本文主要是介绍AI论文速读 | 2024[WWW]不只是路线:联合 GPS 和路线建模的轨迹表示学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:More Than Routing: Joint GPS and Route Modeling for Refine Trajectory Representation Learning
作者:Zhipeng Ma(麻志鹏), Zheyan Tu, Xinhai Chen, Yan Zhang, Deguo Xia, Guyue Zhou, Yilun Chen, Yu Zheng(郑宇), Jiangtao Gong(龚江涛)
机构:西南交通大学,清华大学智能产业研究院(AIR),百度,京东
论文链接:https://arxiv.org/abs/2402.16915
Cool Paper:https://papers.cool/arxiv/2402.16915
Youtube 3分钟Pre:https://www.youtube.com/watch?v=IA3quCF0LWM
TL, DR:这篇论文提出了一种名为JGRM的新型轨迹表示学习框架,通过结合GPS轨迹和路线建模,并利用自监督技术来提高轨迹数据的表示能力,从而在多个下游任务中取得了优于现有方法的性能。
关键词:轨迹表示学习,自监督,多模态融合

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个新的轨迹表示学习框架(JGRM),旨在解决以下问题:
- GPS轨迹的噪声和冗余问题:传统的GPS轨迹处理方法通常关注于简化轨迹以过滤噪声,但这忽略了GPS数据中包含的运动细节,限制了轨迹表示学习的表现能力。
- 轨迹表示的泛化问题:早期的轨迹表示学习方法通常针对特定下游任务设计,并且使用特定任务的损失进行训练,这导致表示的泛化能力较差,难以适应其他任务。
- 轨迹表示的多模态融合问题:GPS轨迹和路线轨迹分别从不同的角度描述了移动行为,但现有的方法通常只关注单一类型的轨迹,没有充分利用两种轨迹的互补性。
为了解决这些问题,论文提出了一个基于自监督技术的联合GPS和路线建模的表示学习框架。该框架通过考虑GPS轨迹和路线轨迹作为单一移动观察的两种模式,并通过模态间信息交互来融合信息,以提高轨迹表示的质量和泛化能力。
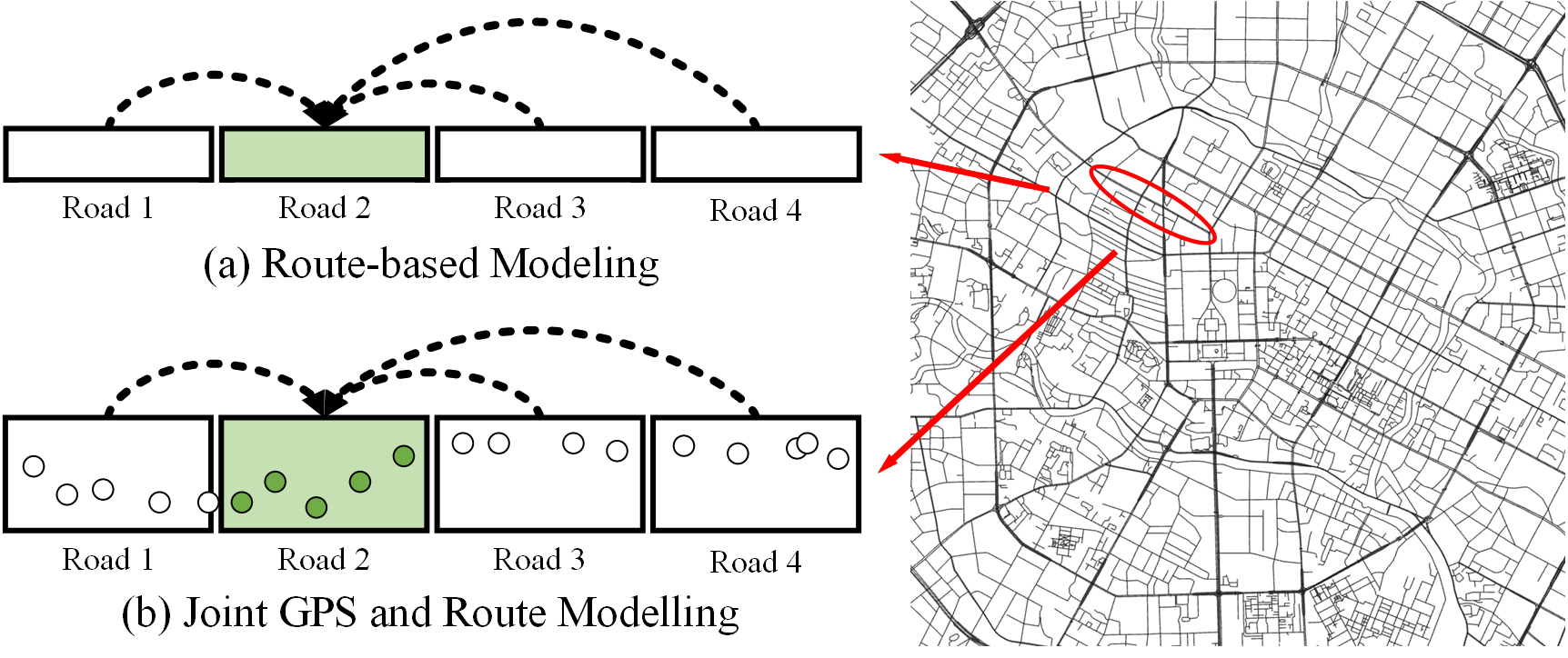
如(a)所示,路线轨迹中的一个路段,只能通过之前后的路段进行建模,并且缺乏直接的自我观察(self-observation)。相比之下,GPS轨迹中的路段提供了更丰富的采样信息,允许对路段实体的细粒度表示。此外,路线轨迹中的路段上下文可以进一步细化道路表示。因此,路径轨迹与GPS轨迹的联合建模可以实现宏观和微观视角的有效结合
Q: 有哪些相关研究?
A: 论文中提到的相关研究可以分为以下几个类别:
- GPS轨迹表示学习:
- traj2vec:使用窗口方法对GPS轨迹进行时空约束,将每个窗口编码为序列中的一个标记。
- t2vec、NeuTraj 和 T3S:通过使用离散化的栅格窗口处理原始轨迹,以获得相应的标记。
- TrajCL:使用Douglas-Peucker算法简化轨迹,以在轨迹拓扑上构建窗口。
- 路线轨迹表示学习:
- PIM、Trembr 和 Toast:认为道路网络限制了路线轨迹,并能自然地保持道路网络之间的空间关系。
- ST2Vec、JCLRNT 和 START:引入图编码器进行空间建模,通过道路网络结构进一步限制轨迹表示空间。
- Toast、PIM 和 Trember:关注捕获路线轨迹中的时间关系,设计了不同的时间信息编码方法。
- 自监督学习任务设计:
- Word2vec 和 Node2vec:使用自监督学习通过随机游走生成的序列来学习节点嵌入。
- GAE(Graph Auto-Encoder):通过重构图的邻接矩阵来学习节点嵌入。
- Traj2vec:使用seq2seq模型来学习轨迹表示。
- START:结合旅行语义和时间连续性,设计了自监督任务来训练轨迹表示模型。
- 多模态信息融合:
- VLP(Vision-Language Pre-training):在视觉和语言预训练研究中,引入了共享变换器进行跨模态信息交互。
这些相关研究为论文提出的JGRM框架提供了理论基础和技术背景,特别是在轨迹表示学习、自监督学习任务设计以及多模态信息融合方面。JGRM框架通过结合这些研究成果,提出了一种新的轨迹表示学习方法,以提高轨迹数据的表示能力和泛化性。
Q: 论文如何解决这个问题?
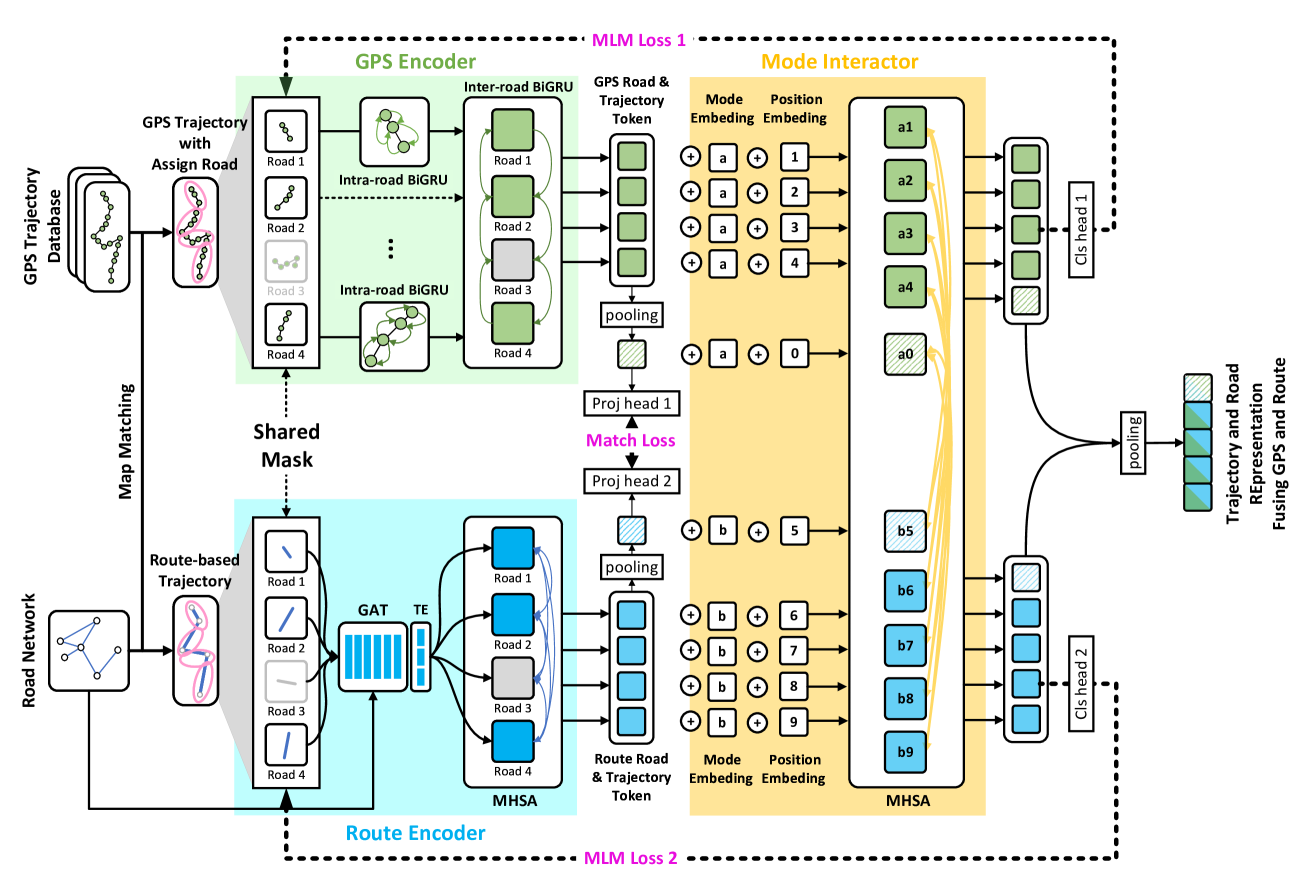
A: 论文通过提出一个名为JGRM(Joint GPS and Route Modeling)的新型表示学习框架来解决上述问题。JGRM框架的关键组成部分和解决策略如下:
- 双模态编码器:
- GPS编码器:使用分层的双向GRU(BiGRU)来处理GPS轨迹,通过嵌入相应的子轨迹并通过道路段分组引导来解决GPS轨迹中的冗余和噪声问题。
- 路线编码器:利用基于道路网络的空间编码器(如GAT)和轻量级时间编码器(TE)来捕获路线轨迹中的时空相关性,并使用Transformer捕获路线轨迹的自相关性。
- 模态交互器:
- 设计了一个共享的Transformer作为模态交互器,用于融合来自GPS轨迹和路线轨迹的信息。这种方法允许两种轨迹模式在表示空间中相互对齐,从而提高表示的质量和泛化能力。
- 自监督学习任务:
- MLM(Mask Language Modeling):通过随机遮蔽轨迹中的路段,然后重建这些路段来提供监督信号。这种任务鼓励模型学习到更连续的时空表示。
- CMM(Cross-Modal Matching):利用GPS轨迹和路线轨迹之间的自然配对关系,通过匹配任务来指导两种模态的表示空间对齐。
- 实验验证:
- 在两个真实世界的数据集(成都和西安)上进行了广泛的实验,验证了JGRM在道路段表示和轨迹表示任务上的有效性。实验结果表明,JGRM在各种设置下都优于现有方法。
通过这些策略,JGRM能够有效地结合GPS轨迹的详细运动信息和路线轨迹的旅行语义,从而提高轨迹表示的质量和泛化能力。此外,自监督学习任务的设计使得模型能够在无需特定下游任务标签的情况下进行训练,这为轨迹表示学习提供了一种新的训练范式。
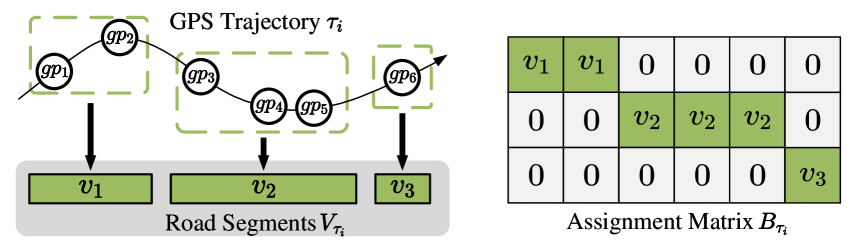
Q: 论文做了哪些实验?

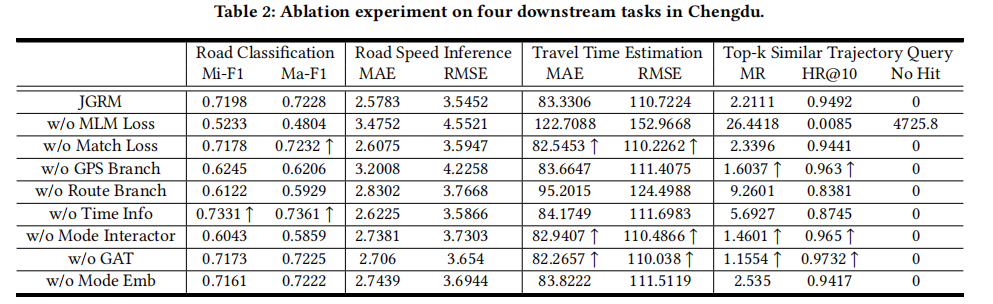
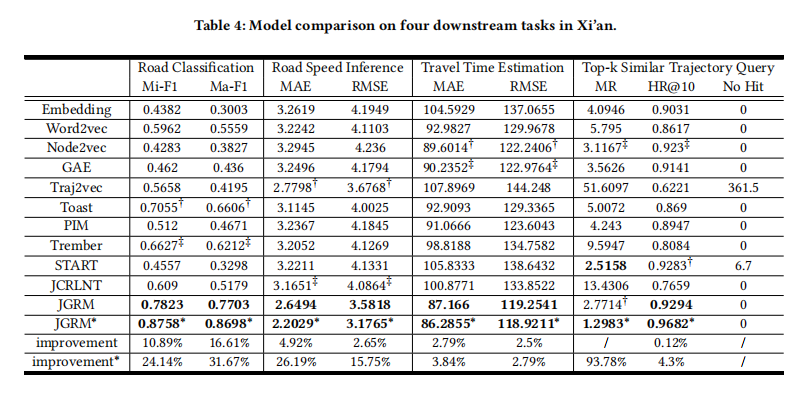
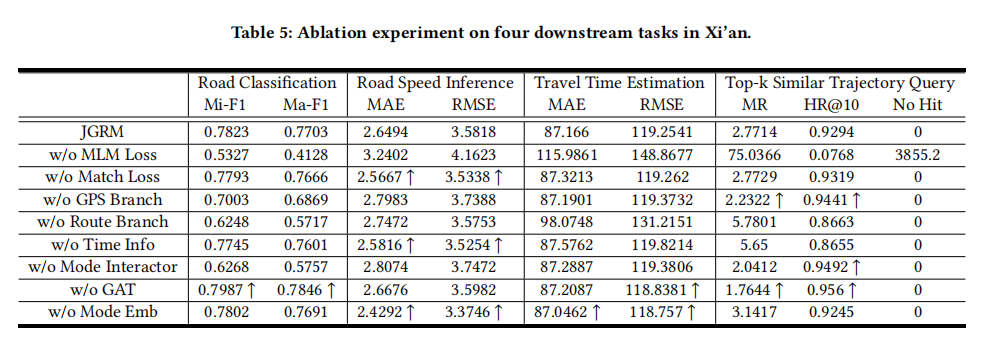
A: 论文中进行了一系列的实验来验证JGRM框架的有效性和性能。以下是主要的实验内容:
- 实验设置:
- 使用了两个真实世界的数据集:成都和西安。
- 数据集包含了GPS轨迹、路线轨迹和道路网络信息。
- 实验将数据分为训练集、验证集和测试集,时间跨度为15天。
- 下游任务:
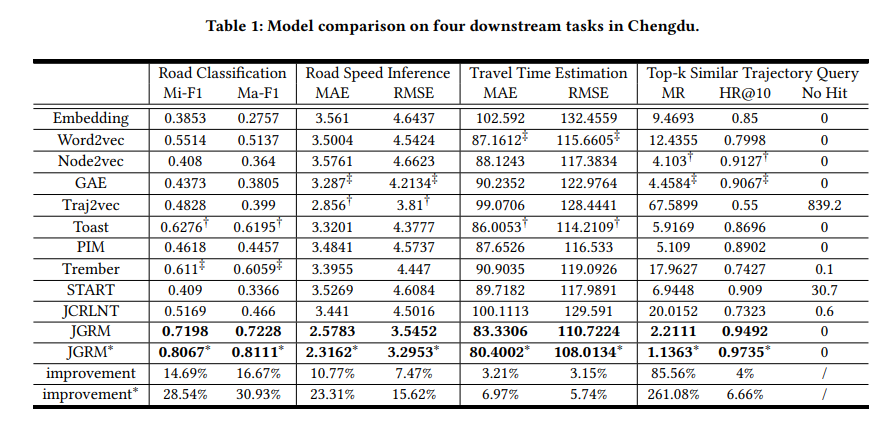
- 道路分类:区分不同类型的道路段。
- 道路速度推断:估计每个道路段的平均速度。
- 行程时间估计:基于路线轨迹估计行程时间。
- Top-k相似轨迹查询:在数据库中找到与查询轨迹最相似的轨迹。
- 性能比较:
- 将JGRM与10种不同的方法进行了比较,这些方法包括随机初始化、基于图的轨迹表示学习、基于GPS的轨迹表示学习和基于路线的轨迹表示学习。
- 使用了不同的评价指标,如准确率(Mi-F1和Ma-F1)、平均绝对误差(MAE)、均方根误差(RMSE)和命中率(MR和HR@10)。
- 消融实验:
- 对JGRM的不同组件进行了消融实验,以评估每个模块对模型性能的贡献。这包括移除MLM损失、Match损失、GPS分支、路线分支、时间信息、模态交互器、GAT和模态嵌入等。
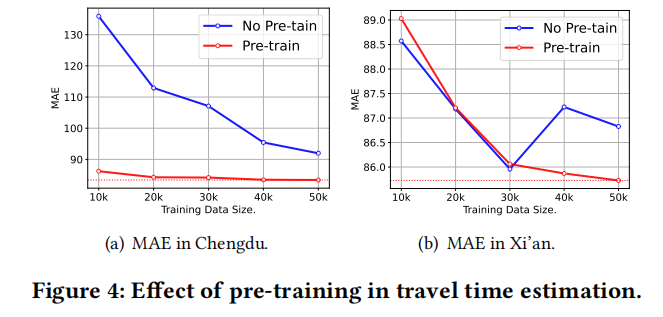
- 预训练模型的有效性:
- 研究了预训练模型在不同数据集大小下的表现,以及预训练对模型性能的影响。
- 模型迁移性研究:
- 评估了JGRM在不同城市之间的迁移能力,包括零样本适应(Zero Shot Adaptation)和少样本微调(Few Shot Finetune)。
- 参数敏感性分析:
- 对关键超参数进行了敏感性分析,包括嵌入大小、路线编码器层数、模态交互器层数、遮蔽长度和遮蔽概率。
- 定性研究:
- 对模态交互器的输出进行了定性分析,以展示不同表示方法在道路段和轨迹表示空间中的表现。
- 案例研究:
- 通过案例研究,比较了JGRM和子优Node2vec方法在Top-k相似轨迹查询任务上的表现。
这些实验全面地评估了JGRM框架的性能,并与其他现有方法进行了比较,从而证明了JGRM在轨迹表示学习方面的优越性。
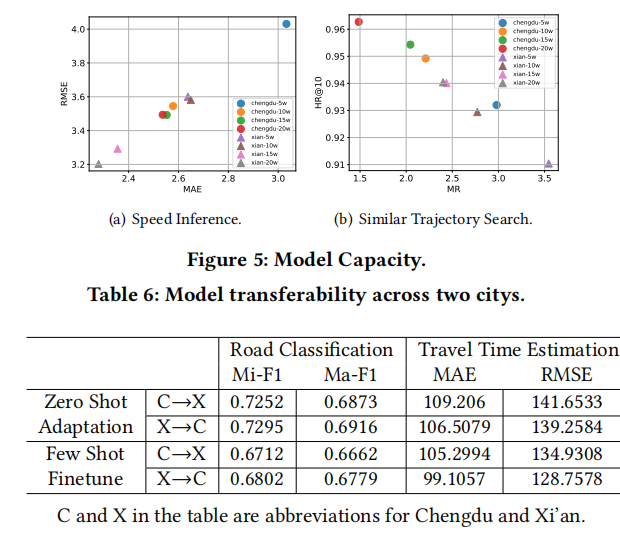
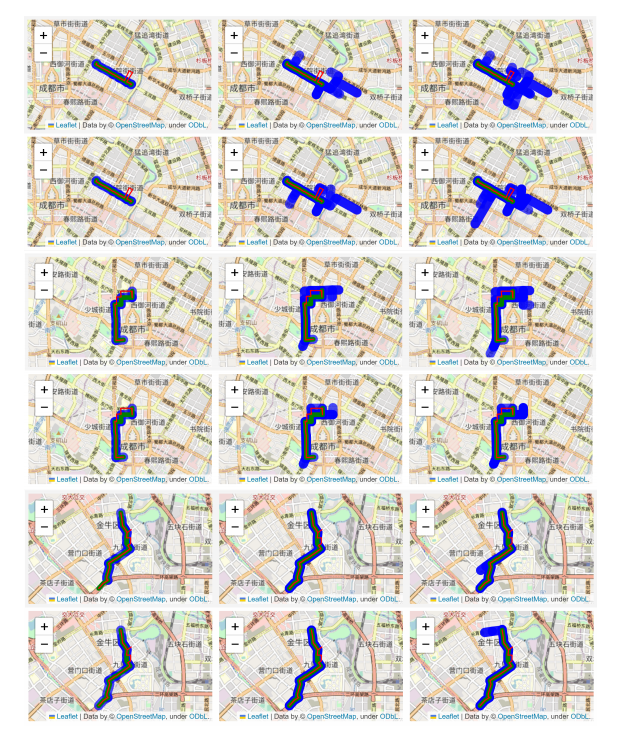
成都数据集中随机选择三个轨迹,并使用JGRM和次优的Node2vec分别获得top-k个相似轨迹查询的轨迹表示(Top-k similar Trajectory Query)。
其中三列分别代表前1、前3和前10的结果,奇数行表示JGRM的结果,偶数行表示Node2vec的结果。红色表示查询轨迹(query),绿色表示关键轨迹(key),蓝色代表查询结果。
结果表明,虽然基于图嵌入的方法对路段的变化很敏感,但它不能捕捉序列、时间和运动学信息。这意味着Node2vec不能区分两个彼此相反的轨迹,也不能区分在同一OD下不同时间的不同用户的轨迹。相比之下,JGRM对绕道行为更为敏感,并且能够捕捉到轨迹中的细微变化。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为JGRM(Joint GPS and Route Modeling)的新型轨迹表示学习框架,旨在通过结合GPS轨迹和路线轨迹的信息来提高轨迹数据的表示能力。以下是论文的主要内容总结:
- 问题背景:传统的GPS轨迹处理方法通常关注于简化轨迹以过滤噪声,但这忽略了GPS数据中包含的运动细节。此外,早期的轨迹表示学习方法通常针对特定下游任务设计,泛化能力较差。
- 方法提出:为了解决这些问题,论文提出了JGRM框架,它包含两个主要的编码器(GPS编码器和路线编码器)以及一个模态交互器。GPS编码器使用分层的双向GRU来处理GPS轨迹,而路线编码器则利用图神经网络(GAT)和时间编码器来捕获路线轨迹的时空相关性。模态交互器通过共享的Transformer来融合两种轨迹的信息。
- 自监督学习:为了训练模型,论文设计了两种自监督学习任务:Mask Language Modeling (MLM) 和 Cross-Modal Matching (CMM)。MLM通过随机遮蔽轨迹中的路段然后重建这些路段来提供监督信号,而CMM则利用GPS轨迹和路线轨迹之间的自然配对关系来指导表示空间的对齐。
- 实验验证:在成都和西安的真实世界数据集上进行了广泛的实验,包括道路分类、道路速度推断、行程时间估计和Top-k相似轨迹查询等下游任务。实验结果表明,JGRM在各种设置下都优于现有方法。
- 消融实验:通过消融实验,论文评估了JGRM中各个组件的贡献,证明了MLM任务在提高模型性能方面的重要性,以及联合建模GPS和路线轨迹的有效性。
- 模型迁移性:研究了JGRM在不同城市之间的迁移能力,包括零样本适应和少样本微调,展示了模型的泛化能力。
- 未来工作:论文提出了未来研究方向,包括动态道路状态表示、多源数据融合、跨领域迁移学习、可解释性和可视化、实时轨迹预测等。
PS和路线轨迹的有效性。
6. 模型迁移性:研究了JGRM在不同城市之间的迁移能力,包括零样本适应和少样本微调,展示了模型的泛化能力。
7. 未来工作:论文提出了未来研究方向,包括动态道路状态表示、多源数据融合、跨领域迁移学习、可解释性和可视化、实时轨迹预测等。
总的来说,JGRM框架通过创新地结合GPS和路线轨迹信息,并利用自监督学习任务,为轨迹表示学习提供了一种新的有效方法。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
这篇关于AI论文速读 | 2024[WWW]不只是路线:联合 GPS 和路线建模的轨迹表示学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







