本文主要是介绍使用Python实现ID3决策树中特征选择的先后顺序,字节跳动面试真题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
def empty1(pri_data):
hair = [] #[‘长’, ‘短’, ‘短’, ‘长’, ‘短’, ‘短’, ‘长’, ‘长’]
voice = [] #[‘粗’, ‘粗’, ‘粗’, ‘细’, ‘细’, ‘粗’, ‘粗’, ‘粗’]
sex = [] #[‘男’, ‘男’, ‘男’, ‘女’, ‘女’, ‘女’, ‘女’, ‘女’]
for one in pri_data:
hair.append(one[0])
voice.append(one[1])
sex.append(one[2])
cu_voive = voice.count(‘粗’) #6
thin_voice = voice.count(‘细’) #2
一维列表合并成多维列表
d = []
for i in range(len(hair)):
for j in range(len(voice)):
if i == j:
for k in range(len(sex)):
if j == k:
t = [hair[i], voice[j], sex[k]]
d.append(t)
print(d)
a = d.count([‘短’, ‘粗’, ‘男’]) #2
b = d.count([‘短’, ‘粗’, ‘女’]) #1
c = d.count([‘长’, ‘粗’, ‘男’]) #1
e = d.count([‘长’, ‘粗’, ‘女’]) #2
f = d.count([‘长’, ‘细’, ‘女’]) #1
g = d.count([‘短’, ‘细’, ‘女’]) #1
#一维列表合并成二维列表
z=list(zip(voice,sex))
cu_woman =z.count((‘粗’,‘女’))
cu_man = z.count((‘粗’,‘男’))
num_v_h = (cu_woman + cu_man)
return cu_voive, thin_voice, cu_woman, cu_man, num_v_h
def empty2(pri_data):
hair = [] # [‘长’, ‘短’, ‘短’, ‘长’, ‘短’, ‘短’, ‘长’, ‘长’]
voice = [] # [‘粗’, ‘粗’, ‘粗’, ‘细’, ‘细’, ‘粗’, ‘粗’, ‘粗’]
sex = [] # [‘男’, ‘男’, ‘男’, ‘女’, ‘女’, ‘女’, ‘女’, ‘女’]
for one in pri_data:
hair.append(one[0])
voice.append(one[1])
sex.append(one[2])
一维列表合并成二维列表
k = list(zip(hair, sex))
long_man =k.count((‘长’,‘男’))
long_woman = k.count((‘长’,‘女’))
sum_hair1 = long_man + long_woman
short_man = k.count((‘短’,‘男’))
short_woman = k.count((‘短’,‘女’))
sum_hair2 = short_man + short_woman
sum_Hair = sum_hair1 + sum_hair2
return long_man, long_woman, sum_hair1,sum_hair2,sum_Hair,short_man,short_woman
用声音作为优先选择特征求信息增益
def xxx1(cu_voice,thin_voice,cu_woman,cu_man,num_v_h):
voice_num=cu_voice+thin_voice
A = -cu_voive/voice_num * (cu_woman/num_v_h) * np.log2(cu_woman/num_v_h) - \
cu_voive/voice_num * (cu_man/num_v_h) * np.log2(cu_man/num_v_h)
sum_v = getData(pri_data) - A
return sum_v
用头发作为优先选择特征求信息增益
def xxx2(long_man, long_woman, sum_hair,sum_hair2,sum_Hair,short_man,short_woman):
B = -sum_hair/sum_Hair* (long_man/sum_hair) * np.log2(long_man/sum_hair) - \
sum_hair/sum_Hair * (long_woman/sum_hair) * np.log2(long_woman/sum_hair) - sum_hair2/sum_Hair * (short_man/sum_hair2) * np.log2(short_man/sum_hair2)\
- sum_hair2/sum_Hair* (short_woman/sum_hair2) * np.log2(short_woman/sum_hair2)
sum_h = getData(pri_data) - B
return sum_h
if name == “main”:
pri_data = [[‘长’, ‘粗’, ‘男’], [‘短’, ‘粗’, ‘男’], [‘短’, ‘粗’, ‘男’],
[‘长’, ‘细’, ‘女’], [‘短’, ‘细’, ‘女’], [‘短’, ‘粗’, ‘女’],
[‘长’, ‘粗’, ‘女’], [‘长’, ‘粗’, ‘女’]]
total_shang=getData(pri_data)
cu_voive, thin_voice, cu_woman, cu_man, num_v_h=empty1(pri_data)
sum1 = xxx1(cu_voive, thin_voice, cu_woman, cu_man, num_v_h)
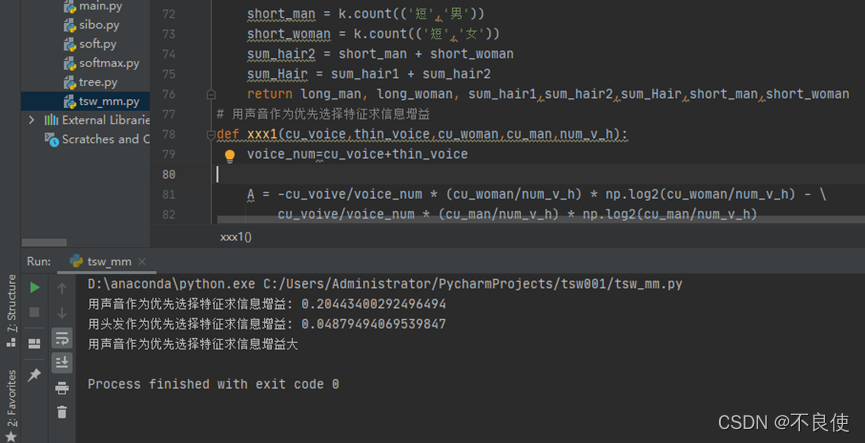
print(‘用声音作为优先选择特征求信息增益:’,sum1)
long_man, long_woman, sum_hair1, sum_hair2, sum_Hair, short_man, short_woman=empty2(pri_data)
sum2 = xxx2(long_man, long_woman, sum_hair1, sum_hair2, sum_Hair, short_man, short_woman)
print(‘用头发作为优先选择特征求信息增益:’,sum2)
if sum1 > sum2:
print(“用声音作为优先选择特征求信息增益大”)
else:
print(“用头发作为优先选择特征求信息增益大”)
截图:
四、实验内容
(1)案例描述:通过天气、温度、湿度、是否有风4个特征来决策是否打球。使用Python实现求出其信息增益,并得出哪个特征优先被选择(注:数据处理使用程序计算,数据见data.xls)。
数据集如下: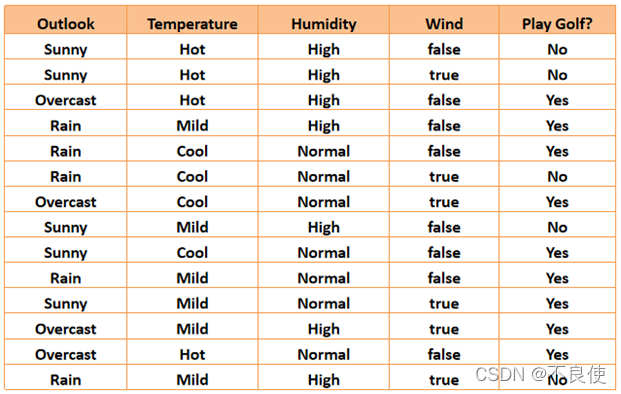
代码:
import xlrd
import numpy as np
workbook=xlrd.open_workbook(“data.xls”)
sheet=workbook.sheet_by_name(“Sheet1”)
row_count=sheet.nrows
col_count=sheet.ncols
data_list=[]
for i in range(1,row_count):
data_list.append(sheet.row_values(i))
play_golf_number=0
no_play_golf_number=0
total_count=0
for i in data_list:
if i[col_count-1]==“Yes”:
play_golf_number+=1
else:
no_play_golf_number+=1
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
c8abf2f2f4b1af.png)
(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。
这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
这篇关于使用Python实现ID3决策树中特征选择的先后顺序,字节跳动面试真题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





