本文主要是介绍2022 Tesla AI Day -特斯拉自动驾驶FSD的进展和算法软件技术之数据以及虚拟,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2022 Tesla AI Day -特斯拉自动驾驶FSD的进展和算法软件技术之数据以及虚拟

附赠自动驾驶学习资料和量产经验:链接
人工智能算法犹如电影的主演,我们很多时候看电影只看到主演们的精彩,但其实电影的创意和呈现都来自于背后的导演和制片等团队。而人工智能算法背后的有关数据的软件,设施,虚拟犹如电影的导演和制片等团队。他们是塑造算法,成就算法的核心力量。
本文我将通过2022特斯拉AI Day发布的信息,继上文Tesla AI Day -特斯拉自动驾驶FSD的进展和算法软件技术之算法
1. 路径以及运动规划算法:当算法植入到终端(车或者机器人),终端通过算法感知环境,规划路径,确保安全,平顺前进。
2. 环境感知算法:
- Occupancy 算法,也就是可活动空间探测
- Lane & Objects 车道以及物体算法,交通中的信息语义层也就是车道线,物体识别以及运动信息。**之后分享下算法背后的数据以及相关软件设施,**大体框架如下:
3. 训练算法设施以及软件:
- 训练数据的设施,超算中心用来支持数据处理,算法训练。- 人工智能算法的编译器以及推理,就是训练算法的框架以及软件方法。
4. 数据标注,采集和虚拟:
- 自动标注算法,训练环境感知算法必须需要已经具有标签的数据,自动标注算法就是标注数据,训练环境感知算法识别这类场景或者物体。
- 环境虚拟,合成制造虚拟场景。- 数据引擎,现实场景车辆,测试软件获取真实场景环境数据,闭环数据引擎,更正标签等。
3.训练算法设施以及软件
算法都是基于数据训练出来的,也就是需要大数据喂出来。特斯拉表示需要训练Occupancy Networks算法,特斯拉目前已经从采集视频中提取出14.4亿张图片,需要训练这些数据,需要10万个GPU满负荷工作一个小时到90度的计算。
但现实中特斯拉构建的3个超算中心,采用了1.4万个GPU,其中4000个用于自动标注数据,其中10000个用于训练算法。

目前有30PB分布式视频缓存,1PB=1048576GB你想想30PB多大。其中抽取了1600亿张图片。而且这些数据不是静态的,是动态流转的,每天50万个视频轮流缓存更替,每秒40万个视频转化。所以显然,特斯拉当前这数据中心按照正常的方法肯定行不通,同时可想而知特斯拉对于GPU超算的饥渴程度,另外特斯拉还想加速他的计算能力,这样决定了特斯拉必须自己搞芯片。但是仅仅有了芯片就行了?显然海量数据的管理和训练方法都是难题。
那么怎么最优的训练这庞大的数据呢?难点在哪里?
就成了特斯拉现在考虑的问题,特斯拉给出的答案是从数据的存储,到数据的加载,最后处理,形成一个倒漏洞的形状,最大限度的压榨计算资源。

要实现这些,必须考虑数据量的分配,数据流的带宽,CPU,内容,机器学习的框架,而多台GPU同步运算你要考虑延迟,考虑GPU之间的带宽。这是非常复杂的。
特斯拉的方案是:
首先视频是动态和复杂的,不是简单的图片机器学习,特斯拉的视频到图片再到学习处理过程是动态,所以第一步加速视频库可以增加30%的训练速度。
特斯拉采用Pytorch ,进行视频压缩类的工作,加速视频库,例如下图中I 帧(帧内编码图片)是完整的图像,例如JPG或BMP图像文件。P帧(预测图片)仅保存图像与前一帧相比的变化。例如,在汽车穿过静止背景的场景中,只需要对汽车的运动进行编码。编码器不需要在 P 帧中存储不变的背景像素,从而节省空间。P 帧也称为增量帧。
另外就是视频数据的归类,说实话比较复杂,以后有时间有价值再仔细看吧。

总的来讲通过这种方式,特斯拉实现了2.3倍的训练速度增加,现在特斯拉用1024块GPU可以实现几天内从头开始聚合这些数据。
另外数据源源不断的压进计算中心,**就轮到了计算芯片,如何最优处理算法呢?**这里就提到了算法编译器compiler以及reference推理。
什么是算法编译器以及推理?
了解这节时候我们先要了解什么是算法编译器compiler,他将AI算法模型映射到高效的指令集和数据流。它还执行复杂的优化,例如层融合、指令调度和尽可能重用片上内存。

为什么要优化编译器?
其实特斯拉的人工智能算法代码运行会并行,重复以及回滚,那么特斯拉想要解决的问题是,如何高效的让代码运行在芯片上面,例如不重复计算,计算之间编排紧凑不空闲不堵塞,这样可以减少延迟,降低功耗。
怎么做?
特斯拉设计了一个Arc Max 以及一个中央操作来将稀疏(例如车道的空间位置)编码到首页,然后选择学习算法过程链接到首页。然后在静态内存SRAM中构建一个查询表格,把重复算法存入缓存,这样就不需要重复计算,只需要查询调用。

所以特斯拉表示就在FSD车道识别算法中,这项编码提升了其算法9.6ms的延迟,能耗大概只有8w。
特斯拉表示这种编码的思维贯穿到整个特斯拉FSD算法中,特斯拉构建了一个新的算法编译器用来编译超过1000多个算法信号

这样特斯拉通过编译器和推理的优化,确保优算力,低功耗,低延迟的AI 计算,这也就是大家常说的不拼算力,拼算法软件。
那么分享完算法优化,计算优化,接下来就是关于数据。
4.数据标注,采集和虚拟
数据标注,这个毋庸置疑,人工智能的基础就是基于现实数据,总结出规律,然后产生公式用于预测,这就是形成了算法。数据喂的越多,那么算法公式也就越精准。所以海量数据是精准算法的基础,而海量数据的前提是这些数据需要有标签也就是告诉机器这些数据是什么?数据标注有两种方法,第一种就是人类标注,依靠人给数据打标签,这是非常庞大的耗时耗人力的方式,但现实中确实是这么干的,还有些只有是人干。第二种就是自动标注,还记得之前文章《被美国禁售的A100和H100 ,MI250人工智能芯片能干啥?》中人工智能算法三个基础数学,其中有一个是cluster你可以认为他是归类,自动标注就是用归类方法去标注。自动标注显然是省时省力的事情,所以看特斯拉如何利用自动标注。
困难点在哪里?
拿上文的车道算法举例,特斯拉认为他要实现十字路口车道算法,大概需要几千万个驾驶旅程,经过大概百万个十字路口。特斯拉目前大概每天有50万个旅程,但是要把这些旅程转化成可训练的数据是非常难的课题,特斯拉表示尝试了各种人工和自动标注方法,显然不太可能。
所以特斯拉开发的新自动标注算法对一万个驾驶旅程的12个小时自动标注,可以抵充500万个小时的人工标注。

特斯拉怎么做到的?
特斯拉表示其车道算法的自动标注,主要采用以下三个步骤来实施:
首先通过车辆获取车辆的高精轨迹信息,之后通过算法将多旅程重构到一张地图中然后自动标注车道信息网络。详细步骤如下:

1. 高精轨迹获取,上面提到特斯拉每天可以获取到50万个旅程,这些旅程的采集信息为车辆的视频,车辆运动IMU陀螺仪,速度作为原始信号输入,之后在车上的2个CPU线程(所有开通FSD的车辆产生这些信息)去跟踪优化,特征提取输出车辆6个自由度100hz的运动轨迹以及3D结构的道路细节。
2. 多旅程重构,因为所有的车辆信息都是来自于不同的车辆,所以需要基于他们的高精轨迹信息,进行旅程的道路信息的匹配,重构,接缝优化,包面优化,最后人工分析师最后把关,形成了多重旅程的轨迹信息。
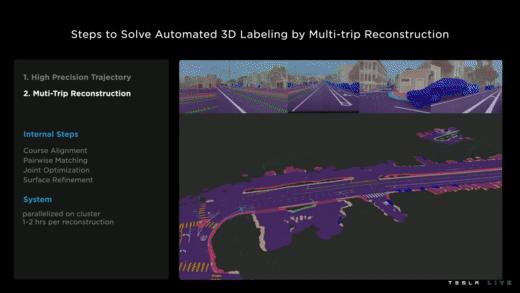
3. 自动标注旅程,当然自动标注只会去标注新添加的旅程,而不是去重构所有的片段,所以大概半个小时标注一段旅程而不是人工标注的几个小时。特斯拉宣称,这种标注方式极其容易规模化,只需要有计算单元以及驾驶旅程信息,如上图所示,就视屏的时间内,来自于53台车的数据,就自动标注了50组数据。当然特斯拉也表示自动标注的方法应用在特斯拉算法的各个方面。
但特斯拉表示现实的数据,获取困难同时很难去标注,但是传统的3D的场景的重构却异常缓慢。 所以特斯拉表示在虚拟验证方面其应用新的方法5分钟就能够构建3D虚拟场景。
虚拟验证能做什么?
特斯拉的建模是首先把场景的真值(Ground truth)输入3D建模软件Houdini,先开始构建道路的边缘,在构建路面地理特征,之后将车道信息投影进入路面,接下来使用道路中间的边缘形成绿化岛。这样基本的主要特征形成,那么道路两边的树以及建筑物都可以随机构建。

有了这些基础之后,引入地图交通信息,例如红绿灯和停车,车道信息,甚至道路的真实名字。
之后偶发性的引入行人,车辆交通形成了场景的基础。再后可以去改变场景的天气,光线等形成模拟无穷无尽的场景,供自动驾驶验证。当然特斯拉表示以上仅仅为基本的,这个其实应该很多自动驾驶公司都能做到例如之前文章《Cruise以及其自动驾驶技术》中提到通用的Cruise 也采用,特斯拉更进一步去改变道路的真值形成新的场景,例如之前算法中将到的十字路口车道线场景,可以改变里面的车道信息,创建更多基于真实场景的变种场景,来帮助算法训练,而不是只能通过现实采集。
所以特斯拉有了虚拟数据,可以快速的进行各种场景的虚拟测试去优化算法,而省去实际测试费时费力的时间。**如何做到的呢?**特斯拉表示其主要创新和亮点是虚拟验证的架构,他可以确保所有的东西串起来运行。

如上文介绍虚拟世界的建模,先有道路交通真值信息,然后元素创造者将交通信息标签转换成元素,例如上文将到的车道线,马路牙子,建筑物等都属于元素。再通过元素提取工具将这些信息分成几何信息和交通实例元素放到150平米Geohash中,并给他命名ID 方便使用加载调用。
这样建模信息更加简洁,更容易加载和渲染,然后使用元素加载器工具,特斯拉可以使用Geohash ID编码去加载任意数量的缓存切片,一般虚拟的时间就加载感兴趣的地点以及周边。最后是虚拟引擎生成场景。

这样特斯拉就让一个工程师工作2周就可以生成旧金山的街道虚拟世界,而非几个月甚至年来做单位。同样特斯拉可以利用此项PDG技术快速拓展到其他地方或者城市国家,或者更新原有的虚拟世界,确保数据依据现实动态发展。
数据引擎 - 现实数据采集器为什么?
其实在看这一章的时候,**想了想特斯拉的仿真能力这么强,还要现实跑车去采集数据干啥?**其实很多corner case 极端的场景,都需要通过真实场景去发现,然后优化数据,帮助解决人员介入。
首先看这个场景,特斯拉的FSD正在进入弯路口,通过这里的时候,看到旁边有一个车子,现有算法下的特斯拉会认为有车子在等待通行,所以特斯拉自动驾驶车子会减速,但现实这是一个没有人在里面的奇怪停车。

这种场景估计任何脑洞大开的虚拟验证都不会想到,必须要有实际场景来识别这类corner case极端场景,所以自动驾驶真实场景数据的收割必须要有,而且还是动态发展的,不同时间,不同城市,不同文化的数据都会不一样。所以特斯拉构建了一个工具去识别错误的判断并去纠正标签,并把这个片段归类为需要重新评估的系列。这个场景特斯拉把它诊断为挑战性的在转弯处有停车的场景,目前特斯拉识别了126个这样的场景,挖掘以及促进训练了1.39万视频数据,来提升预测准确性。

需要解决这类场景,特斯拉需要挖掘成千上万这种场景,而特斯拉可以利用数据采集车辆(客户的车,或者自己试验车),以及设备去采集和更正标签来解决这种琐碎的场景。
特斯拉把这种数据引擎框架实施到所有算法的持续优化中,特斯拉的数据引擎,是一个完整的从实验车型,虚拟验证,终端用户的流。无论它们是 3D多机位视频数据,是否人工标记 自动标记或模拟数据无论是离线模型还是在线模型。

特斯拉能够大规模的的使用数据引擎的基础设施为特斯拉的算法提供数据食物,的主要原因还有其庞大的车队:终端用户汽车影子模式传输客户使用FSD时候的介入信息,实验车队的再确认数据。总结
看完这个特斯拉的算法,数据等结构之后,我的第一想法是“高级的码农玩的是思维方式和艺术结构,而不是按照规则去交付”。当然我肯定无法评价这个算法结构是好还是坏,但可以肯定的是特斯拉的智能驾驶算法是一种坚定的态度思维。
特斯拉的算法态度和思维是“基于视觉的人工智能算法,一定能够汽车或机器人自动驾驶和导航,犹如人类仅仅使用眼睛和大脑实现安全驾驶或行走到达目的地”。这种态度和思维如人工智能算法的数学基础“任意两点之间一定存在一条可以将他们连接起来的直线”。当然特斯拉的最终理想是将此类算法拓展到AGI(Artificial general intelligence,通用人工智能( AGI ) 理解或学习人类可以完成的任何智力任务的能力。),让我们拭目以待,不过可以肯定的是这条道路必定是坎坷的,每一个人类基本上花大概18年才成年才具备进入社会独立的能力,而且一生都不断的接触新东西不断学习,所以何况是刚刚起步的人工智能。
这篇关于2022 Tesla AI Day -特斯拉自动驾驶FSD的进展和算法软件技术之数据以及虚拟的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







