本文主要是介绍YOLOV8逐步分解(3)_trainer训练之模型加载,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
yolov8逐步分解(1)--默认参数&超参配置文件加载
yolov8逐步分解(2)_DetectionTrainer类初始化过程
接上2篇文章,继续讲解yolov8训练过程中的模型加载过程。
使用默认参数完成训练器trainer的初始化后,执行训练函数train()开始YOLOV8的训练。

1. train()方法实现代码如下所示:
def train(self):"""Allow device='', device=None on Multi-GPU systems to default to device=0."""#判断设置使用设备总数if isinstance(self.args.device, int) or self.args.device: # i.e.device=0 or device=[0,1,2,3]world_size = torch.cuda.device_count() #计算当前可用设备数elif torch.cuda.is_available(): # i.e. device=None or device=''#判断cuda是否可用world_size = 1 # default to device 0else: # i.e. device='cpu' or 'mps'world_size = 0# Run subprocess if DDP training, else train normally 分布式训练#分布式训练if world_size > 1 and 'LOCAL_RANK' not in os.environ:# Argument checksif self.args.rect:LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with Multi-GPU training, setting rect=False")self.args.rect = False# Commandcmd, file = generate_ddp_command(world_size, self)try:LOGGER.info(f'DDP command: {cmd}')subprocess.run(cmd, check=True)except Exception as e:raise efinally:ddp_cleanup(self, str(file))else:self._do_train(world_size)上述代码中,主要实现一个功能:判断本次训练使用的机器的个数即world_size的值。world_size 可用于配置分布式训练系统,确保所有设备都能够正确地参与到训练过程中。详细解释请参考博客yolo中RANK、LOACL_RANK以及WORLD_SIZE的介绍-CSDN博客。
若world_size > 1,则进行分布式训练,本次训练使用的机器为单机单卡,所以world_size = 1,不支持分布式训练。直接进入单机训练函数self._do_train(world_size)。
2. _do_train()函数实现代码(部分)截图如下:
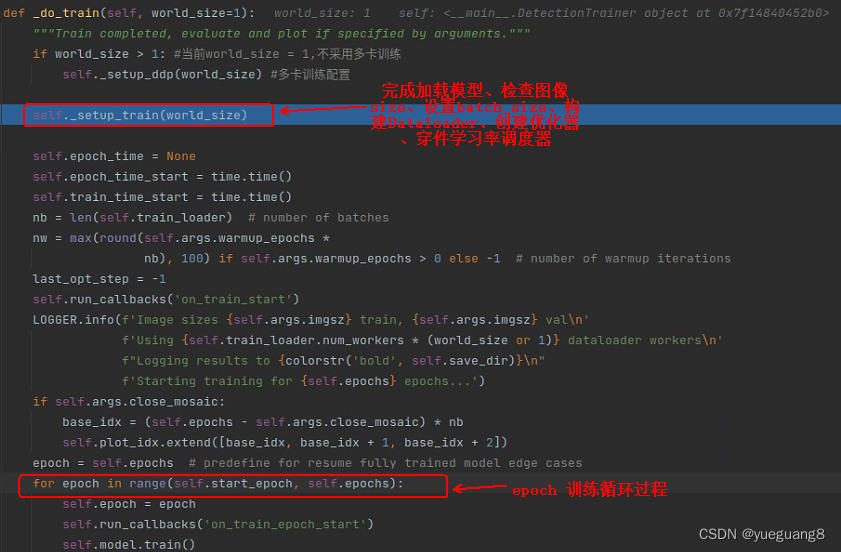
下面将逐步讲解_setup_train()函数的功能.
3. _setup_train()代码实现如下
def _setup_train(self, world_size):"""Builds dataloaders and optimizer on correct rank process. #构建数据加载器和优化器"""# Modelself.run_callbacks('on_pretrain_routine_start')ckpt = self.setup_model()#加载模型self.model = self.model.to(self.device)self.set_model_attributes()# Check AMPself.amp = torch.tensor(self.args.amp).to(self.device) # True or Falseif self.amp and RANK in (-1, 0): # Single-GPU and DDP callbacks_backup = callbacks.default_callbacks.copy() # backup callbacks as check_amp() resets them,self.amp = torch.tensor(check_amp(self.model), device=self.device) callbacks.default_callbacks = callbacks_backup # restore callbacks, if RANK > -1 and world_size > 1: dist.broadcast(self.amp, src=0) # broadcast the tensor from rank 0 to all other ranks (returns None)self.amp = bool(self.amp) # as booleanself.scaler = amp.GradScaler(enabled=self.amp) if world_size > 1:self.model = DDP(self.model, device_ids=[RANK])# Check imgszgs = max(int(self.model.stride.max() if hasattr(self.model, 'stride') else 32), 32) # grid size (max stride)self.args.imgsz = check_imgsz(self.args.imgsz, stride=gs, floor=gs, max_dim=1)# Batch sizeif self.batch_size == -1: #表示批量大小需要自动估计if RANK == -1: # single-GPU only, estimate best batch sizeself.args.batch = self.batch_size = check_train_batch_size(self.model, self.args.imgsz, self.amp)#估计最佳批量大小else:SyntaxError('batch=-1 to use AutoBatch is only available in Single-GPU training. ''Please pass a valid batch size value for Multi-GPU DDP training, i.e. batch=16')# Dataloadersbatch_size = self.batch_size // max(world_size, 1)self.train_loader = self.get_dataloader(self.trainset, batch_size=batch_size, rank=RANK, mode='train')#获取训练集if RANK in (-1, 0):self.test_loader = self.get_dataloader(self.testset, batch_size=batch_size * 2, rank=-1, mode='val') #获取测试集self.validator = self.get_validator() #创建验证器(validator),用于评估模型在验证数据集上的性能。metric_keys = self.validator.metrics.keys + self.label_loss_items(prefix='val')self.metrics = dict(zip(metric_keys, [0] * len(metric_keys))) # TODO: init metrics for plot_results()?self.ema = ModelEMA(self.model)if self.args.plots and not self.args.v5loader: #如果 self.args.plots 为真且 self.args.v5loader 为假self.plot_training_labels() #绘制训练标签的图表# Optimizerself.accumulate = max(round(self.args.nbs / self.batch_size), 1) # accumulate loss before optimizingweight_decay = self.args.weight_decay * self.batch_size * self.accumulate / self.args.nbs # scale weight_decayiterations = math.ceil(len(self.train_loader.dataset) / max(self.batch_size, self.args.nbs)) * self.epochsself.optimizer = self.build_optimizer(model=self.model,name=self.args.optimizer,lr=self.args.lr0,momentum=self.args.momentum,decay=weight_decay,iterations=iterations)# Schedulerif self.args.cos_lr:self.lf = one_cycle(1, self.args.lrf, self.epochs) # cosine 1->hyp['lrf']else:self.lf = lambda x: (1 - x / self.epochs) * (1.0 - self.args.lrf) + self.args.lrf # linearself.scheduler = optim.lr_scheduler.LambdaLR(self.optimizer, lr_lambda=self.lf)self.stopper, self.stop = EarlyStopping(patience=self.args.patience), Falseself.resume_training(ckpt) #恢复训练过程。ckpt 是一个检查点文件,用于加载之前保存的模型和训练状态。self.scheduler.last_epoch = self.start_epoch - 1 # do not moveself.run_callbacks('on_pretrain_routine_end') #运行预训练过程结束时的回调函数。4.1 模型加载配置
# Model
self.run_callbacks('on_pretrain_routine_start')
ckpt = self.setup_model()#加载模型
self.model = self.model.to(self.device)
self.set_model_attributes()这段代码是在训练过程中对模型进行加载和设置。
首先,通过 self.run_callbacks('on_pretrain_routine_start') 调用了一个名为 'on_pretrain_routine_start' 的回调函数。这可能是在训练过程中的某个特定时间点执行的回调。
然后,通过 self.setup_model() 加载模型,并将返回的模型断点(checkpoint)保存在变量 ckpt 中。
接下来,通过 self.model = self.model.to(self.device) 将模型移动到指定的设备(self.device)上。
最后,调用 self.set_model_attributes() 来设置模型的属性。这可能是根据特定需求对模型进行自定义设置的函数。
4.1.1 模型加载函数setup_model()详解
def setup_model(self):"""load/create/download model for any task."""#判断是否是module模块,如果是直接退出if isinstance(self.model, torch.nn.Module): # if model is loaded beforehand. No setup neededreturnmodel, weights = self.model, Noneckpt = Noneif str(model).endswith('.pt'): #判断是否是pt格式weights, ckpt = attempt_load_one_weight(model) #加载模型cfg = ckpt['model'].yamlelse:cfg = modelself.model = self.get_model(cfg=cfg, weights=weights, verbose=RANK == -1) # calls Model(cfg, weights)return ckptsetup_model()用于加载、创建或下载任务的模型。 以下是该方法的逐条详细说明:
它首先检查 self.model 属性是否已经是 torch.nn.Module 的实例,若是,表明模型已经预先加载。 在这种情况下,该方法只是返回而不进行任何进一步的设置。
如果模型尚未加载,它将继续检查模型文件的格式。 如果模型文件为.pt格式,则调用attempt_load_one_weight函数加载模型权重和检查点。 加载权重和检查点后,它从检查点中提取模型配置。
如果模型文件不是 .pt 格式,则假定模型变量直接保存模型配置。
然后,它使用提取或提供的模型配置 (cfg) 和加载的权重 (weights) 调用 get_model 方法来创建模型的实例。
最后,它将创建的模型实例分配给 self.model 属性并返回加载的检查点(ckpt)。
4.1.1.1 模型加载函数attempt_load_one_weight()详解
def attempt_load_one_weight(weight, device=None, inplace=True, fuse=False):"""Loads a single model weights."""ckpt, weight = torch_safe_load(weight) args = {**DEFAULT_CFG_DICT, **(ckpt.get('train_args', {}))} model = (ckpt.get('ema') or ckpt['model']).to(device).float() model.args = {k: v for k, v in args.items() if k in DEFAULT_CFG_KEYS} model.pt_path = weight # attach *.pt file path to model, 值为'yolov8n.pt'model.task = guess_model_task(model) # 'detect'if not hasattr(model, 'stride'): #如果没有该属性,则添加一个model.stride = torch.tensor([32.])model = model.fuse().eval() if fuse and hasattr(model, 'fuse') else model.eval() # model.eval(): 将模型设置为评估模式# Module compatibility updatesfor m in model.modules():t = type(m)if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Segment):m.inplace = inplace elif t is nn.Upsample and not hasattr(m, 'recompute_scale_factor'):m.recompute_scale_factor = None # torch 1.11.0 compatibility # Return model and ckptreturn model, ckpt上述代码定义了一个名为 attempt_load_one_weight 的函数,功能如下:
函数参数 weight 表示模型权重的路径或文件,device 表示设备(默认为 None),inplace 表示是否原地操作(默认为 True),fuse 表示是否进行融合操作(默认为 False)。
a. 函数首先调用 torch_safe_load 函数来加载权重,并将返回的结果赋值给 ckpt 和 weight 变量。torch_safe_load 函数内部功能为:判断yolov8*.pt文件是否存在,不存在从github下载,最后通过torch.load加载模型。其中weight类型为字符串,值为’yolov8.pt’ , ckpt 类型为字典,内部为模型结构以及 训练时保存的参数,内容如下: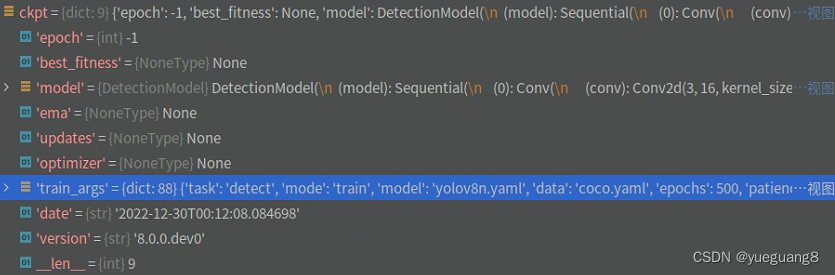
b. 根据加载的权重,将默认配置字典 DEFAULT_CFG_DICT 和 ckpt 字典中的 'train_args' 键对应的值进行合并,得到 args 字典。键值相同,以后面字典的键值为最终结果。 ckpt字典的内容(后半段数据)如下:
c. 将 ckpt 字典中的 'ema' 键对应的值或者 'model' 键对应的值赋给 model 变量,并将其转移到指定的设备上(默认为 device 参数指定的设备),然后将其转换为浮点型。
d. 将 args 字典中的键值对赋值给 model.args 属性,但仅保留键在 DEFAULT_CFG_KEYS 列表中的键值对。
e. 将 weight 的值赋给 model.pt_path 属性,将模型文件的路径附加到模型中。值为model.pt_path = ‘yolov8.pt’
f .推测模型的任务类型,并将结果赋给 model.task 属性。本次该值为‘detect’.
g. 如果模型中没有名为 stride 的属性,则添加一个名为 stride 的属性,其值为 torch.tensor([32.])。
h. 如果 fuse 为 True 并且模型具有 fuse 属性,则对模型进行融合操作,并将模型设置为评估模式。 此处设置为eval模式,是因为下面要对网络的一些值进行更换,必须进入该模式。后面开始训练时会重新将model设置回训练模式
i. 对于模型中的每个模块,根据模块的类型进行相应的操作:
如果模块的类型是 nn.Hardswish、nn.LeakyReLU、nn.ReLU、nn.ReLU6、nn.SiLU、Detect 或 Segment,则设置 m.inplace 属性为 inplace 参数的值。
如果模块的类型是 nn.Upsample 并且模块不存在 recompute_scale_factor 属性,则将其设置为 None,以保持与 Torch 1.11.0 的兼容性。
j. 返回经过以上处理的模型实例和加载的检查点,即 model 和 ckpt。
4.1.1.2 提取模型配置
cfg = ckpt['model'].yamlcfg类型为字典,内部存放为模型配置参数,即yolov8.yaml中的内容,使用的为YOLOV8n,内容如下图所示:

工程中yolov8.yaml文件位置及内容如下:

4.1.1.3 获取目标检测模型
self.model = self.get_model(cfg=cfg, weights=weights, verbose=RANK == -1) # calls Model(cfg, weights)get_model实现代码如下:
def get_model(self, cfg=None, weights=None, verbose=True):"""Return a YOLO detection model."""model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)if weights:model.load(weights)return model该方法用于返回一个 YOLO 检测模型。
方法的参数包括:
self:表示类的实例对象,即调用该方法的对象本身。
cfg:表示模型的配置参数(默认为 None)。
weights:表示模型的权重文件路径(默认为 None)。
verbose:表示是否显示详细信息(默认为 True)。
a. 创建一个 DetectionModel 实例,并传入 cfg 参数和 nc 参数(self.data['nc'])作为构造函数的参数。verbose 参数的值为 verbose and RANK == -1,其中 RANK 是全局变量,用于判断是否为主进程(多进程环境中的一个标识)。
b. 如果 weights 参数不为 None,则调用 model.load(weights) 方法加载权重文件。
c. 返回创建的 model 对象。
至此模型加载完成。
下一章节将详细介绍yolov8检测模型DetectionModel()的实例化过程,内部包含模型的解析构造过程。
这篇关于YOLOV8逐步分解(3)_trainer训练之模型加载的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






