本文主要是介绍TensorFlow使用之tf.layers.batch_normalization函数详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、写在前面
这是我的处女作,其实想写写自己的博客有一段时间了,主要也是为了记录自己所学到的新知识点,以后可以再来回顾一下,另则加深印象。由于最近在准备做OCR识别的内容,后来遇到了tf.layers.batch_normalization()这个函数,经过多方的学习网上大佬们的文章之后,在此以最简单的方式来说说这个函数,并把自己学习的过程走过的弯路在此记下,希望有缘人能够看到,互相交流。
2、标准化
我看了很多其他的博客文章,谈及这个API的时候有的称之为批归一化,也有的称之为批标准化,我个人的观点是批标准化,主要原因是因为这个API在对数据进行处理时用到的公式,这个公式在后文会给出来,其次也是因为normalization这个单词的翻译也是标准化(原谅我这么肤浅),对于为什么对数据进行标准化处理之后一般都能够得到比较好的效果呢,个人认为是因为目前的机器学习一个基本前提假设都是数据独立同分布的,而标准化过程就是将经过卷积池化等一系列操作之后的数据特征仍然服从正态分布,从而能够取得一定的效果,顺便提一下标准化是对未激活的特征进行处理的,也就是说在模型构建的时候,在标准化层之前的卷积是不能使用激活函数的,激活函数要单独放在标准化层之后,至于为什么,我在其他文章也没有看到比较理想的答案,个人的理解是因为标准化层的存在是因为我们想要得到数据在一系列变换之后服从什么分布,自然不能对数据特征进行非线性变换,不然就不能得到正确的数据分布情况了。
3、TensorFlow中的标准化公式
网上很多文章写了关于标准化的公式,结果都不满意,因为对于理解tf.layers.batch_normalization这个API帮助不是很大,或者说准确的来说在TensorFlow中用到的标准化公式其实应该是这个公式,这个公式还是我在一个公众号里无意间看到的。
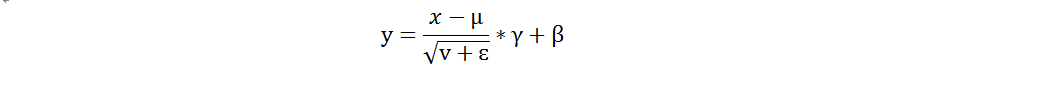
其中µ、v为批量数据的均值和方差,ɛ为防止分母出现零所增加的变量,γ和β是缩放(scale)、偏移(offset)系数,这个公式对于搞懂这个API参数帮助很大,至于为什么有γ和β其实很好理解,因为数据进过模型的特征提取过后我们就不能知道数据服从什么分布了,所以需要学习这些参数来确定特征提取之后的数据分布情况。
4、滑动平均(移动平均)
这篇文章说的是批标准化,为啥和滑动平均扯上关系了呢,是因为在上面的公式里面有µ、v参数,在模型训练阶段很自然的我们能够得到当前批次的µ、v值,但是对于测试和预测的时候就不行了,所以我们需要用到滑动平均值,具体的大家可以去看看这篇博客滑动平均,我们先记下滑动平均的公式
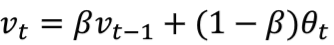
至于在tensorflow模型当中是如何计算的,我会在后文提及,因为我发现关于具体计算过程并没有相关文章介绍,不知道是不是这个问题太简单了,大家都选择跳过了呢,反正我是捣鼓了几个小时才搞明白,希望对有和我一样的朋友有所帮助。
5、函数的部分参数解释
inputs:上一层的输出,批标准化的输入,一般是四维的tensor(B,H,W,C),这里就不多说了,应该都知道。
axis:默认值是-1,也就是说默认的是最后一个维度,这个参数的意思是批标准化处理的维度是以最后一个维度进行的,也就是channel,当然你也可以改(万一有奇迹呢,AI有时候就是不按常理出牌)
momentum:默认是0.99,这个参数就是滑动平均的β值,当然了你也可以修改
epsilon:默认是1e-3,呐,这个就是标准化公式里面的ɛ参数,之前网上很多文章给出的公式并没有ɛ,所以导致我一直不明白这个是啥。
center:默认True,也就是是否使用标准化公式里面的β参数,默认肯定是要用的,不用的话,那就毫无意义了。
scale:默认True,也就是是否使用标准化公式里面的γ参数,同样需要使用。
beta_initializer:默认init_ops.zeros_initializer(),β参数的初始化,也就是默认初始化全为0。
gamma_initializer:默认init_ops.ones_initializer(),γ参数的初始化,也就是默认初始化全为1。
moving_mean_initializer:默认init_ops.zeros_initializer(),就是计算均值的滑动平均值时的初始化值,明白了滑动平均的计算方法后自然明白了。
moving_variance_initializer:默认init_ops.ones_initializer(),计算方差时的滑动平均值时的初始化值。
beta_regularizer:β权重正则化操作,也就是一般所说的正则化。
gamma_regularizer:γ权重正则化操作。
beta_constraint:现在还不知道是做啥用的,应该是一个函数之类的东东。
gamma_constraint:上同,不过不影响我们使用这个API
training:默认为False,是否是训练阶段,这个参数很关键,不然很坑人。
trainable:默认为True,这个我觉得就不要改了,没必要给自己找麻烦,就是把我们标准化公式里面的参数添加到GraphKeys.TRAINABLE_VARIABLES这个集合里面去,因为只有添加进去了,参数才能更新,毕竟γ和β是需要学习的参数。
后面还有一些参数我就不介绍了,和renorm相关的参数,我也没有去看那篇论文,有需要深入学习的朋友可以去看看论文。Batch Renormalization其实真正用到的参数也就那么两三个,但是了解更加清楚一些也很必要。
6、批标准化处理中的计算过程
我以图像数据为例,由于第一次写博客,也找不到好图,我就直接文字描述了,过程毕竟也不复杂。
假设我们现在有这样的数据格式(B,H,W,C)对应为(10,5,5,3)的数据,在经过卷积,池化等一系列操作之后,我们得到的特征是(10,3,3,64),也就是我们得到的是批次大小为10,map大小为33,通道数为64的features map,因为我们批标准化的维度是以channel进行的,我们可以结合传统机器学习的数据格式进行分析,是不是相当于我们现在有10条样本数据,而每一个样本数据的特征维度大小是64,而每一个特征值是33=9的向量,然后结合我们的标准化公式和滑动平均的公式,应该能够想明白计算过程了,原谅我也不知道咋说清楚。当然这是我的个人理解,如有不对的地方望指出。
7、使用过程中会遇到的坑
这里网上有很多相关文章,我就发一个链接为例吧,实在是不想写了,注意事项
第一次写,就写到这里吧,想写的好多呀,因为每次都发现自己当时搞明白的问题,过段时间又忘了,又要去查资料太麻烦了,以后希望能够写的越来越好吧。
这篇关于TensorFlow使用之tf.layers.batch_normalization函数详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




