本文主要是介绍postgis 建立路径分析,使用arcmap处理路网数据,进行拓扑检查,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在postgresql+postgis上面,对路网进行打断化简,提高路径规划成功率。
一、创建空间库以及空间索引
CREATE EXTENSION postgis;
CREATE EXTENSION pgrouting;
CREATE EXTENSION postgis_topology;
CREATE EXTENSION fuzzystrmatch;
CREATE EXTENSION postgis_tiger_geocoder;
CREATE EXTENSION address_standardizer;
二、准备路网数据及拓扑检查
生成路网拓扑数据,即线段
https://blog.csdn.net/m0_38058163/article/details/91971491
数据处理办法:
1、规划的路线不准,把线分开,
2、添加折点 arcgis中编辑工具\增密,添加折点 2e-4
3、折点断开线 数据管理工具\要素\在折点处分割要素
三、导入路网边数据
采用qgis,或者postgis工具,导入处理好的路网数据
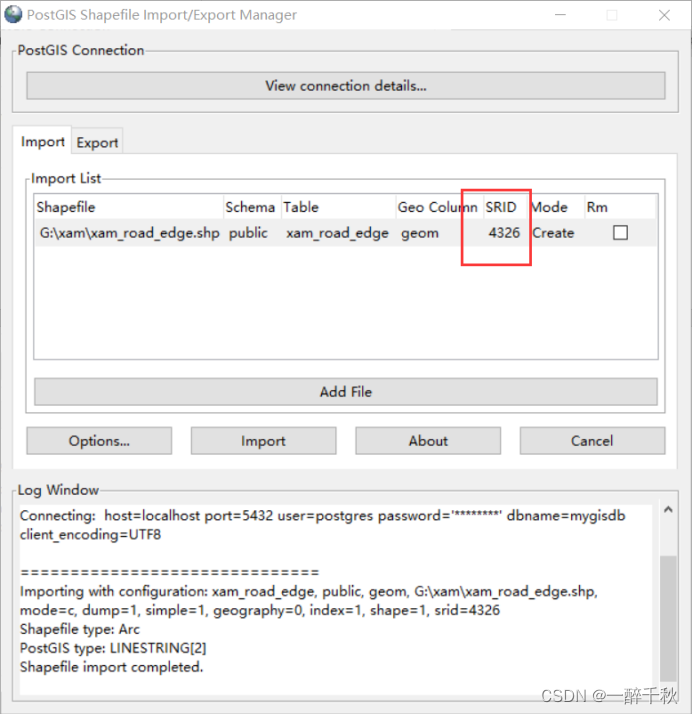
1、设置坐标系
SELECT UpdateGeometrySRID('xam_road_edge','geom',4326);
2、空间图层增加字段
ALTER TABLE xam_road_edge
ADD COLUMN source integer,
ADD COLUMN target integer,
ADD COLUMN length double precision;
select pgr_createTopology('hbroad', 0.000001,rows_where:='gid > 10000', the_geom:='geom', id:='gid', source:='source', target:='target');
SELECT pgr_createTopology('xam_road_edge', 0.00001, 'geom', 'gid');
--拓扑检查
select pgr_analyzeGraph('xam_road_edge', 0.0001, 'geom', 'gid');
CREATE INDEX source_idx ON xam_road_edge("source");
CREATE INDEX target_idx ON xam_road_edge("target");
--添加线段端点坐标
ALTER TABLE xam_road_edge ADD COLUMN x1 double precision; --创建起点经度x1
ALTER TABLE xam_road_edge ADD COLUMN y1 double precision; --创建起点纬度y1
ALTER TABLE xam_road_edge ADD COLUMN x2 double precision; --创建起点经度x2
ALTER TABLE xam_road_edge ADD COLUMN y2 double precision; --创建起点经度y2
--给x1、y1、x2、y2赋值
UPDATE xam_road_edge SET x1 =ST_x(ST_PointN(geom, 1));
UPDATE xam_road_edge SET y1 =ST_y(ST_PointN(geom, 1));
UPDATE xam_road_edge SET x2 =ST_x(ST_PointN(geom, ST_NumPoints(geom)));
这篇关于postgis 建立路径分析,使用arcmap处理路网数据,进行拓扑检查的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





