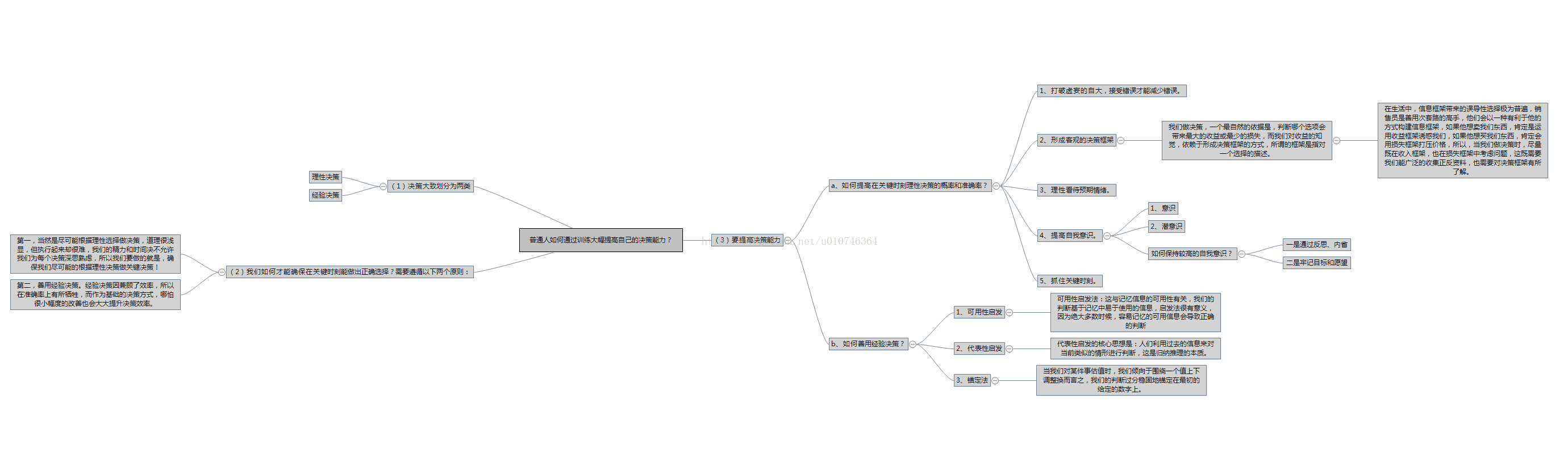
本文主要是介绍普通人如何通过训练大幅提高自己的决策能力?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(转载)https://www.zhihu.com/question/49602855/answer/117017609
作者:高太爷
链接:https://www.zhihu.com/question/49602855/answer/117017609
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/49602855/answer/117017609
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
这篇关于普通人如何通过训练大幅提高自己的决策能力?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








