本文主要是介绍Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasonin,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
大型语言模型(llm)在复杂任务中表现出令人印象深刻的推理能力。然而,他们在推理过程中缺乏最新的知识和经验幻觉,这可能导致不正确的推理过程,降低他们的表现和可信度。知识图谱(Knowledge graphs, KGs)以结构化的形式捕获了大量的事实,为推理提供了可靠的知识来源。然而,现有的基于kg的LLM推理方法只将kg作为事实知识库,忽略了其结构信息对推理的重要性。在本文中,我们提出了一种称为图上推理(RoG)的新方法,该方法将llm与KGs协同使用,以实现忠实和可解释的推理。具体来说,我们提出了一个计划检索-推理框架,其中RoG首先生成以KGs为基础的关系路径作为忠实计划。然后使用这些计划从KGs中检索有效的推理路径,以便llm进行忠实的推理。此外,RoG不仅可以从KGs中提取知识,通过训练提高llm的推理能力,还可以在推理过程中与任意llm无缝集成。在两个基准KGQA数据集上进行的大量实验表明,RoG在KG推理任务上达到了最先进的性能,并生成了忠实且可解释的推理结果1。
1.介绍
大型语言模型(llm)在许多NLP任务中表现出色(Brown等人,2020;Bang et al, 2023)。特别引人注目的是他们通过推理处理复杂任务的能力(Wei et al, 2022;Huang & Chang, 2023)。为了进一步释放法学硕士的推理能力,提出了计划-解决范式(Wang et al ., 2023c),在该范式中,LLMs被提示生成一个计划并执行每个推理步骤。通过这种方式,llm将复杂的推理任务分解为一系列子任务并逐步求解(Khot et al ., 2022)。
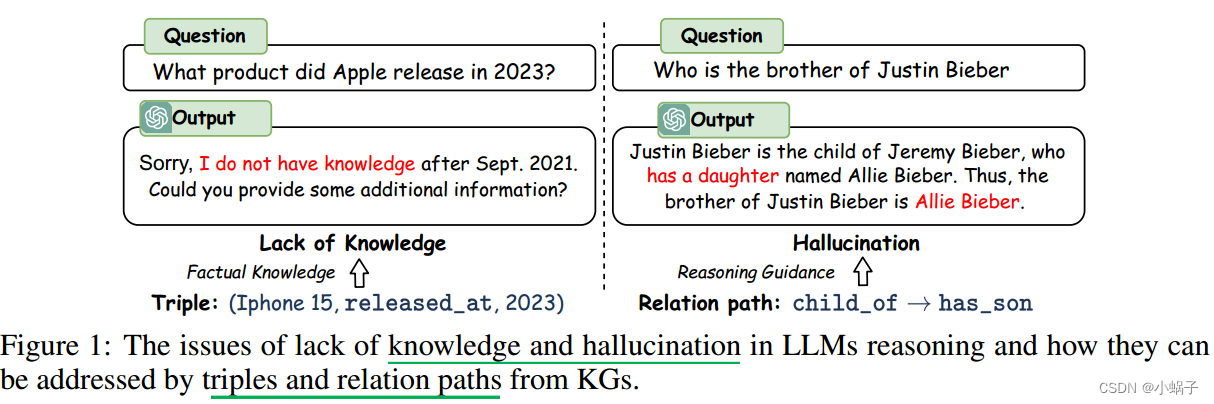
尽管LLMs取得了成功,但他们仍然受到知识缺乏的限制,在推理过程中容易产生幻觉,这可能导致推理过程中的错误(Hong et al, 2023;Wang et al ., 2023b)。例如,如图1所示,llm没有最新的知识,并且产生了一个错误的推理步骤:“有一个女儿”。这些问题在很大程度上削弱了LLMs在高风险场景中的表现和可信度,例如法律判决和医疗诊断。
为了解决这些问题,知识图(KGs)被用于提高llm的推理能力(Pan等人,2024;Luo et al ., 2023a)。KGs以结构化的形式捕获丰富的事实知识,为推理提供了可靠的知识来源。知识图谱问答(knowledge graph question answer, KGQA)是一种典型的推理任务,其目的是基于知识图谱获得答案(Sun et al ., 2019)。以前联合使用KGs和llm进行KGQA推理的工作大致可以分为两类:1)语义解析方法(Lan & Jiang, 2020;Ye et al, 2022),使用llm将问题转换为逻辑查询,并在KGs上执行以获得答案;2)检索增强方法(Li et al ., 2023;Jiang et al ., 2023),该方法从KGs中检索三元组作为知识上下文,并使用llm获得最终答案。
尽管语义解析方法可以通过利用KGs上的推理来生成更准确和可解释的结果,但由于语法和语义的限制,生成的逻辑查询通常是不可执行的,并且无法产生答案(Yu et al, 2022a)。检索增强方法更加灵活,并利用llm的推理能力。然而,他们只将kg视为事实知识基础,而忽略了其结构信息对推理的重要性(Jiang et al ., 2022)。例如,如图1所示,一个关系路径,它是一个关系序列,“child of→has son”可以用来获得“谁是Justin Bieber的兄弟?”这个问题的答案。因此,使llm能够直接在KGs上进行推理,以实现忠实和可解释的推理是至关重要的。
在本文中,我们提出了一种称为图上推理(RoG)的新方法,该方法将llm与KGs协同进行忠实和可解释的推理。为了减轻幻觉和缺乏知识的问题,我们提出了一个规划-检索-推理框架,其中RoG首先通过规划模块生成以KGs为基础的关系路径作为忠实计划。然后使用这些计划从KGs中检索有效的推理路径,通过retrieval reasoning模块进行忠实的推理。这样,我们不仅可以从KG中检索到最新的知识,还可以考虑KG结构对推理和解释的指导。此外,在推理过程中,RoG的规划模块可以与不同的llm进行即插即用,以提高其性能。基于该框架,对RoG进行了两项优化:1)规划优化,将知识从KGs中提取到llm中,生成忠实关系路径作为规划;2)检索-推理优化,我们使llm能够基于检索到的路径进行忠实的推理并生成可解释的结果。我们在两个基准KGQA数据集上进行了广泛的实验,结果表明RoG在KG推理任务上达到了最先进的性能,并产生了忠实且可解释的推理结果。
2 RELATED WORK
LLM推理提示。许多研究提出利用llm的推理能力,通过提示来处理复杂任务(Wei et al ., 2022;Wang et al ., 2022;Yao等,2023;Besta et al, 2023)。plan -and-solve (Wang et al ., 2023c)促使llm生成一个计划,并在此基础上进行推理。DecomP (He et al, 2021)提示llm将推理任务分解为一系列子任务,并逐步求解。然而,幻觉和缺乏知识的问题影响了llm推理的准确性。ReACT (Yao et al ., 2022)将llm视为agent,与环境交互以获取最新的知识进行推理。为了探索忠实推理,FAME (Hong et al ., 2023)引入了蒙特卡洛规划来生成忠实推理步骤。RR (He et al ., 2022)和KD-CoT Wang et al . (2023b)进一步从KGs中检索相关知识,为llm生成忠实的推理计划。
知识图谱问答(KGQA)。传统的基于嵌入的方法表示嵌入空间中的实体和关系,并设计特殊的模型体系结构(例如键值记忆网络、顺序模型和图神经网络)来推理答案 。为了将llm集成到KGQA中,检索增强方法旨在从KGs中检索相对事实以提高推理性能(Li et al ., 2023;Karpukhin et al, 2020)。最近,UniKGQA (Jiang et al ., 2022)将图检索和推理过程统一为具有llm的单个模型,实现了STOA性能。语义解析方法通过llm将问题转换为结构化查询(例如SPARQL),查询引擎可以执行该查询以在KGs上推理答案(Sun et al ., 2020;兰江,2020)。然而,这些方法严重依赖于生成查询的质量。如果查询不可执行,则不会生成任何答案。DECAF (Yu et al ., 2022a)结合语义解析和llm推理共同生成答案,在KGQA任务上也达到了显著的性能。
3 PRELIMINARY

4 APPROACH
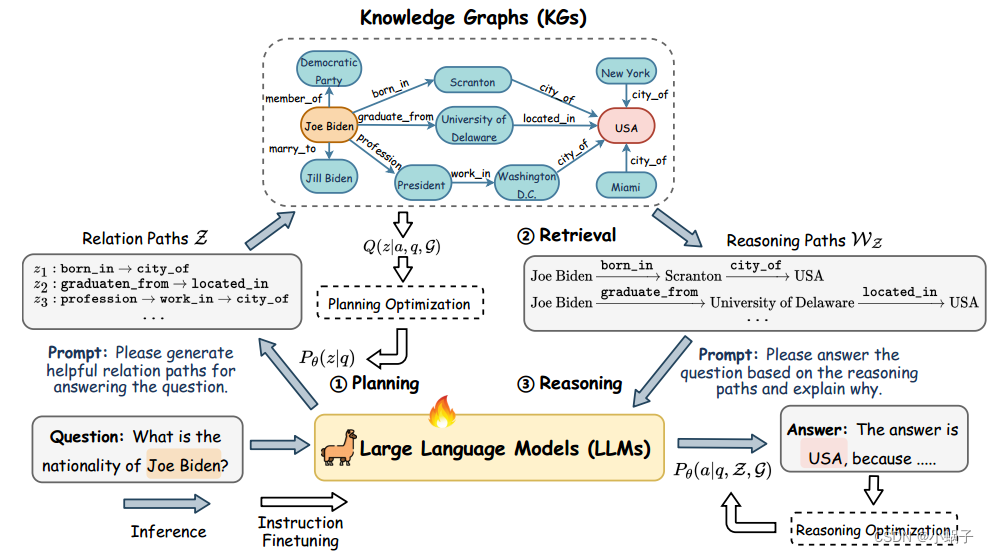
在本节中,我们将介绍我们的方法:图上推理(RoG),它包含两个组成部分:1)一个规划模块,该模块生成以KGs为基础的关系路径作为忠实计划;2)检索推理模块,首先根据计划从KGs中检索有效的推理路径,然后根据检索到的推理路径进行忠实推理,生成具有可解释解释的答案。RoG的总体框架如图2所示。
4.1 REASONING ON GRAPHS: PLANNING-RETRIEVAL-REASONING
4.1图上推理:规划-检索-推理
最近,人们探索了许多技术,通过计划来提高llm的推理能力,首先促使llm生成推理计划,然后在此基础上进行推理(Wang et al ., 2023c)。然而,llm以幻觉问题而闻名,这容易产生错误的计划并导致错误的答案(Ji et al, 2023)。为了解决这个问题,我们提出了一个新的计划-检索-推理框架,该框架将推理计划以KGs为基础,然后为LLM推理检索可靠的推理路径。
关系路径捕获实体之间的语义关系,已被用于KGs上的许多推理任务(Wang等人,2021;Xu et al, 2022)。此外,与动态更新的实体相比,KGs中的关系更加稳定(Wang et al ., 2023a)。通过使用关系路径,我们总是可以从KGs中检索到最新的知识进行推理。因此,关系路径可以作为推理KGQA任务答案的忠实计划。

通过将关系路径视为计划,我们可以确保计划以KGs为基础,从而使llm能够对图进行忠实且可解释的推理。简而言之,我们将我们的RoG描述为一个优化问题,其目的是通过生成关系路径z作为计划,最大限度地从知识图G中推理出问题q的答案的概率:

4.2 OPTIMIZATION FRAMEWORK
4.2优化框架
尽管llm具有将关系路径生成为计划的优势,但llm对KGs中包含的关系一无所知,因此llm不能直接生成以KGs为基础的关系路径作为忠实计划。此外,lllm可能无法正确理解推理路径,并基于它们进行推理。为了解决这些问题,我们设计了两个指令调优任务:1)规划优化,将KGs中的知识提取到llm中以生成忠实关系路径作为计划;2)检索-推理优化,使llm能够基于检索到的推理路径进行推理。
方程1中的目标函数可以通过最大化证据下界(ELBO)来优化(Jordan et al ., 1999),其表示为
![]()
式中,Q(z)表示以KGs为基础的忠实关系路径的后验分布,后一项最小化了后验与先验之间的KL分歧,从而鼓励llm生成忠实关系路径(规划优化)。前一项最大化了检索推理模块基于关系路径和KGs(检索推理优化)生成正确答案的期望。
Planning optimization.
在规划优化中,我们的目标是将知识从KGs中提取到llm中,以生成忠实关系路径作为规划。这可以通过最小化忠实关系路径Q(z)的后验分布的KL散度来实现,这可以通过KGs中的有效关系路径来近似。

4.3 PLANNING MODULE
4.3规划模块
规划模块旨在生成忠实的关系路径作为回答问题的计划。为了利用llm的指令跟随能力(Wei et al ., 2021),我们设计了一个简单的指令模板,提示llm生成关系路径:

4.4 RETRIEVAL-REASONING MODULE
4.4检索推理模块

尽管我们可以利用检索到的推理路径,直接得到多数投票的答案。检索到的推理路径可能是嘈杂的,与问题无关,从而导致错误的答案(He et al, 2021;Zhang et al, 2022)。因此,我们提出了一个推理模块来探索法学硕士识别重要推理路径并根据它们回答问题的能力。
推理。推理模块以问题q和一组推理路径Wz生成答案a。同样,我们设计推理指令提示符,引导llm根据检索到的推理路径Wz进行推理。Wz也被格式化为一系列结构句。详细提示可在附录A.10中找到。
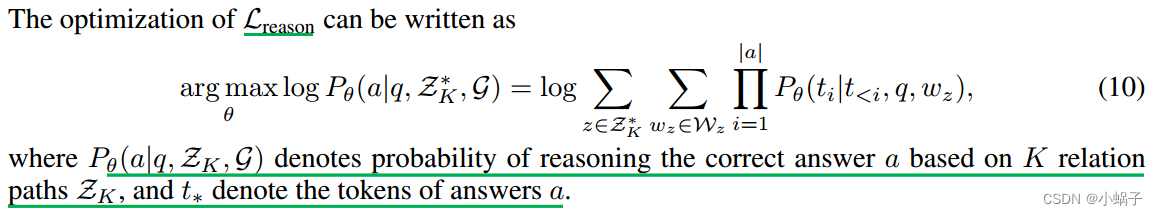
这篇关于Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasonin的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)