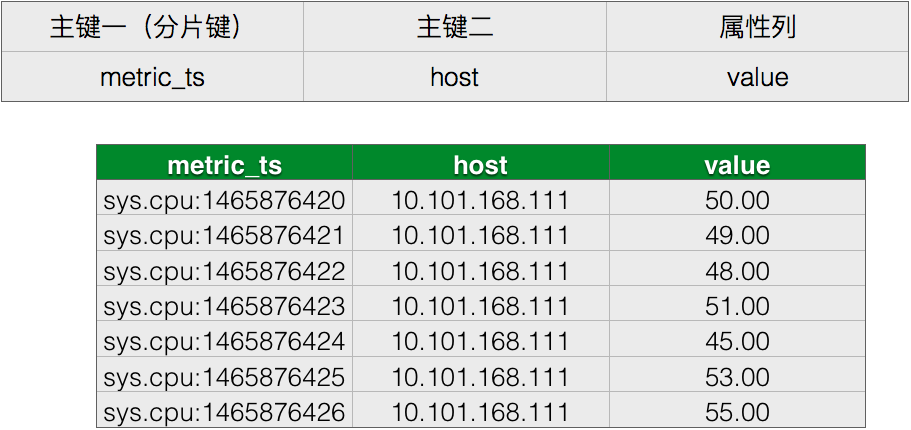
我们将第一列主键和第二列主键合并为一列主键作为分片键,在数据的分布模式上并没有什么变更,但是引入了时间这个维度后,我们避免了分片数据量的热点。但是当host规模变大,从上百膨胀到上万,则该张表需要每秒提供上万并发的写入能力。我们需要将该表的写入压力均匀的分散到各个分片上,但是由于其数据的特点,每次写入的数据都是最新时间的数据,其写入压力永远集中在最新时间戳所在的分片上。
为了将写入压力均匀的分散到分片上,我们再对表做一个重新设计:
表设计三:
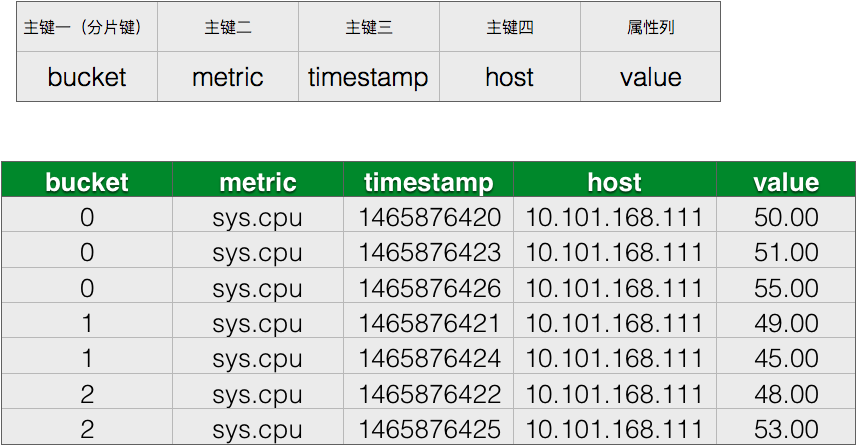
我们引入一个新的列 - bucket,在每行数据写入前,为每行数据分配一个桶(可随机分配),以桶的编号为分片键(HBase中有类似的解决方案,称为salted key)。桶的个数任意,可扩张,在写入之前将数据预分桶之后,也就解决了写入压力热点的问题,因为写入压力永远是均匀分配在各个桶上的。可根据具体的写入压力,决定桶的个数。
数据分桶后,如果需要读取完整的数据,需要在每个桶内都分别执行一遍查询后将数据进行汇总,可以使用我们SDK提供的异步接口,来并行的查询每个桶,提高查询的效率。
总结
在时间序列存储的场景,例如监控数据或者日志数据,通常比较难解决的是写入的问题,传统的数据库难以承载如此大数据量、高并发的写入压力。
表格存储能够提供非常优秀的写入能力,在阿里内部得到到了正好的实践和证明。但是若要发挥其强度的写入能力,需要有一个良好的表结构设计。
本篇文章给出了一个存储时间序列数据库的最佳实践,供参考。但表结构设计并不是千篇一律的,需要根据不同的业务场景设计做灵活的调整,欢迎一起探讨。
转:https://yq.aliyun.com/articles/54644?spm=a2c4e.11153940.blogcont54785.11.7fef7f4bdqjlWp
这篇关于表格存储最佳实践:一种用于存储时间序列数据的表结构设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




