本文主要是介绍吴恩达机器学习笔记 三十四 异常检测算法 开发和评估一个异常检测系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
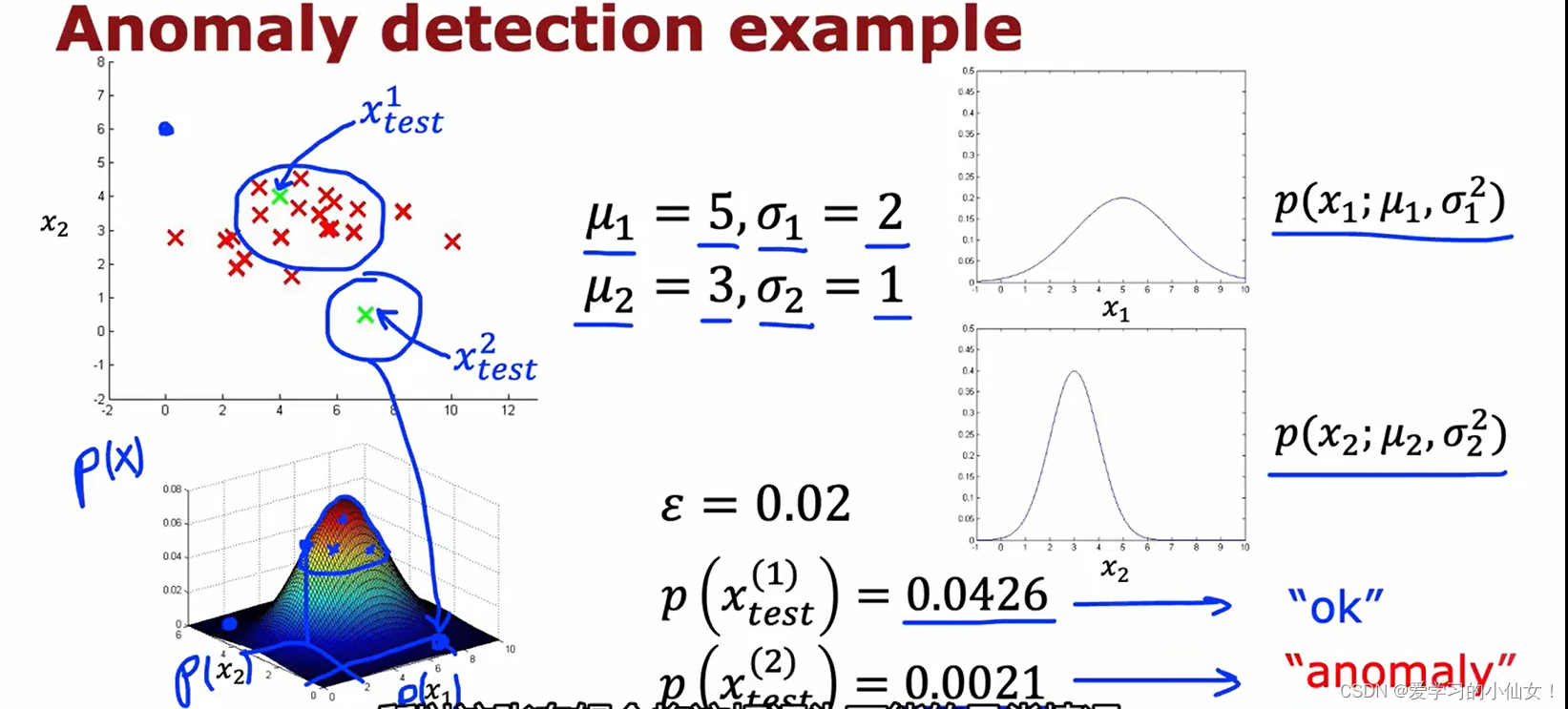
事件发生的概率 p(x) 是各个特征的概率的乘积,因为他们是相互独立的。例如检测飞机发动机是否异常,概率为发动机很热的概率和振动很大的概率乘起来。

异常检测算法具体的步骤如下

举一个例子:
一个有 x1、x2 两个特征的数据集,这两个特征的高斯分布分别如图右边所示,将两个概率乘起来得到左下角的图,越靠近中心的概率越大,越可能是正常的,而边缘的概率更低,更可能是异常数据。
评估一个异常检测算法:
实数评估( real-number evaluating):改变一个特征或者参数可以看出模型是否变得更好或更差 。
假设我们有一些有标签的数据,设 y = 0 为正常, y = 1 为异常,那么假设训练集的所有 y 都为 0 ,即使有几个实际上是 1 也不影响算法工作。如果有很少几个异常的样本,那么创建包含异常样本的交叉验证集和测试集,用交叉验证集调参数,用测试集看结果。

举一个例子:
飞机发动机的检测,假设有10000个正常的样本和20个异常的样本,我们拿6000个正常的样本当做训练集用来训练算法,拿2000个正常的样本和10个异常的样本用来调整算法的参数,剩下的当做测试集。
但是当异常样本的数量非常非常少时,也可以不要测试集,只用训练集和交叉验证集,这种做法的缺点是没办法评估模型在未来的真实数据中的表现。注意,这个过程没有标签,仍是无监督学习。

由于这个数据集的数据非常偏斜(正常样本很多,异常样本很少),可以用之前讲过的精确率、召回率、F1分数这些指标来评估算法。

这篇关于吴恩达机器学习笔记 三十四 异常检测算法 开发和评估一个异常检测系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




