本文主要是介绍TextCraftor:一种创新的文本编码器微调技术,无需额外数据集改善图像质量与文本对齐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TextCraftor是一种创新的文本编码器微调技术,能够显著提升文本到图像生成模型的性能。
通过奖励函数优化,TextCraftor是一种创新的文本编码器微调技术改善了图像质量与文本对齐,无需额外数据集。从演示图片来看效果相当好。
TextCraftor的提出为文本到图像生成领域带来了新的视角。其在图像编辑、视频合成等领域的应用前景广阔,尤其是在需要高质量和与文本高度对齐的图像生成任务中。此外,TextCraftor的控制生成能力也为个性化内容创作提供了新的可能性。

相关链接
论文链接:https://arxiv.org/pdf/2403.18978.pdf
论文阅读

TextCraftor:你的文本编码器可以是图像质量控制器
摘要
基于扩散的文本到图像生成模型,例如Stable Diffusion已经彻底改变了内容生成领域。尽管他们在图像编辑和视频合成有很强大的能力,但是这些模型并非没有其局限性。
合成一个与输入文本对齐良好的图像仍然是一个挑战,需要详细的提示并多次运行精心制作才能获得满意的结果。 为了减轻这些限制,许多研究都在努力利用各种技术微调预训练的扩散模型即UNet。然而,文本到图像扩散模型训练的关键问题一直存在大部分仍未开发。
是否可能和可行微调文本编码器来提高文本到图像扩散模型的性能?
我们的研究结果表明,在其他大型语言模型的Stable Diffusion中使用时不替换CLIP文本编码器,通过我们提出的微调方法TextCraftor来增强它,从而在定量基准和人的评估。
有趣的是,我们的技术还可以通过插值不同的文本编码器来实现可控的图像生成微调各种奖励。我们也证明了TextCraftor与UNet微调是正交的,并且可以结合进一步提高生成质量。
方法
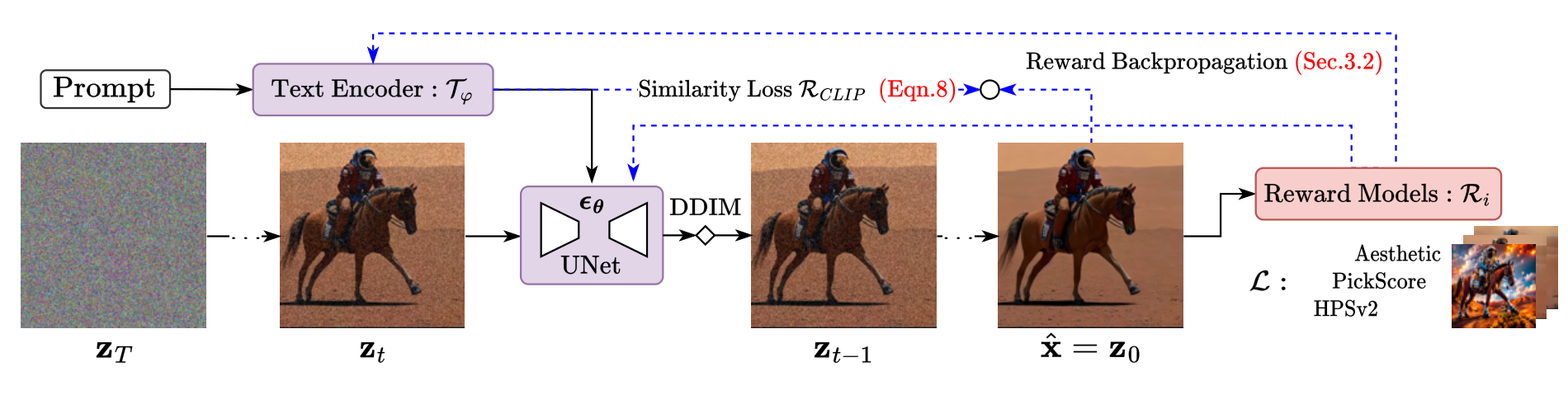
TextCraftor概述:一个基于提示数据和奖励函数的端到端文本编码器微调范例。 将文本嵌入转发到DDIM去噪链中,得到输出图像并计算奖励损失,然后再进行反推。通过最大化奖励来更新文本编码器(以及可选的UNet)的参数。

实验
定性的可视化



-
左:在part-prompts上生成的图像,按照SDv1.5, prompt engineering, DDPO和TextCraftor的顺序。
-
右:来自HPSv2的示例,订购为sv1.5,提示工程和TextCraftor。
不同模型生成结果比较


每个提示显示从三个不同模型生成的图像,分别是SDv1.5,TextCraftor, TextCraftor UNet,从左到右列出。对于所有生成结果随机种子是固定的。
原始文本之间嵌入插值(权重)
0.0)和一个来自TextCraftor(重量1.0),演示 可控的一代。从上到下一行:TextCraftor使用HPSv2, PickScore和Aesthetics作为奖励模型。

混合风格
从不同的奖励模型微调的文本编码器可以协作并作为风格混合。底部列出的权重分别用于组合来自{origin, Aesthetics, PickScore, HPSv2}的文本嵌入。

消融对奖励模型及CLIP的影响
最左边的栏显示原始图像。averaged Aesthetics、PickScore和HPSv2平均得分分别为5.49分、18.19分和0.2672。下面的列显示使用不同的奖励模型合成无CLIP约束和有CLIP约束的图像。奖励分数列在底部。


结论
这项工作提出了TextCraftor,一个稳定而强大的框架来微调预训练的文本编码器来改进文本到图像的生成。只有提示词数据集和预定义的奖励函数,TextCraftor可以显着提高生成质量相比预训练的文本到图像模型,基于强化学习的方法和提示工程。
TextCraftor的提出为文本到图像生成领域带来了新的视角。其在图像编辑、视频合成等领域的应用前景广阔,尤其是在需要高质量和与文本高度对齐的图像生成任务中。此外,TextCraftor的控制生成能力也为个性化内容创作提供了新的可能性。
感谢你看到这里,也欢迎点击关注下方公众号,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion、Sora等相关技术,欢迎一起交流学习💗~
这篇关于TextCraftor:一种创新的文本编码器微调技术,无需额外数据集改善图像质量与文本对齐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





