本文主要是介绍QDialog类||QFileDialog文件对话框(打开本地文件)结构及用法(股票数据K线展示案例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
QDialog class 官方文档
QDialog是所有对话框窗口的基类。QDialog作为一种专用的交互窗口,不能作为子部件嵌入其他容器中。
QDialog可能是一个虚拟类,不能被直接导入,其子类QMessageBox等才是真正可用的类
继承自QWidget;被QColorDialog, QErrorMessage, QFileDialog, QFontDialog, QInputDialog, QMessageBox, QProgressDialog, and QWizard继承。
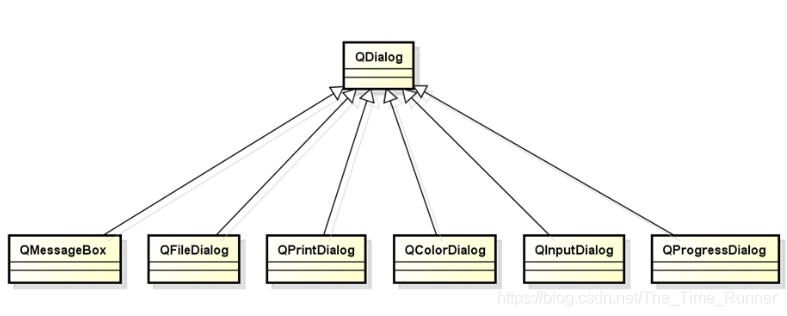
QDialog可以是模式的也可以是非模式的:
- 模式对话框就是阻塞同一应用程序中其它可视窗口的输入的对话框:用户必须完成这个对话框中的交互操作并且关闭了它之后才能访问应用程序中的其它任何窗口。模式对话框有它们自己的本地事件循环。用来让用户选择一个文件或者用来设置应用程序参数的对话框通常是模式的。调用exec()来显示模式对话框。当用户关闭这个对话框,exec()将提供一个可用的返回值并且这时流程控制继续从调用exec()的地方进行。通常,我们连接默认按钮,例如“OK”到accept()槽并且把“Cancel”连接到reject()槽,来使对话框关闭并且返回适当的值。另外我们也可以连接done()槽,传递给它Accepted或Rejected。
- 非模式对话框是和同一个程序中其它窗口操作无关的对话框。在字处理软件中查找和替换对话框通常是非模式的来允许同时与应用程序主窗口和对话框进行交互。调用show()来显示非模式对话框。show()立即返回,这样调用代码中的控制流将会继续。在实践中你将会经常调用show()并且在调用show()的函数最后,控制返回主事件循环。
- “半模式”对话框是立即把控制返回给调用者的模式对话框。半模式对话框没有它们自己的事件循环,所以你将需要周期性地调用QApplication::processEvents()来让这个半模式对话框有处理它的事件的机会。进程对话框(例如QProgressDialog)就是一个实例,在你想让用户能够和进程对话框交互的地方那个,例如撤销一个长期运行的操作,但是需要实际上执行这个操作。半模式对话框模式标记被设置为真并且调用show()函数来被显示。
-
文件对话框QFileDialog 中文参考
用于再应用程序中打开一个外部文件\目录或者需要将当前内容储存到对应文件中。
# 打开文件,并显示成K线def getfiles(self): # 执行打开文件后命令dlg = QtWidgets.QFileDialog() # 实例化一个QFileDialogdlg.setFileMode(QtWidgets.QFileDialog.AnyFile) dlg.setFilter(QtCore.QDir.Files)if dlg.exec_(): # 如果这个对话框运行filenames = dlg.selectedFiles() # 将选中的文件路径及文件名保存下来f = open(filenames[0], 'r') # 执行打开动作,并返回到f中with f: # 如果执行了打开# data_gf = f.read()self.ui.label_4.setText(str(filenames[0])) # 在标签中显示文件路径self.ui.verticalLayout_2.addWidget(self.chart()) # 将数据转变为K线并显示在布局2中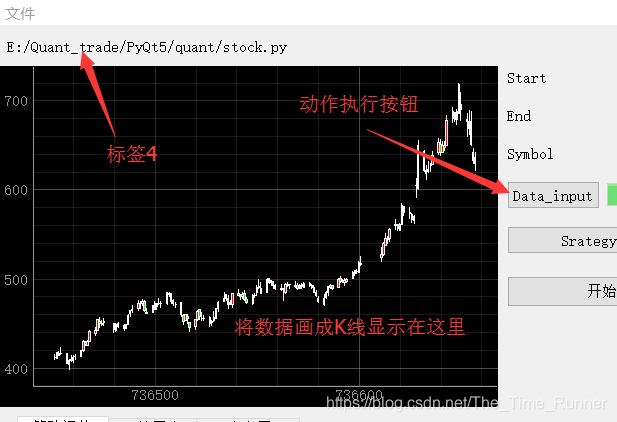
- Reference
- 参考文档
- QT开发(二十)——QT对话框
这篇关于QDialog类||QFileDialog文件对话框(打开本地文件)结构及用法(股票数据K线展示案例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







