本文主要是介绍基于XGBoost和数据预处理的电动汽车车型预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

基于XGBoost和数据预处理的电动汽车车型预测
文章目录
- 基于XGBoost和数据预处理的电动汽车车型预测
- 1、前言
- 2、导入数据
- 3、各县电动汽车采用情况条形图
- 4、电动车类型饼图
- 5、前5最欢迎的电动车制造商
- 6、XGBoost模型
- 6.1 字符串列的标识
- 6.2 删除不相关的列
- 6.3 编码分类变量
- 6.4 电动车类型热编码
- 6.5 将数据划分训练集和测试集
- 6.6 为训练集和测试集创建DMatrix
- 6.7 XGBoot模型
- 6.8 预测和计算准确值
作者:i阿极
作者简介:数据分析领域优质创作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
大家好,我i阿极。喜欢本专栏的小伙伴,请多多支持
| 专栏案例:机器学习案例 |
|---|
| 机器学习(一):线性回归之最小二乘法 |
| 机器学习(二):线性回归之梯度下降法 |
| 机器学习(三):基于线性回归对波士顿房价预测 |
| 机器学习(四):基于KNN算法对鸢尾花类别进行分类预测 |
| 机器学习(五):基于KNN模型对高炉发电量进行回归预测分析 |
| 机器学习(六):基于高斯贝叶斯对面部皮肤进行预测分析 |
| 机器学习(七):基于多项式贝叶斯对蘑菇毒性分类预测分析 |
| 机器学习(八):基于PCA对人脸识别数据降维并建立KNN模型检验 |
| 机器学习(十四):基于逻辑回归对超市销售活动预测分析 |
| 机器学习(十五):基于神经网络对用户评论情感分析预测 |
| 机器学习(十六):线性回归分析女性身高与体重之间的关系 |
| 机器学习(十七):基于支持向量机(SVM)进行人脸识别预测 |
| 机器学习(十八):基于逻辑回归对优惠券使用情况预测分析 |
| 机器学习(十九):基于逻辑回归对某银行客户违约预测分析 |
| 机器学习(二十):LightGBM算法原理(附案例实战) |
| 机器学习(二十一):基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习(二十二):基于逻辑回归(Logistic Regression)对股票客户流失预测分析 |
1、前言
这组代码片段对通过华盛顿州许可部注册的纯电动汽车(BEV)和插电式混合动力汽车(PHEV)的数据集进行了各种分析。这些代码产生了一些见解,如按城市划分的电动续航里程统计数据、CAFV资格计数、电动汽车制造商的受欢迎程度、续航里程统计(最大、最小、平均)、电动汽车类型分布、按车型年份划分的采用趋势以及按县划分的采用情况。结果保存在CSV文件中,并通过条形图、折线图和饼图进行可视化。这些分析为华盛顿州的电动汽车前景和采用模式提供了宝贵的见解。
2、导入数据
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsdata = pd.read_csv("./us_car_data.csv")
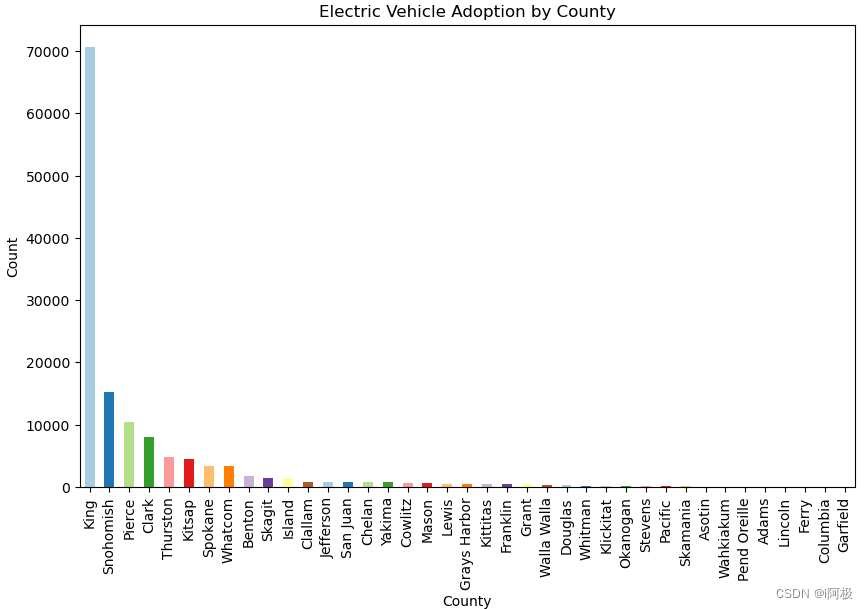
3、各县电动汽车采用情况条形图
count_by_county = data["County"].value_counts()
plt.figure(figsize=(10, 6))
count_by_county.plot(kind='bar', color=colors)
plt.xlabel("County")
plt.ylabel("Count")
plt.title("Electric Vehicle Adoption by County")
plt.show()
此代码创建了一个条形图,显示每个县采用电动汽车的情况。每个小节代表一个县,小节的高度代表该县的电动汽车数量。x轴标记为“县”,y轴标记为为“计数”,图表标题为“各县电动汽车采用情况”。
运行结果如下:
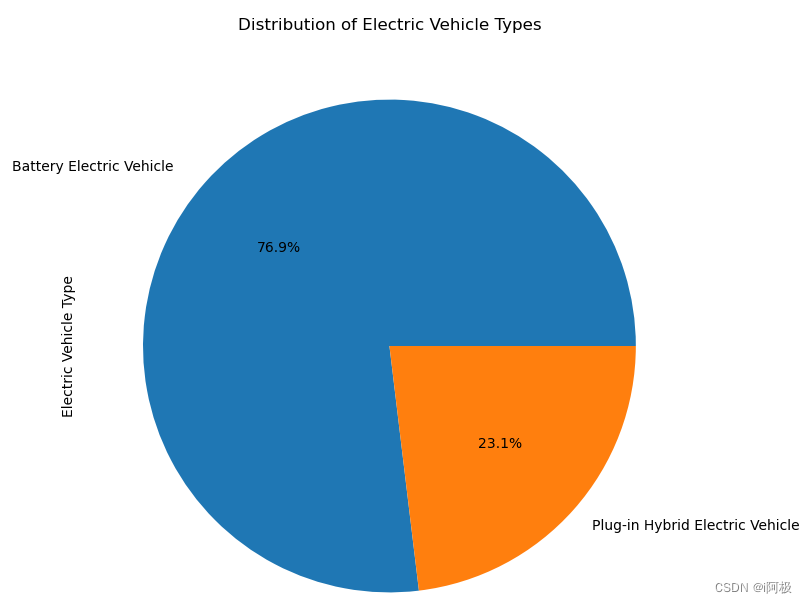
4、电动车类型饼图
vehicle_types = data["Electric Vehicle Type"].value_counts()
plt.figure(figsize=(8, 8))
vehicle_types.plot(kind='pie', autopct='%1.1f%%')
plt.title("Distribution of Electric Vehicle Types")
plt.show()
此代码创建一个饼图,显示不同类型电动汽车的分布情况。饼图的每一部分都代表一种特定的车辆类型,每种类型的百分比如图所示。图表的标题是“电动汽车类型的分布”。
运行结果如下:
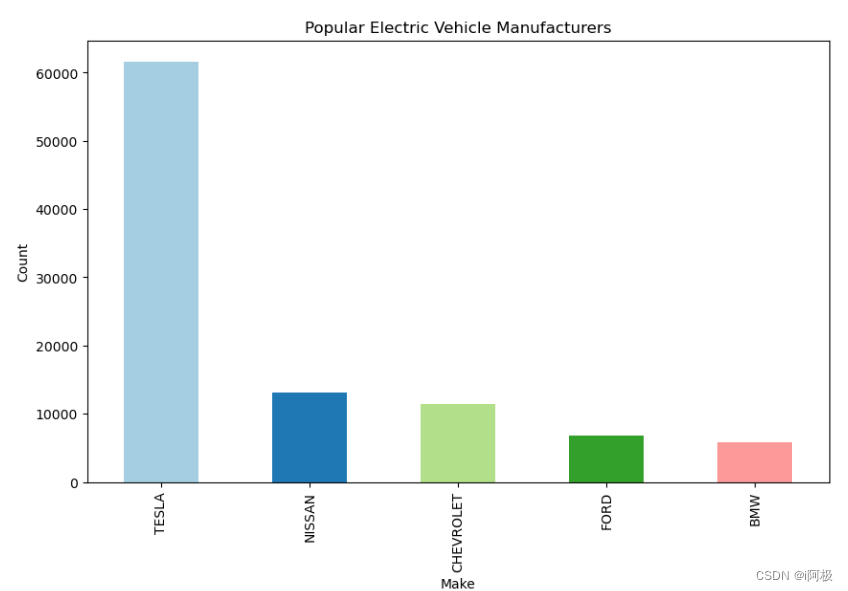
5、前5最欢迎的电动车制造商
popular_makes = data["Make"].value_counts().head(5)
plt.figure(figsize=(10, 6))
popular_makes.plot(kind='bar', color=colors)
plt.xlabel("Make")
plt.ylabel("Count")
plt.title("Popular Electric Vehicle Manufacturers")
plt.show()
#结果:
#TESLA 61650
#NISSAN 13138
#CHEVROLET 11417
#FORD 6876
#BMW 5881
此代码创建一个条形图,显示受欢迎制造商的电动汽车数量。显示图表时,x轴标记为“Make”表示制造商,y轴标记为为“Count”表示车辆数量。图表的标题是“受欢迎的电动汽车制造商”
运行结果如下:
6、XGBoost模型
使用XGBoost和数据预处理的电动汽车类型预测此代码使用XGBooster算法基于给定特征执行电动汽车类型的预测。该代码包括数据预处理步骤,如识别字符串列、删除不相关列、编码分类变量和一次热编码。然后,它将数据拆分为训练集和测试集,为XGBoost创建DMatrix对象,定义XGBoost模型参数,训练模型,并对测试数据进行预测。最后,它计算了模型预测的准确性。
6.1 字符串列的标识
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.metrics import accuracy_scorestring_columns = data.select_dtypes(include=['object']).columns
print("Colonnes contenant des chaînes de caractères :")
for column in string_columns:print(column)
运行结果如下:

6.2 删除不相关的列
columns_to_drop = ['County', 'Electric Utility']
data = data.drop(columns_to_drop, axis=1)
6.3 编码分类变量
label_encoder = LabelEncoder()
categorical_columns = ['City', 'State', 'Make', 'Model', 'Electric Vehicle Type']
for column in categorical_columns:data[column] = label_encoder.fit_transform(data[column])
6.4 电动车类型热编码
one_hot_encoded = pd.get_dummies(data['Electric Vehicle Type'], prefix='EVType')
data = pd.concat([data, one_hot_encoded], axis=1)
print(data.head())
6.5 将数据划分训练集和测试集
features = ['Model Year', 'Make', 'Model']
target = 'Electric Vehicle Type'
train_data, test_data, train_target, test_target = train_test_split(data[features], data[target], test_size=0.2, random_state=42)
6.6 为训练集和测试集创建DMatrix
此代码使用xgb为训练和测试数据创建DMatrix对象。XGBoost库中的DMatrix函数。它使用训练数据(train_data)及其相应的目标(train_target)来创建dtrain。类似地,它使用测试数据(test_data)及其目标(test_target)创建dtest。DMatrix是XGBoost用于高效训练和预测的数据结构。
dtrain = xgb.DMatrix(train_data, label=train_target)
dtest = xgb.DMatrix(test_data, label=test_target)
6.7 XGBoot模型
params = {'objective': 'multi:softmax','num_class': len(data[target].unique()), 'eta': 0.1,'max_depth': 6,'min_child_weight': 1,'gamma': 0.1,'subsample': 0.8,'colsample_bytree': 0.8,'eval_metric': 'merror'
}
model = xgb.train(params, dtrain, num_boost_round=100)
6.8 预测和计算准确值
predictions = model.predict(dtest)
predictions = [int(round(pred)) for pred in predictions]
accuracy = accuracy_score(test_target, predictions)
print("Exactitude : {:.2f}%".format(accuracy * 100))
运行结果如下:
Exactitude : 99.00%
ps:这是部分代码
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗
这篇关于基于XGBoost和数据预处理的电动汽车车型预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






