本文主要是介绍[InternLM训练营第二期笔记]1. 书生·浦语大模型全链路开源开放体系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于想学习一下LLM相关的知识,真好看到上海AI Lab举行的InternLM训练营,可以提高对于LLM的动手能力。
每次课堂都要求笔记,因此我就想在我的CSDN上更新一下,希望和感兴趣的同学共同学习~
本次笔记是第一节课,介绍课。
课程视频:Bilibili
InternLM2 Technical report: arxiv
1. 书生·浦语大模型全链路开放体系
1.1 介绍
当前,人工智能的发展趋势是从专用模型到通用模型迈进。专用模型往往是解决一个特定的问题,而通用模型可以结合多种模态,完成多种任务。
当前,InternLM模型已经完成了多轮的迭代,并在今年的1月,正式升级成为InternLM2:
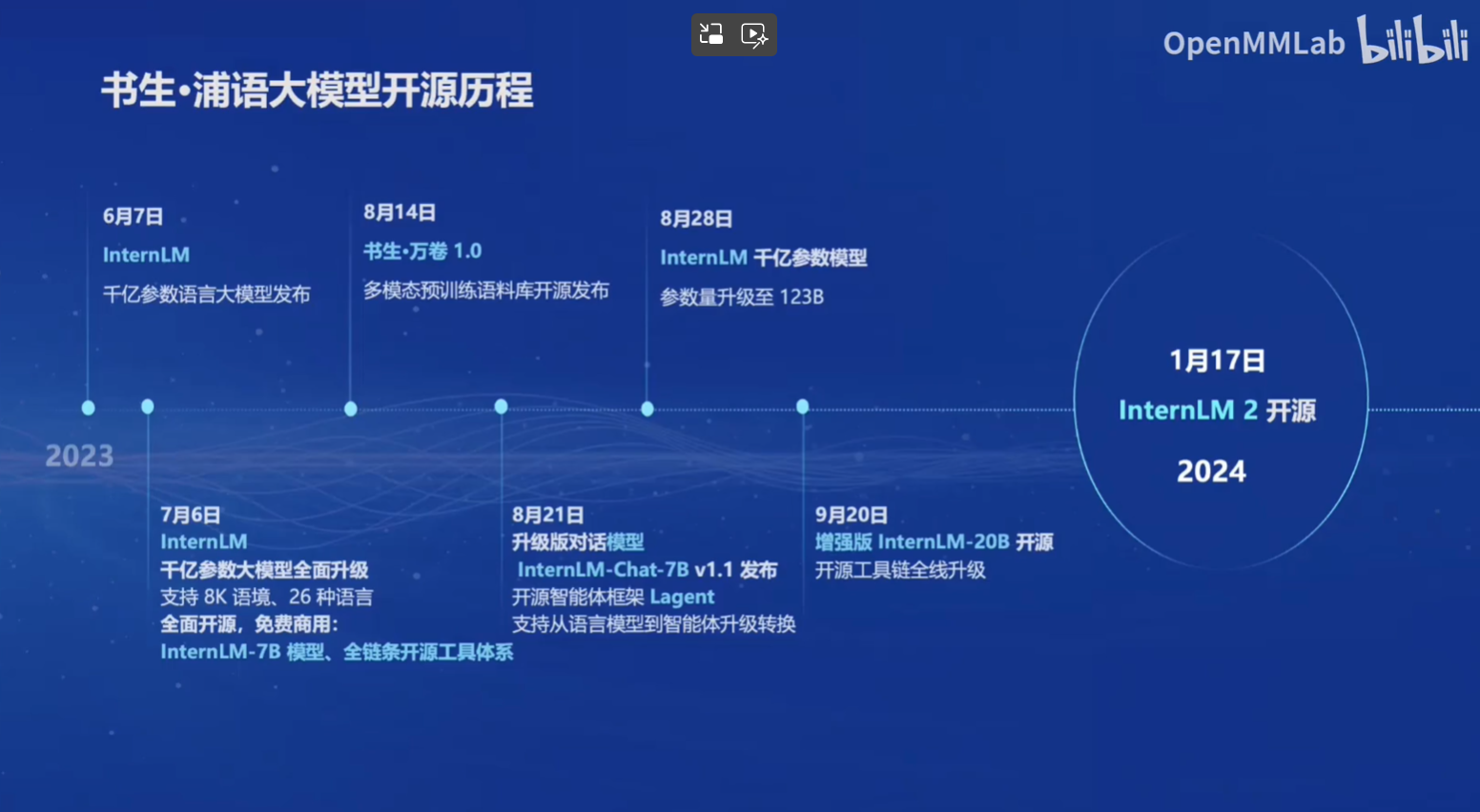
InternLM2目前已经开源了7B和20B的两个规格,而每个规格包含了三种模型的版本。InternLM2-Base相当于一个模型基准,通过对Base在各个方向上进行强化,就得到了InternLM。在Base的基础上,经过SFT(Supervised Fine-Tuning,有监督微调)和RLHF(Reinforcement Learning from Human Feedback,以人类反馈为准绳的强化学习),就得到了具有更强共情能力的InternLM2-chat。
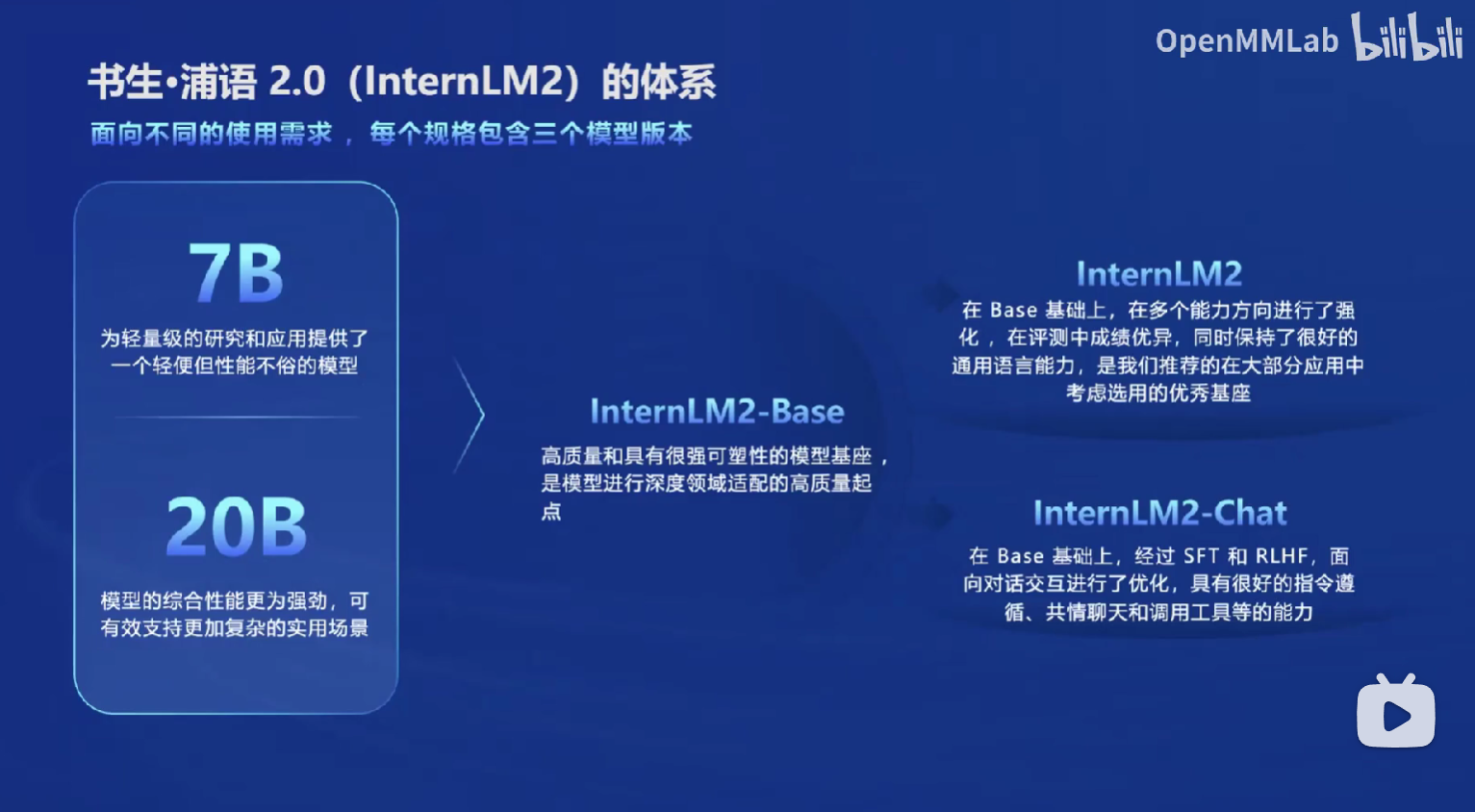
在工程上,从模型到应用的典型流程如下:
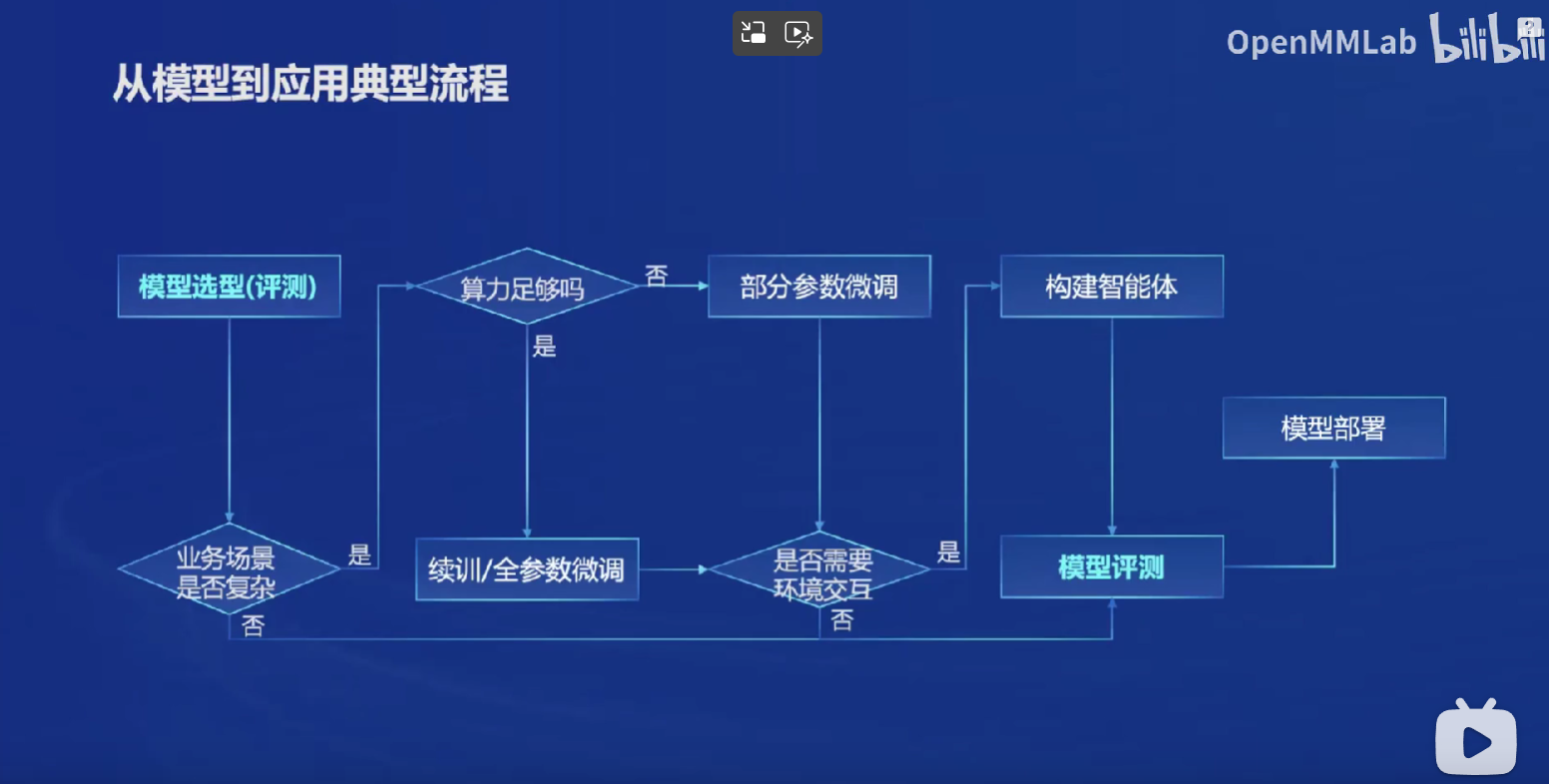
如果业务场景不复杂,那么我们可以直接把已有的模型拿来用,直接进行评测和部署即可;
如果比较复杂,在算力够的情况下,我们可以接着训练,或者做微调,让他适应我们业务的实际场景。如果需要和实际的环境进行交互,则需要构建一个智能体(例如,我们可能需要手动实现一些函数,来让模型学会在场景中调用这个函数实现期待的结果)。
1.2 链路体系
InternLM链路体系如下图所示:

我们要做一个LLM,首先需要有数据。数据的数量(例如,InternLM采用的数据大小为2T)和种类(多种模态)都必须足够丰富。
数据之后,我们要做预训练。让大模型初步掌握数据域中的知识,能够完成各种任务。
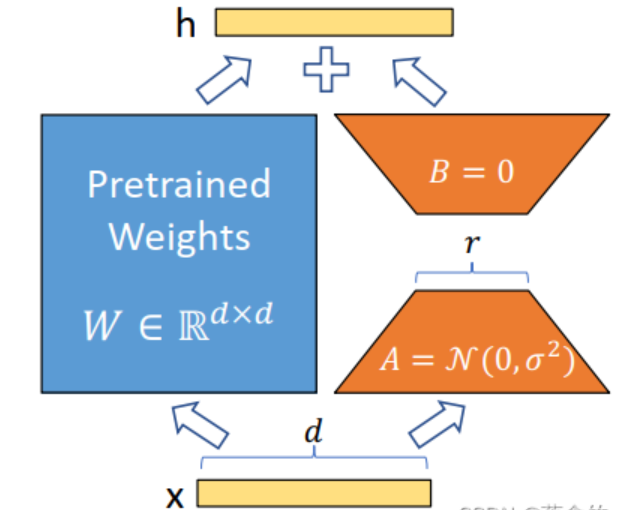
随后是微调。微调的目的是让模型更适应特定领域的知识。InternLM的微调工具是XTuner,它既支持全参数微调,也支持LoRA这种低成本微调。(LorRA的核心思想是通过矩阵低秩分解的角度,来学习真正重要的权重部分,结构如下图:)
在微调之后,模型已经掌握了我们希望它掌握的知识,因此我们需要部署到GPU上,以实现更快的推理。我认为,部署最重要的步骤就是量化,例如对权重采用4bit量化(最近哈工大的团队做到了1bit量化),对key、value进行8bit量化等,可以大大提高速度。此外,还有一些批处理技巧等。
最后,我们要进行评测。评测有多个社区的多个benckmark。上海AI Lab发布了OpenCompass,涵盖了数据污染检查、长文本能力、中英双语、多模态等。
给我有启发意义的是这张图:
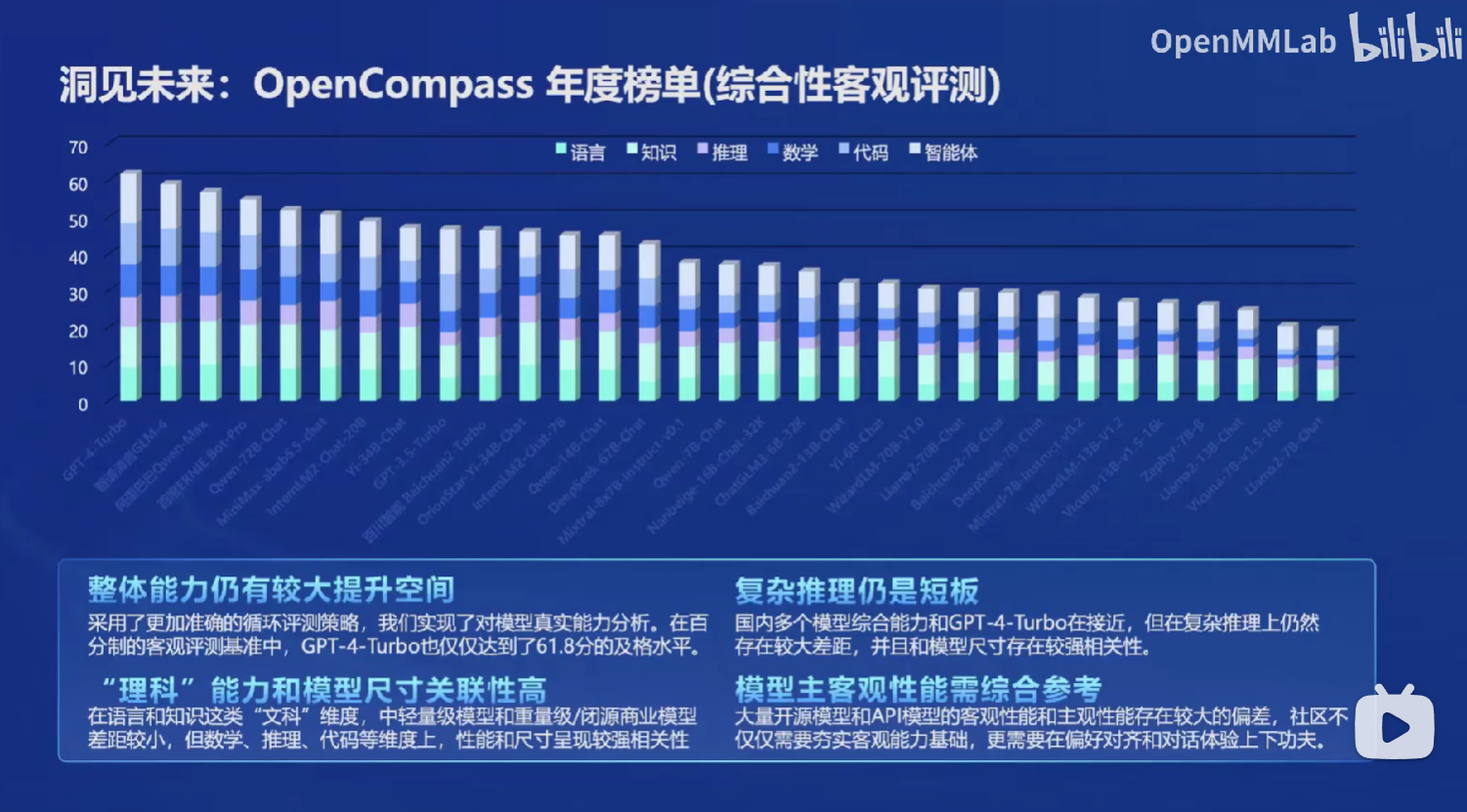
当前的大模型在回答文科或者通用问题上已经比较不错了,但是在理科能力和复杂推理上还有短板,说明还有很大的进步空间。
最终的阶段是应用,那就是对于不同的用户,通过构建智能体的方式达到更精细化的个人需求。
2. Technical Report
整个技术报告中,最核心的有两点:有监督微调(SFT)和人类反馈指导的强化学习(RLHF)。大体上来说,作者通过32k高质量数据有监督地提升模型的长文本能力,使得模型具备200k长度上下文的处理能力。此外,作者提出了有条件的在线RLHF(COOL RLHF),并通过近端策略优化缓解每个阶段出现的奖励黑客攻击(这应该是强化学习里的概念)。COOL RLHF的目的是将模型的价值观与人类的进行对齐。
2.1 SFT
其中,对于SFT,InternLM2模型特别加强了模型对于数学和代码能力的训练,为此,作者筛选了1000万个实例数据,并且保证其是harmless的:
对于7B和20B的模型,在上述数据下训练一个epoch,采用AdamW,学习率是 4 e − 5 4e^{-5} 4e−5。
2.2 COOL RLHF

图(a)是LAMMA2的RLHF的方式。LAMMA2采用明确的奖励模型来解决偏好冲突的问题。
偏好冲突(Preference Conflict)通常指的是在处理用户请求或生成文本时,模型可能面临用户给出的多个偏好或指令之间存在不一致或矛盾的情况。例如,用户可能一方面要求生成的内容要创新和独特,另一方面又要求严格遵循某些规则或模板,这两者之间可能存在冲突。
图(b)是COOL RLHF的方式,条件奖励模型使用不同的系统提示来无缝融合来自各个领域的数据。由于奖励模型是从一个已经学会遵循多样化人类指令的SFT模型初始化的,我们也让奖励模型遵循不同的系统提示,以适应不同场景中的多样化偏好。在条件奖励模型中,系统提示不仅是其输入的一个组成部分;它们还是指导奖励分数与不同场景中特定偏好保持一致的重要工具。这样的整合使得可以在一个统一的奖励模型中管理矛盾和复杂的人类偏好,而不会牺牲准确性。
这篇关于[InternLM训练营第二期笔记]1. 书生·浦语大模型全链路开源开放体系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








