本文主要是介绍YOLOv5改进系列:升级版ResNet的新主干网络DenseNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、论文理论

论文地址:Densely Connected Convolutional Networks
1.理论思想
DenseNet最大化前后层信息交流,通过建立前面所有层与后面层的密集连接,实现了特征在通道维度上的复用,不但减缓了梯度消失的现象,也使其可以在参数与计算量更少的情况下实现比ResNet更优的性能。
2.创新点
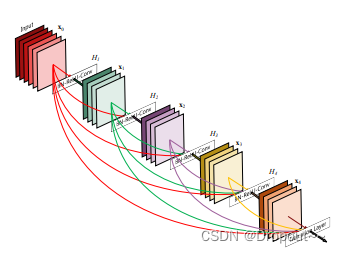
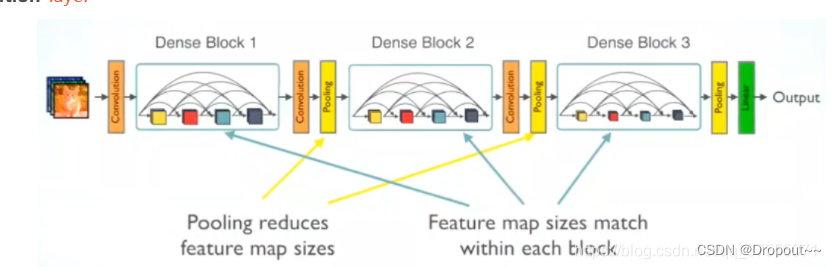
操作过程:
- 每一个Bottleneck输出的特征通道数是相同的,例如这里的K=32。同时可以看到,经过concat操作后的通道数是按K的增长量增加的,因此这个K也被称为GrowthRate。
- 这里1×1卷积的作用是固定输出通道数,达到降维的作用,1×1卷积输出的通道数通常是GrowthRate的4倍。当几十个Bottleneck相连接时,concat后的通道数会增加到上千,如果不增加1×1的卷积来降维,后续3×3卷积所需的参数量会急剧增加。比如,输入通道数64,增长率K=32,经过15个Bottleneck,通道数输出为64+15*32=544,再经过第16个Bottleneck时,如果不使用1×1卷积,第16个Bottleneck层参数量是3*3*544*32=156672,如果使用1×1卷积,第16个Bottleneck层参数量是1*1*544*128+3*3*128*32=106496,可以看到参数量大大降低。
- Dense Block采用了激活函数在前、卷积层在后的顺序,即BN-ReLU-Conv的顺序,这种方式也被称为pre-activation。通常的模型relu等激活函数处于卷积conv、批归一化batchnorm之后,即Conv-BN-ReLU,也被称为post-activation。作者证明,如果采用post-activation设计,性能会变差。想要更清晰的了解pre-activition,可以参考我的博客ResNet残差网络及变体详解中的Pre Activation ResNet。
二、代码部署
1.代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from torch.jit.annotations import Listfrom timm.models.layers import BatchNormAct2ddef autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolution iscyydef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class DenseLayer(nn.Module):def __init__(self, int_numss, gr, bs, norm_layer=BatchNormAct2d,drop_rate=0., memory_efficient=False):super(DenseLayer, self).__init__()self.add_module('norm1', norm_layer(int_numss)),self.add_module('conv1', nn.Conv2d(int_numss, bs * gr, kernel_size=1, stride=1, bias=False)),self.add_module('norm2', norm_layer(bs * gr)),self.add_module('conv2', nn.Conv2d(bs * gr, gr, kernel_size=3, stride=1, padding=1, bias=False)),self.drop_rate = float(drop_rate)self.memory_efficient = memory_efficientdef bottleneck_fn(self, xs):concated_features = torch.cat(xs, 1)bottleneck_output = self.conv1(self.norm1(concated_features)) # noqa: T484return bottleneck_outputdef any_requires_grad(self, x):for tensor in x:if tensor.requires_grad:return Truereturn False@torch.jit.unused # noqa: T484def call_checkpoint_bottleneck(self, x):def closure(*xs):return self.bottleneck_fn(xs)return cp.checkpoint(closure, *x)@torch.jit._overload_method # mango noqa: F811def forward(self, x):pass@torch.jit._overload_method # noqa: F811def forward(self, x):passdef forward(self, x): # noqa: F811 iscyy/mangoif isinstance(x, torch.Tensor):prev_features = [x]else:prev_features = xif self.memory_efficient and self.any_requires_grad(prev_features):if torch.jit.is_scripting():raise Exception("Memory Efficient not supported in JIT")bottleneck_output = self.call_checkpoint_bottleneck(prev_features)else:bottleneck_output = self.bottleneck_fn(prev_features)new_features = self.conv2(self.norm2(bottleneck_output))if self.drop_rate > 0:new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)return new_featuresclass DenseBlock(nn.ModuleDict):_version = 2def __init__(self, int_numss, gr, num_layers, bs=4, norm_layer=nn.ReLU,drop_rate=0., memory_efficient=False):super(DenseBlock, self).__init__()for i in range(num_layers):layer = DenseLayer(int_numss + i * gr,gr=gr,bs=bs,norm_layer=norm_layer,drop_rate=drop_rate,memory_efficient=memory_efficient,)self.add_module('denselayer%d' % (i + 1), layer)def forward(self, init_features):features = [init_features]for name, layer in self.items():new_features = layer(features)features.append(new_features)return torch.cat(features, 1)class DenseTrans(nn.Sequential):def __init__(self, int_numss, out_numss, kernel_size, norm_layer=nn.BatchNorm2d, aa_layer=None, act=True):super(DenseTrans, self).__init__()self.conv = nn.Conv2d(int_numss, out_numss, kernel_size=kernel_size, stride=1)self.bn = nn.BatchNorm2d(out_numss)self.act = self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class DenseB(nn.Module):def __init__(self, c1, c2, gr, num_layers=6):super().__init__()self.dense = DenseBlock(c1, gr, num_layers)self.con = DenseTrans(c1 + gr * num_layers, c2, 1 ,1)def forward(self, x):x = self.con(self.dense(x))return xclass DenseC(nn.Module):def __init__(self, c1, c2, gr, num_layers=6):super().__init__()self.dense = DenseBlock(c1, gr, num_layers)self.con = DenseTrans(c1 + gr * num_layers, c2, 1 ,1)self.dense2 = DenseBlock(c1, gr, num_layers)self.con2 = DenseTrans(c1 + gr * num_layers, c2, 1 ,1)def forward(self, x):x = self.con(self.dense(x))x = self.con2(self.dense2(x))return xclass DenseOne(nn.Module):def __init__(self, c1, c2, n=1, gr=32, e=0.5):super().__init__()c_ = int(c2 * e)self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1)self.m = nn.Sequential(*(DenseB(c_, c_, gr=gr, num_layers=6) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))class DenseOneC(nn.Module):def __init__(self, c1, c2, n=1, gr=32, e=0.5):super().__init__()c_ = int(c2 * e)self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1)self.m = nn.Sequential(*(DenseC(c_, c_, gr=gr, num_layers=6) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))2.配置教程
(1)在models/cmmon.py中添加上述代码,将与初始代码中重复类删除
(2)在./models/yolo.py文件下里的parse_model函数,将类名加入进去
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部
elif m in [DenseOne, DenseOneC]:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in [DenseOne, DenseOneC]:args.insert(2, n) # number of repeatsn = 13.yaml文件
YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.5 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone by mango
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, DenseOne, [1024, 32]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head by mango
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, DenseOne, [1024]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
三、总结
本文主要工作包括DenseNet介绍及改进代码策略,该模块为即插即用模块,部署位置可根据实际针对任务需求,自行调整
本专栏持续更新中,订阅本栏,关注更新~
这篇关于YOLOv5改进系列:升级版ResNet的新主干网络DenseNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







