本文主要是介绍R语言随机抽取数据,并作两组数据间t检验,并保存抽取的数据,并绘制boxplot,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前提:接着上述R脚本输出的seed结果来选择应该使用哪个seed比较合理,上个R脚本名字:
“5utr_计算ABD中Ge1和Lt1的个数和均值以及按照TE个数小的进行随机100次抽样.R”
1.输入数据:“5utr-5d做ABD中有RG4和没有RG4的TE之间的T检验.csv”
2.代码:“5utr_5d_ABD中有RG4和无RG4的TE之间的T检验函数+保存符合要求的seed+保存符合要求的数据框+绘制boxplot.R”
setwd("E:\\R\\Rscripts\\5UTR_extended_TE")
# 载入必要的库
library(tidyverse)
library(dplyr)
library(openxlsx)# 读取数据
data <- read.csv("5utr-5d做ABD中有RG4和没有RG4的TE之间的T检验.csv", na.strings = "#N/A")# 将所有的NA值转换为0
data <- data %>% mutate_all(~ifelse(is.na(.), 0, .))############################################################
# 调整后的process_scores函数1,适用于le1的个数小于ge1的个数且ave-le1大于ave-ge1的情况
############################################################process_scores <- function(df, score_name, TE_name) {successful_seeds <- list() # 初始化一个列表来保存成功的seed值combined_samples_list <- list() # 新增:初始化一个列表来保存符合条件的组合数据框for (seed_val in 1) {set.seed(seed_val)ge1 <- df %>% filter(!!sym(score_name) >= 1) %>% select(!!sym(TE_name)) %>% mutate(Source = "ge1")le1 <- df %>% filter(!!sym(score_name) < 1) %>% select(!!sym(TE_name)) %>% mutate(Source = "sample_le1")sample_le1 <- sample_n(le1, nrow(ge1)) # 取单一样本进行比较t_test <- t.test(ge1[[1]], sample_le1[[1]])mean1 <- mean(ge1[[1]])mean2 <- mean(sample_le1[[1]])if (mean2 < mean1 && t_test$p.value <= 0.09) {successful_seeds[[paste0(seed_val, "_", score_name)]] <- list(seed = seed_val,mean1 = mean1,mean2 = mean2,pvalue = t_test$p.value)# 新增:将符合条件的ge1和sample_le1合并到一个数据框中,并保存到列表中combined_samples <- bind_rows(ge1, sample_le1)combined_samples_list[[paste0(seed_val, "_", score_name)]] <- combined_samples}}# 将成功的seeds信息转换为数据框if (length(successful_seeds) > 0) {successful_seeds_df <- bind_rows(successful_seeds, .id = "seed_score") %>% mutate(Comparison = seed_score)} else {successful_seeds_df <- tibble(Comparison = character(), mean1 = numeric(), mean2 = numeric(), pvalue = numeric())}# 新增:将combined_samples_list中的数据框合并或以其他形式输出combined_samples_output <- if (length(combined_samples_list) > 0) {# 例如,这里我们简单地将所有符合条件的数据框合并bind_rows(combined_samples_list)} else {# 如果没有符合条件的,则返回空数据框tibble()}return(list(successful_seeds = successful_seeds_df, combined_samples = combined_samples_output))
}# 对AScore5d进行处理示例
results_AScore5d <- process_scores(data, "AScore5d", "ATe5d")
results_BScore5d <- process_scores(data, "BScore5d", "BTe5d")
results_DScore5d <- process_scores(data, "DScore5d", "DTe5d")
# 打印出符合条件的successful_seeds结果进行检查
bind_results_AScore5d_successful_seeds<-rbind(results_AScore5d$successful_seeds,results_BScore5d$successful_seeds,results_DScore5d$successful_seeds)
write.xlsx(bind_results_AScore5d_successful_seeds, file = "5utr_bind_results_ABDScore5d_successful_seeds_seed1.xlsx")# 将符合条件的组合数据框写入文件
write.table(results_AScore5d$combined_samples, "combined_samples_seed1_5utr5dAScored.csv", quote = FALSE, row.names = FALSE, sep = ",")
write.table(results_BScore5d$combined_samples, "combined_samples_seed1_5utr5dBScored.csv", quote = FALSE, row.names = FALSE, sep = ",")
write.table(results_DScore5d$combined_samples, "combined_samples_seed1_5utr5dDScored.csv", quote = FALSE, row.names = FALSE, sep = ",")####################################################################
##
##
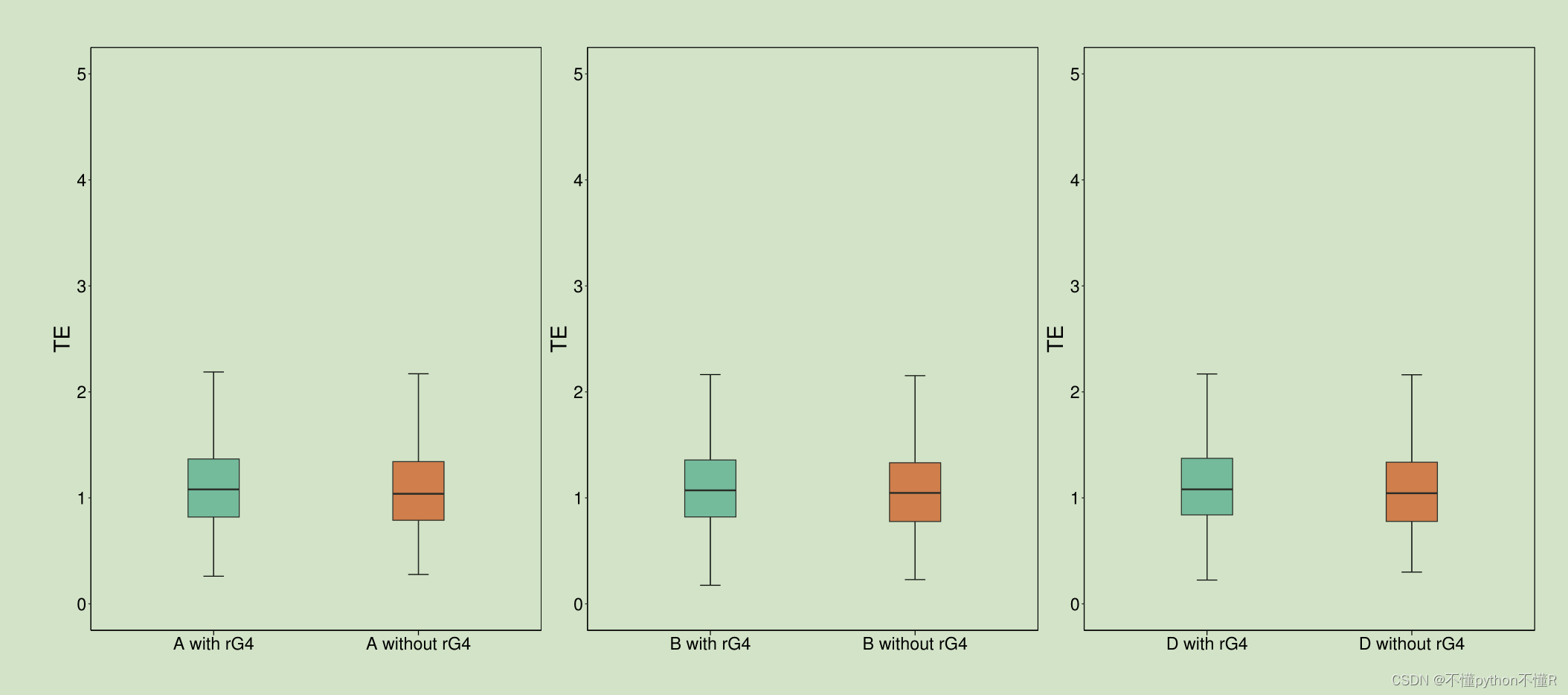
#接着上面的结果绘制boxplot
##
##
####################################################################
library(tidyverse)
library(ggplot2)
library(patchwork)results_AScore5d$combined_samples$Source<-factor(results_AScore5d$combined_samples$Source,levels=c("ge1","sample_le1"),labels=c("A with rG4","A without rG4"),ordered=TRUE)
p1<-ggplot(results_AScore5d$combined_samples, aes(x=Source,y=ATe5d,fill=Source))+#根据Type进行填充,fill=Typestat_boxplot(geom = "errorbar",width=0.1)+ #添加误差线geom_boxplot(outlier.size = -1,width=0.25)+theme_classic()+#背景设置为白色scale_fill_manual(values = c( "#8DD3C7", "#FC8D62"))+labs(y="TE")+scale_y_continuous(limits = c(0,5),breaks=seq(0,5,1))+theme(strip.background = element_rect(colour="black", fill="#FFFFFF"),plot.title=element_text (hjust = 0.5,vjust =1,lineheight=1,color="black"),panel.background=element_rect(fill="white",colour="black",linewidth =0.5),axis.title.y=element_text(size=25,face="plain",color="black"),axis.title.x=element_blank(),axis.text = element_text(size=20,face="plain",color="black"),#axis.tex用来调整描述x轴的文本,比如图中的conserved等panel.border = element_blank(),panel.grid.major = element_blank(),panel.grid.minor = element_blank(),axis.ticks.x=element_line(colour="black"),axis.ticks.length.x=grid::unit(0.2, "cm"))+guides(fill="none")results_BScore5d$combined_samples$Source<-factor(results_BScore5d$combined_samples$Source,levels=c("ge1","sample_le1"),labels=c("B with rG4","B without rG4"),ordered=TRUE)
p2<-ggplot(results_BScore5d$combined_samples, aes(x=Source,y=BTe5d,fill=Source))+#根据Type进行填充,fill=Typestat_boxplot(geom = "errorbar",width=0.1)+ #添加误差线geom_boxplot(outlier.size = -1,width=0.25)+theme_classic()+#背景设置为白色scale_fill_manual(values = c( "#8DD3C7", "#FC8D62"))+labs(y="TE")+scale_y_continuous(limits = c(0,5),breaks=seq(0,5,1))+theme(strip.background = element_rect(colour="black", fill="#FFFFFF"),plot.title=element_text (hjust = 0.5,vjust =1,lineheight=1,color="black"),panel.background=element_rect(fill="white",colour="black",linewidth =0.5),axis.title.y=element_text(size=25,face="plain",color="black"),axis.title.x=element_blank(),axis.text = element_text(size=20,face="plain",color="black"),#axis.tex用来调整描述x轴的文本,比如图中的conserved等panel.border = element_blank(),panel.grid.major = element_blank(),panel.grid.minor = element_blank(),axis.ticks.x=element_line(colour="black"),axis.ticks.length.x=grid::unit(0.2, "cm"))+guides(fill="none")results_DScore5d$combined_samples$Source<-factor(results_DScore5d$combined_samples$Source,levels=c("ge1","sample_le1"),labels=c("D with rG4","D without rG4"),ordered=TRUE)
p3<-ggplot(results_DScore5d$combined_samples, aes(x=Source,y=DTe5d,fill=Source))+#根据Type进行填充,fill=Typestat_boxplot(geom = "errorbar",width=0.1)+ #添加误差线geom_boxplot(outlier.size = -1,width=0.25)+theme_classic()+#背景设置为白色scale_fill_manual(values = c( "#8DD3C7", "#FC8D62"))+labs(y="TE")+scale_y_continuous(limits = c(0,5),breaks=seq(0,5,1))+theme(strip.background = element_rect(colour="black", fill="#FFFFFF"),plot.title=element_text (hjust = 0.5,vjust =1,lineheight=1,color="black"),panel.background=element_rect(fill="white",colour="black",linewidth =0.5),axis.title.y=element_text(size=25,face="plain",color="black"),axis.title.x=element_blank(),axis.text = element_text(size=20,face="plain",color="black"),#axis.tex用来调整描述x轴的文本,比如图中的conserved等panel.border = element_blank(),panel.grid.major = element_blank(),panel.grid.minor = element_blank(),axis.ticks.x=element_line(colour="black"),axis.ticks.length.x=grid::unit(0.2, "cm"))+guides(fill="none")
p4<-p1+p2+p3+plot_layout(widths = c(1,1,1))
ggsave("boxplot-5utr-5d做ABD中有RG4和没有RG4的TE之间的T检验.pdf",plot=p4,width=24,height=10)
3.输出数据:“5utr_bind_results_ABDScore5d_successful_seeds_seed1.xlsx”

4.输出boxplot:“boxplot-5utr-5d做ABD中有RG4和没有RG4的TE之间的T检验.pdf”
这篇关于R语言随机抽取数据,并作两组数据间t检验,并保存抽取的数据,并绘制boxplot的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







