本文主要是介绍【计算机图形学】Universal Manipulation Policy Network for Articulated Objects,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对Universal Manipulation Policy Network for Articulated Objects的简单理解
1. 做了什么事
UMPNet是一个基于图像的策略网络,能够推理用于操纵铰接物体的动作序列。该策略支持6DoF动作表示和可变长度轨迹。
为handle多种类的物体,该策略从不同的铰接结构中学习,并泛化到未见过的物体或类别上。该策略是以自监督探索的方式进行学习的,无需任何注释、脚本或预定义的目标。
为了支持多步交互,引入了一个新的Arrow-of-Time动作属性,用以指示某个动作是否会使得物体状态倒退(到过去的状态)或前进(到未来的状态)。通过在每一个交互步中使用这个Arrow-of-Time推理,学习到的策略能够选择朝向/远离给定的状态,实现高效的状态探索和基于目标的操纵。
这应该比VAT-MART还要早,因为是基于目标的,所以相对于Where2Act的改进就是可以生成动作轨迹,而不是单一的动作执行朝向。
2. 方法
操纵策略 π \pi π的目标是生成与随机铰接物体交互的动作序列,得到未见过的新状态。
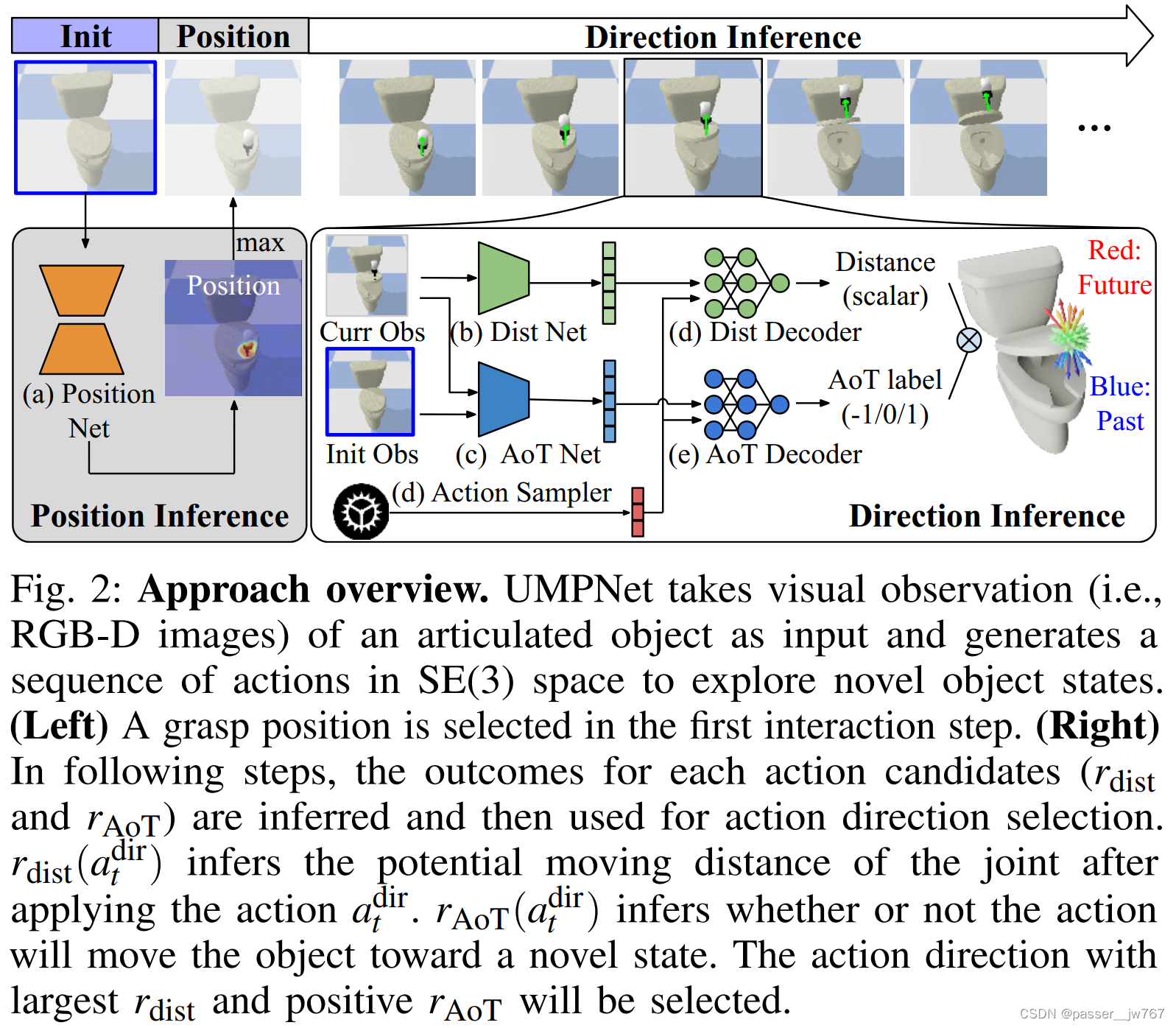
以图2为例,为了高效探索物体(马桶为例)的新状态,算法如下:
-
选择物体上正确的位置进行交互(即,与马桶盖交互而不是基);
-
选择正确的动作方向(即,拉起来,而不是向下推);
-
在接下来的动作中选择一致的动作,以探索新的状态(即,保持向上拉盖子,而不是上下移动盖子);
这三个需求对应算法中的3个关键部分:(1)运动位置选择;(2)运动距离;(3)Arrow-of-Time推理用于动作方向选择。
结合这三个部分,最后的系统能够通过自引导的探索过程来学习,而不需要显式的人类注释、脚本策略或预定义的目标情况。
2.1 问题定义
输入是处于当前状态 o 0 o_0 o0的一张RGBD图像 o 0 ∈ R W × H × 4 o_0∈\R^{W×H×4} o0∈RW×H×4,智能体通过策略 π \pi π生成每一步的动作 a t a_t at: π ( o t , o 0 ) → a t \pi(o_t,o_0)→a_t π(ot,o0)→at。该动作是在 S E ( 3 ) SE(3) SE(3)空间中表示的,参数化为end-effector位置(吸式夹持器)和移动方向: a t = ( a t p o s , a t d i r ) a_t=(a^{pos}_t,a^{dir}_t) at=(atpos,atdir), a t p o s ∈ R 3 a^{pos}_t∈\R^3 atpos∈R3是一个3D坐标, a t d i r ∈ R 3 , ( ∣ ∣ a t d i r ∣ ∣ = 1 ) a^{dir}_t∈\R^3,(||a^{dir}_t||=1) atdir∈R3,(∣∣atdir∣∣=1)是一个单位向量,用于指示end-effector的移动方向。
在第一个交互步骤,策略选择一个3D位置 a 0 p o s a^{pos}_0 a0pos以应用动作。为了执行动作,智能体移动它的end-effector到这个位置,方向垂直于物体表面。注意,gripper方向(由表面法线确定)可以不同于动作方向 a t d i r a^{dir}_t atdir(这个动作方向由方向推理网络确定)。
在接下来的步骤中,智能体选择3D方向 a t d i r a^{dir}_t atdir并沿着方向移动0.18(m),位置相对于物体表面固定。吸力是吸盘和选定物体位置之间的力约束。end-effector的方向在交互过程中总是与表面法线对齐。
2.2 位置推理
开始的时候,策略需要选择一个3D位置 a 0 p o s a^{pos}_0 a0pos应用动作。为了找到这个为止,算法需要去从观察图像 o 0 o_0 o0中选择一个像素,并应用动作。选择的像素将被使用深度值投影至3D空间中。
这个问题以给图像打标签的方式进行处理,位置网络(如图2a)的输入是RGB-D图像,预测逐像素的position affordance score P ∈ [ 0 , 1 ] W × H P∈[0,1]^{W×H} P∈[0,1]W×H。Affordance分数 P ( w , h ) P(w,h) P(w,h)表示在该位置上应用动作时,物体的移动概率。位置网络通过执行动作的输出进行监督。当且仅当物体对象在未来任何步骤中改变时,GT标签为1,使用二分类交叉熵损失训练。
但还需要注意,如果选择了那些接近于axis的位置,无法应用足够的力来移动物体部件。此外,这个标签还受到方向选择的质量影响,若预测了错误的方向,则物体的状态不会发生改变,则会标记为负例。
2.3 方向推理
给定抓取点 a 0 p o s a^{pos}_0 a0pos的信息,基于这个条件,策略需要选择3D方向 a t d i r a^{dir}_t atdir。为了选择动作方向,算法需要采样一组动作候选,评估每个动作候选的效率,“效率”指的是物体关节位置的移动距离 r d i s t ( a t d i r ) r_{dist}(a_t^{dir}) rdist(atdir)和Arrow-of-Time属性 r A o T ( a t d i r ) r_{AoT}(a^{dir}_t) rAoT(atdir),如下定义:
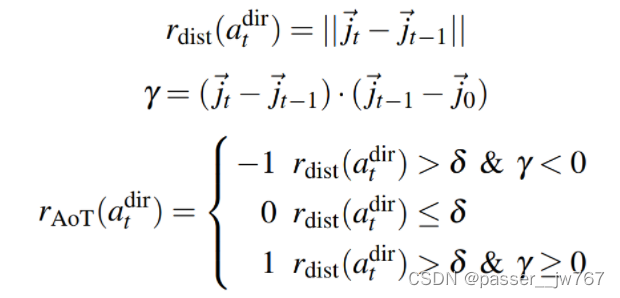
其中, j t ⃗ \vec{j_t} jt指的是在每一步 t t t时的物体关节状态, δ δ δ是确定状态是否发生高效改变的阈值。第一个式子表示该阶段状态和上一阶段状态的差异,第二个式子确定是否 j t ⃗ \vec{j_t} jt是朝向未来状态的,而不是回到过去的状态。
为生成候选状态 a ^ d i r {\hat{a}^{dir}} a^dir,一个简单的方法是在 S O ( 3 ) SO(3) SO(3)空间中均匀采样。受限于采样数量,采样方向只能覆盖不包括最优方向的连续动作空间的一小部分。为解决这个问题引入启发式的方法,迭代交叉熵方法(CEM, Cross-Entropy Method),减轻采样空间以获得高效率方向采样。
这个算法首先在 S O ( 3 ) SO(3) SO(3)空间中均匀采样 N N N个样例。接着基于预测的动作分数评估采样动作: s ( a ^ ) = r ~ d i s t ( a ^ d i r ) ⋅ r ~ A o T ( a ^ d i r ) s(\hat{a})=\widetilde{r}_{dist}(\hat{a}^{dir})·\widetilde{r}_{AoT}(\hat{a}^{dir}) s(a^)=r dist(a^dir)⋅r AoT(a^dir)。在下一个迭代过程中,算法重新采样与分数相关的候选: p ( a ^ ) ∝ e T ∗ s ( a ^ ) p(\hat{a})∝e^{T*s(\hat{a})} p(a^)∝eT∗s(a^)( ∝ ∝ ∝表示A与B成正比例), T = 20 T=20 T=20是一个临时量(我理解因为指数函数是恒大于0的,通过AoT可以筛除掉那些=0或<0的不合理动作方向,从而对那些正确的方向进行重新采样)。添加了随机噪声(添加随机噪声的目的应该是获得与第一次交互存在差异的交互行为),它们被认为是第二次交互的候选。通过这种方法,第二次迭代采样的样本将更多集中在具有“潜力”的区域,使得同样的采样数量下,获得更好的表现。
为了推理动作候选的移动距离 r ~ d i s t ( a ^ d i r ) \widetilde{r}_{dist}(\hat{a}^{dir}) r dist(a^dir),网络需要考虑物体当前状态和抓取位置,二者被编码在当前的观测 o t o_t ot中。当前状态的RGB-D图像作为输入,DistNet输出embedding向量 ψ ( o t ) ψ(o_t) ψ(ot)。接着DistDecoder将 ψ ( o t ) ψ(o_t) ψ(ot)和动作 a a a作为输入,输出一个标量作为距离预测 r ~ d i s t ( a ^ d i r ) \widetilde{r}_{dist}(\hat{a}^{dir}) r dist(a^dir)。DistNet是一个卷积神经网络,将输出展开为一个embedding向量。Dist-Decoder是一个全连接神经网络,使用MSE损失 L d i s t L_{dist} Ldist进行训练。
与 r ~ d i s t ( a ^ d i r ) \widetilde{r}_{dist}(\hat{a}^{dir}) r dist(a^dir)不同,Arrow-of-Time r ~ A o T ( a ^ d i r ) \widetilde{r}_{AoT}(\hat{a}^{dir}) r AoT(a^dir)的推理基于当前视觉状态和初始视觉状态。在单步交互中,任何动作都会改变物体的状态,使得物体进入一个新的状态。但对于多步交互来说并不是这样的,策略可以移动物体向前向后,而不探索更多新的状态,为了解决这个问题引入了Arrow-of-Time(AoT),用于指示物体究竟是返回了初始状态还是朝向了未来的状态。通过AoT将当前和初始的观察作为输入,输出另外一个embedding向量 φ ( o t , o 0 ) φ(o_t,o_0) φ(ot,o0)。该embedding连接动作embedding来推理最终的 A o T AoT AoT标签 r ~ A o T ( a ^ d i r ) \widetilde{r}_{AoT}(\hat{a}^{dir}) r AoT(a^dir)。AoT网络结构和Dist的类似,只是输入输出维度有差异。模型使用交叉熵损失训练。 L = λ L d i s t + L A O T L=\lambda L_{dist}+L_{AOT} L=λLdist+LAOT。
2.4 训练
所有数据来自从头开始的策略训练进行的交互尝试。使用FIFO replay buffer来存储训练数据。为了搜集正例和负例,在一个序列内的方向上应用矛盾的策略用于方向推理(没有特别理解)。在每个序列的前半部分,选择那些具有正AoT的预测进行执行,使物体远离初始状态;在后半部分,执行那些具有负AoT的预测,鼓励物体向回执行。每个epoch搜集16个策略。序列长度一开始是4,在1000 epochs后,每400个epochs增长2,直到到达20为止。
位置模块和方向模块在每个epoch训练8个迭代。对于每一轮位置训练,从replay buffer中采样一个batch(大小=16),其中具有1:1的正负比率。对于方向迭代,一个batch中正、负、不移动数据比率为1:1:1。
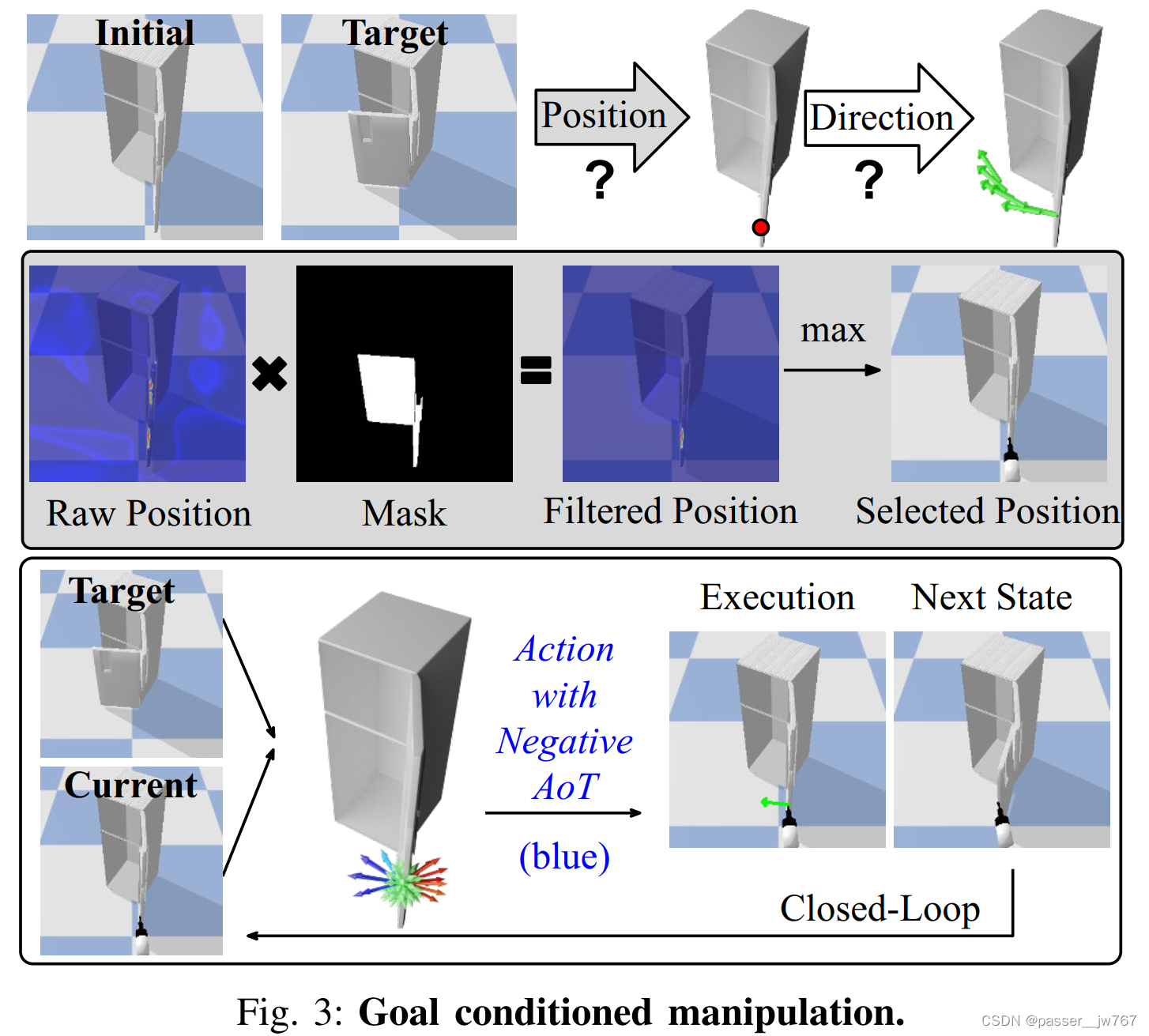
2.5 使用逆AoT进行的以目标为条件的操纵
大部分操纵任务都是都是基于目标的,这就需要能够生成一些策略,使得这些策略能够在给定随机目标状态的情况下,生成朝向这一目标的动作。(注意,需要给定目标状态)。尽管文章策略是在开-关的探索下进行训练,但学习到的策略仍然可以直接在无需额外训练的情况下,直接应用到基于目标的动作生成上。
核心想法就是交换输入时的初始obs和目标状态obs,然后作为策略生成的输入,通过执行逆AoT的动作,策略尝试去将物体移动回“过去”,从而高效地实现目标。如果AoT所有方向的预测都是非负的,则策略停止。
除了选择正确的动作方向,另一个问题是基于目标的操纵需要选择正确的部件进行操纵,因为有时候物体上可能会有很多个可操纵部件(如冰箱有两个门)
这篇关于【计算机图形学】Universal Manipulation Policy Network for Articulated Objects的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!