本文主要是介绍基于Scala开发Spark ML的ALS推荐模型实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
推荐系统,广泛应用到电商,营销行业。本文通过Scala,开发Spark ML的ALS算法训练推荐模型,用于电影评分预测推荐。
算法简介
ALS算法是Spark ML中实现协同过滤的矩阵分解方法。
ALS,即交替最小二乘法(Alternating Least Squares),是协同过滤技术中的一种经典算法。它通过对用户和物品的潜在特征进行建模,来预测用户对未知物品的评分或偏好。具体介绍如下:
- 矩阵分解模型:在推荐系统中,我们通常有一个用户-物品的评分矩阵,其中行表示用户,列表示物品,矩阵中的值代表用户对物品的评分。然而,这个矩阵通常是非常稀疏的,因为用户只给少数物品评分。ALS算法就是在这样的不完整评分矩阵上操作,通过矩阵分解来补全缺失值,进而产生推荐。
- 算法原理:ALS算法的核心思想是通过迭代过程更新用户和物品的潜在因子向量。在每次迭代中,一个评分被建模为用户潜在特征向量和物品潜在特征向量的点积,加上一个偏差项。通过最小化实际评分和预测评分之间的差异来不断优化这些潜在特征向量。
- Spark ML实现:在Spark ML库中,ALS算法被用于处理大规模的数据集,并提供了多种参数以适应不同的数据特性和需求。例如,可以设置潜在因子的数量、正则化参数、迭代次数等。此外,Spark ML的ALS还支持隐式反馈数据的变体,这对于无法获取明确评分的数据非常有用。
总的来说,ALS是一种强大的推荐系统算法,尤其适用于处理大规模稀疏数据集。通过合理地选择和调整参数,可以在保持高效计算的同时获得良好的推荐质量。
代码实战
pom.xml文件更新,加入相关依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>sparkGNU2023</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><scala.version>2.13</scala.version><spark.version>3.4.1</spark.version><log4j.version>1.2.17</log4j.version><slf4j.version>1.7.22</slf4j.version></properties><dependencies><!--日志相关依赖--><dependency><groupId>org.slf4j</groupId><artifactId>jcl-over-slf4j</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>com.thoughtworks.paranamer</groupId><artifactId>paranamer</artifactId><version>2.8</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.13</artifactId><version>3.4.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.13</artifactId><version>3.4.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-8_2.11</artifactId><version>2.4.8</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.30</version></dependency><dependency><groupId>org.apache.flume.flume-ng-clients</groupId><artifactId>flume-ng-log4jappender</artifactId><version>1.11.0</version></dependency><!-- flume 拦截器相关依赖--><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version><scope>provided</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.6.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>训练ALS模型
基于scala训练ALS模型
package base.charpter10import breeze.linalg.sum
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
import org.apache.spark.sql.functions.{col, count, explode, when}
import org.apache.spark.sql.{DataFrame, SparkSession}/*** @projectName sparkGNU2023 * @package base.charpter10 * @className base.charpter10.MovieRecommender * @description ${description} * @author pblh123* @date 2024/3/29 15:18* @version 1.0**/object MovieRecommender {def main(args: Array[String]): Unit = {// 创建Spark会话val spark = SparkSession.builder().appName("MovieRecommender").master("local[*]").getOrCreate()import spark.implicits._// 假设我们有一个用户-物品评分数据集,格式为(userId, itemId, rating)/*** UserID,MovieID,Rating,Timestamp* 1,1193,5,978300760* 1,661,3,978302109*/// 指定CSV文件的路径,以及解析选项val csvFilePath = "data/ratings.csv"val csvOptions = Map("header" -> "true", // 是否有列名头"inferSchema" -> "true", // 是否自动推断数据类型"encoding" -> "UTF-8", // 如果有特定的编码格式,例如对于包含中文的CSV文件:)// 读取CSV文件并创建DataFrameval ratingsDF = spark.read.format("csv").options(csvOptions).load(csvFilePath)// 显示DataFrame的前几行以验证数据是否正确加载println("查看原始据数据样例:")ratingsDF.show(5)val ratings: DataFrame = ratingsDF.select("UserID", "MovieID", "Rating").withColumnRenamed("UserID", "userId").withColumnRenamed("MovieID", "itemId").withColumnRenamed("Rating", "rating")// 将数据集分割为训练集和测试集val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))println("查看训练集数据")training.show(5)println("查看测试集数据")test.show(5)// 设置ALS参数// 创建一个ALS实例并配置参数val als = new ALS().setMaxIter(10) // 设置最大迭代次数为5,10,本地测试时,设置过大,会报错.setRegParam(0.01) // 设置正则化参数为0.01.setUserCol("userId") // 设置用户列名为"userId".setItemCol("itemId") // 设置物品列名为"itemId".setRatingCol("rating") // 设置评分列名为"rating"/*** ALS(Alternating Least Squares)是一种基于矩阵分解的协同过滤算法,用于处理用户和物品之间的评分数据。各参数说明如下:* setMaxIter: 设置最大迭代次数,决定模型训练的精细程度。迭代次数越多,模型通常越精确,但训练时间也可能更长。* setRegParam: 设置正则化参数,用于控制模型的复杂度和过拟合程度。较小的正则化参数值可能导致模型过复杂,容易过拟合;较大的值则可能导致模型过于简单,欠拟合。* setUserCol, setItemCol, setRatingCol: 分别设置用户ID列、物品ID列和评分列的名称。这些列名根据实际的数据结构来确定,用于告诉ALS算法在哪些列中查找用户、物品和评分信息。*/// 训练ALS模型println("开始训练模型")val model = als.fit(training)// 对测试集进行预测val predictions = model.transform(test)predictions.show()predictions.filter($"rating".isNotNull && $"prediction".isNotNull).count() // 确认有非空的评分和预测值// 评估模型val evaluator = new RegressionEvaluator().setMetricName("rmse").setLabelCol("rating").setPredictionCol("prediction")val rmse = evaluator.evaluate(predictions)println(s"Root-mean-square error = $rmse")// 为用户生成推荐// 该函数是基于一个模型(model)为所有用户推荐项目的函数。它将为每个用户推荐5个项目/*** +------+--------------------------------------------------------------------------------------------+* |userId|recommendations[{itemid,pred_rating},{itemid,pred_rating},...] |* +------+--------------------------------------------------------------------------------------------+* |12 |[{1864, 9.721167}, {2964, 8.815781}, {3867, 8.480173}, {1539, 7.8904114}, {563, 7.8829007}] |* |22 |[{2964, 6.090676}, {3215, 5.6165895}, {1534, 5.4731245}, {718, 5.462125}, {2632, 5.4482727}]|*/val userRecs = model.recommendForAllUsers(5)userRecs.show(5,false)println("保存预测结果")
// userRecs.write.mode("overwrite").parquet("models/recomALSmodel") // 保存为parquet格式,一般用于集群中
// userRecs是一个DataFrame,其中"recommendations"列是数组类型val explodedUserRecs = userRecs.withColumn("recommendations", explode($"recommendations")).select($"userId", $"recommendations.itemId".as("itemId"), $"recommendations.rating".as("PredRating"))explodedUserRecs.write.mode("overwrite").format("csv").save("predictRes/recomALS") // PC 调试使用// 保存模型到指定路径val modelPath = "models/recomALSmodel"model.write.overwrite().save(modelPath)println(s"Model saved to $modelPath")// 停止Spark会话spark.stop()/*当程序试图停止Spark会话时,可能会触发清理临时文件的操作,从而导致出现NoSuchFileException异常。通常情况下,这不是代码逻辑的问题,而是Spark内部在清理资源时可能出现的问题。可以尝试重启Spark环境或者适当增大Spark的临时目录空间来避免此类问题。*/}}
运行代码,效果图如下
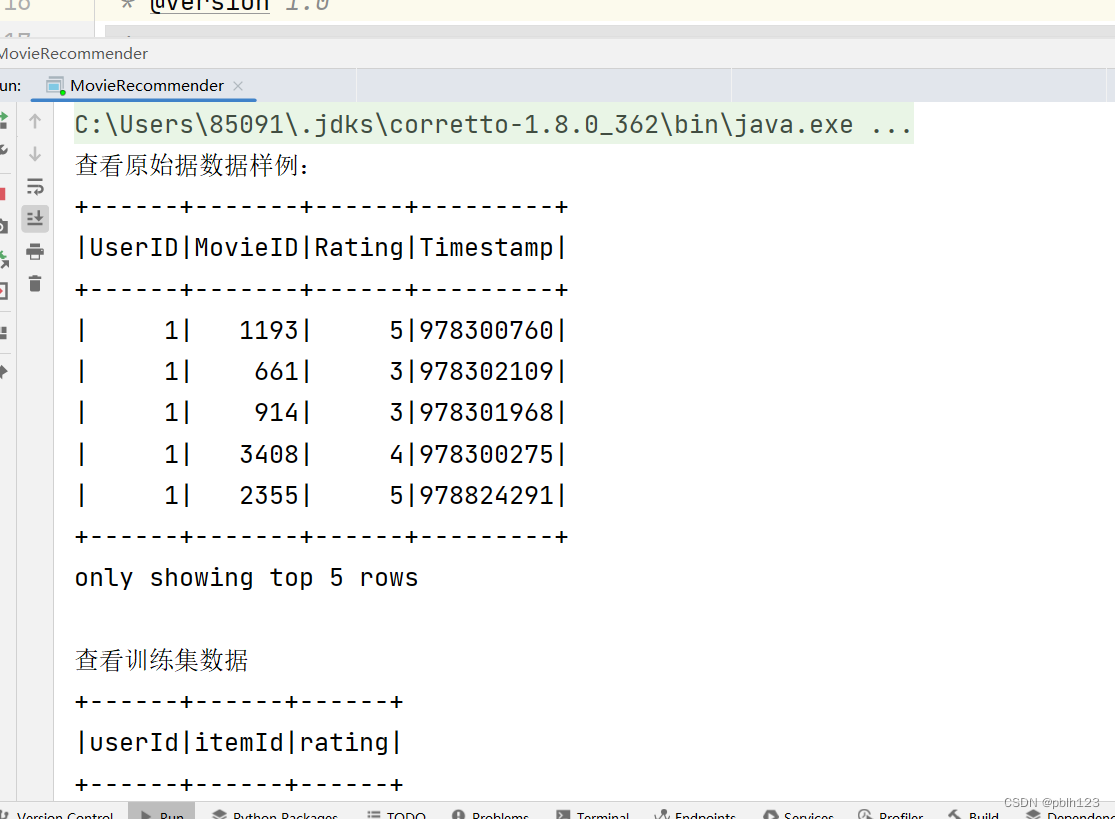

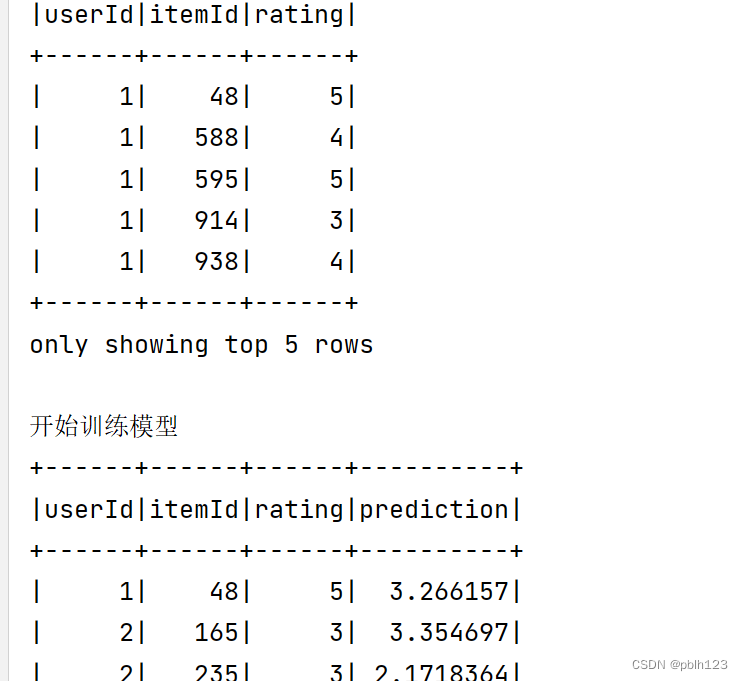
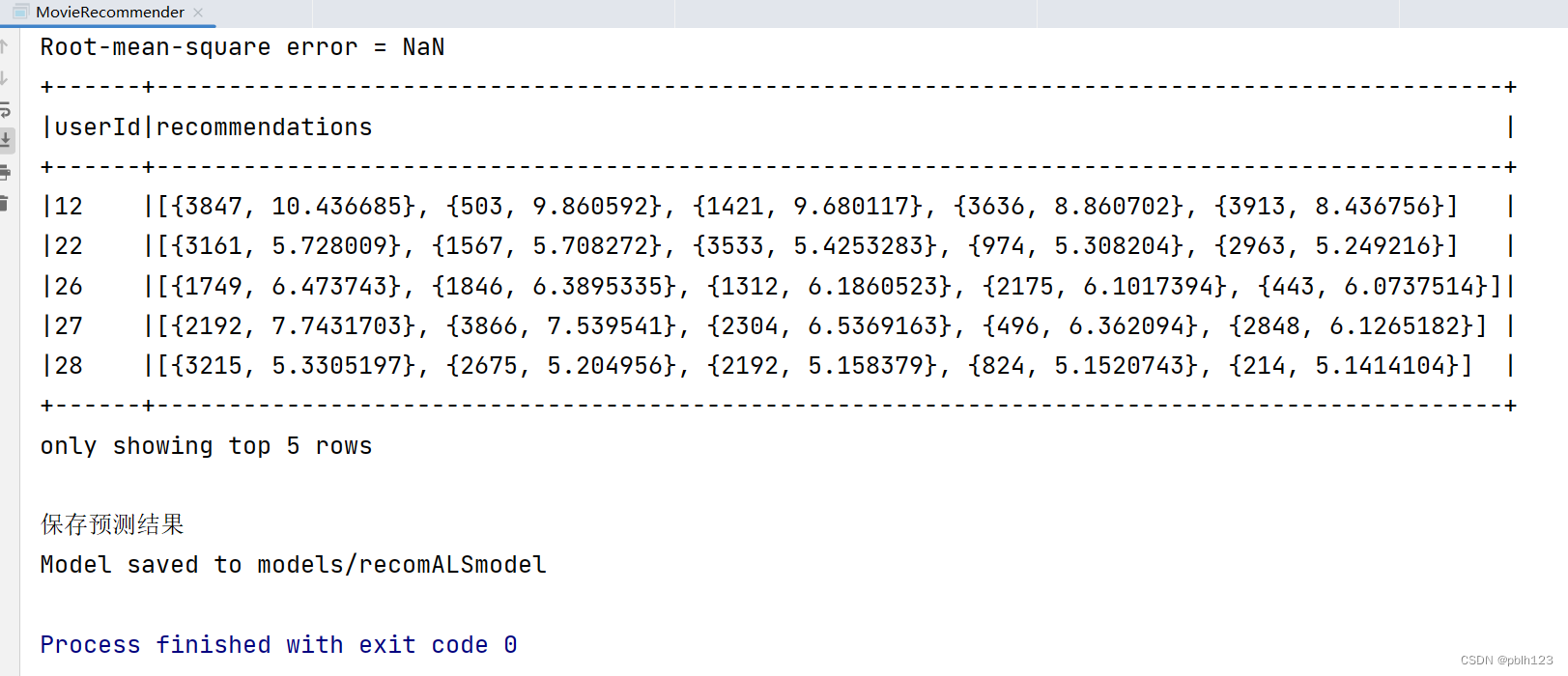
TodoList:目前RMSE计算出问题,原数据清洗没有做,模型参数还可以调整。后期调整更新后,再发一篇文章。
使用训练的模型预测新数据
scala开发应用模型demo代码
package base.charpter10import org.apache.spark.ml.recommendation.ALSModel
import org.apache.spark.sql.SparkSession/*** @projectName sparkGNU2023 * @package base.charpter10 * @className base.charpter10.RecommendationModelLoadDemo * @description ${description} * @author pblh123* @date 2024/3/29 15:36* @version 1.0**/object RecommendationModelLoadDemo {def main(args: Array[String]): Unit = {// 创建Spark会话val spark = SparkSession.builder().master("local[*]").appName("RecommendationModelUsageDemo").getOrCreate()import spark.implicits._// 加载之前保存的ALS模型val modelPath = "models/recomALSmodel"val loadedModel: ALSModel = ALSModel.load(modelPath)// 假设我们有一些新的用户-物品对,我们想要预测它们的评分val userItemPairs = Seq((1, 4), // 用户1对物品4的评分预测(2, 2) // 用户2对物品2的评分预测).toDF("userId", "itemId")// 使用模型进行评分预测val predictions = loadedModel.transform(userItemPairs)predictions.show()// 现在,假设我们想要为用户1生成前N个推荐物品val numRecommendations = 5 // 为用户推荐的物品数量val userRecs = loadedModel.recommendForAllUsers(numRecommendations)userRecs.show(5,false)// 停止Spark会话spark.stop()}}
运行效果如下
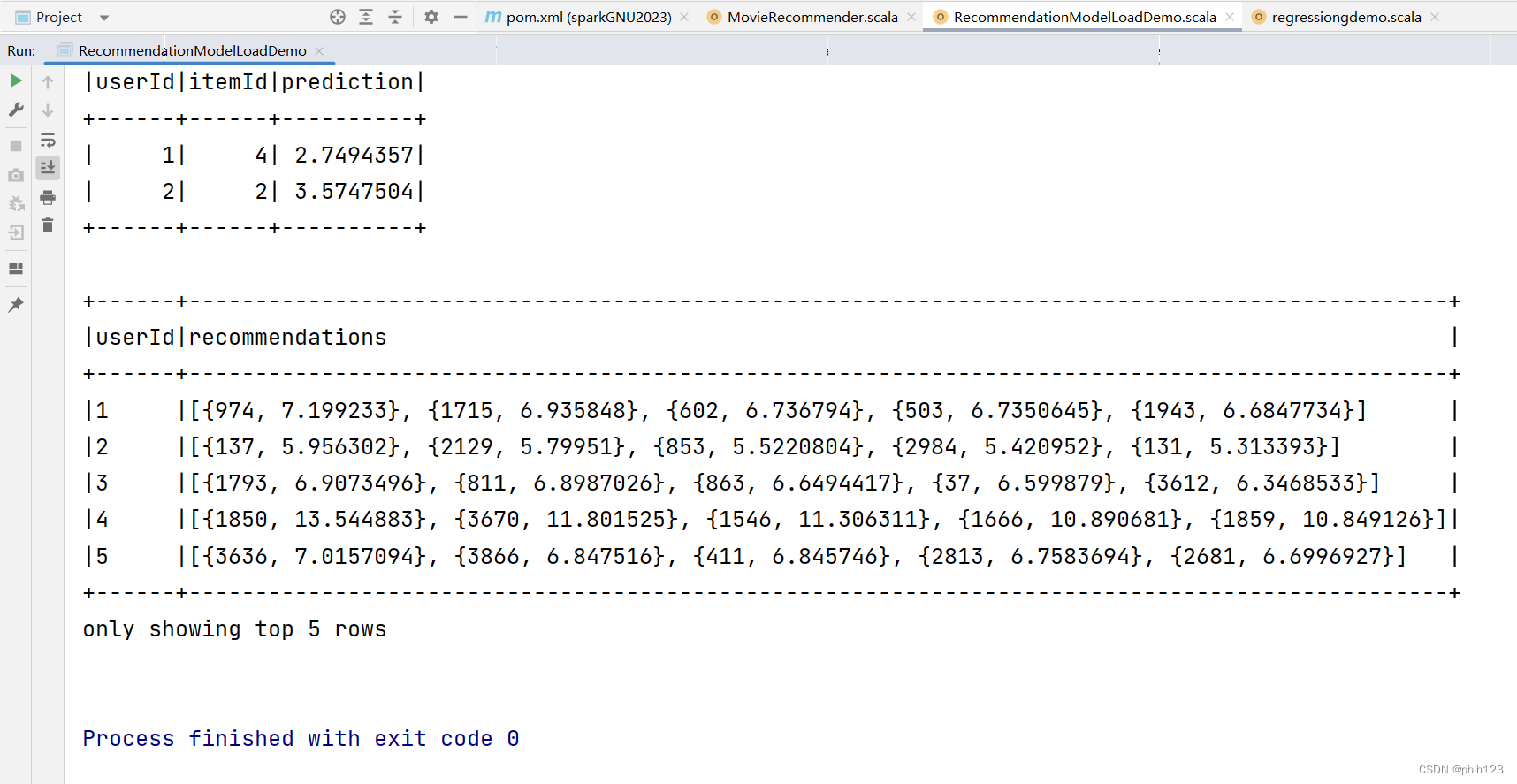
评估效果说明:目前的预测评分不合理,是因为模型没有经过精挑,优化,预测的记过会依据预测评分高低排序,选取得分高的前5个结果返回。后期模型调优后,结果就正常了。
这篇关于基于Scala开发Spark ML的ALS推荐模型实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









