本文主要是介绍Wireshark TS | DNS 案例分析之外的思考,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
承接之前一篇《Packet Challenge 之 DNS 案例分析》,在数据包跟踪文件 dnsing.pcapng 中,关于第 4 题(What is the largest DNS response time seen in this trace file? )的分析过程中曾经碰到一个小问题,主要是数据包中存在部分 DNS 查询数据包重传的现象,因此对于 DNS 响应时间的计算可能就有一点不同的见解。
问题
譬如 No.1-4 数据包,No.1 为起始 DNS 查询,No.2 为 DNS 查询的第一次重传,No.3 为 DNS 查询的第二次重传,No.4 为 DNS 响应,那么 DNS 响应时间是 No.4 和 No.1 的差值?还是 No.4 和 No.3 的差值?
关于上述问题的场景,实际上类似 TCP 超时重传中关于 RTO、RTT 如何选取的问题,如下图。
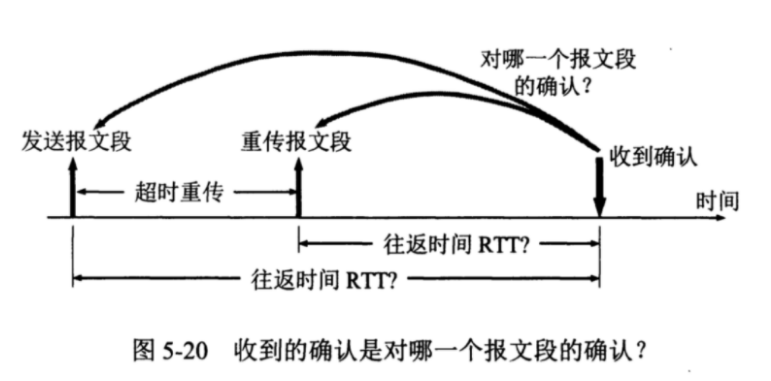
重传时间的选择是 TCP 最复杂的问题之一,本篇不再展开。
而对于像 dns.time,http.time 等这些关乎应用性能指标的字段值,倒是没有那么讲究。在 Wireshark 中这样的类似字段,以 [ ] 标注的,实际上并不是数据包本身的实际字段。对比数据包 DNS 响应中的 Transaction ID、Flags 等真实字段,可以看到如下:
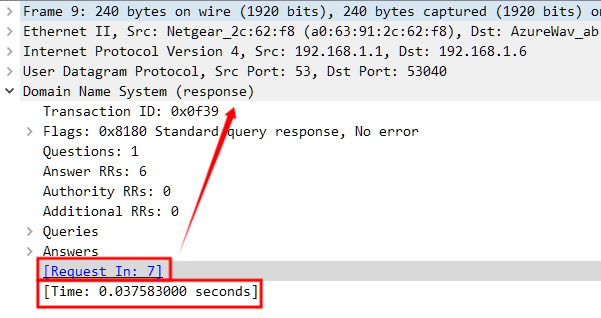
[Request In: 7]Wireshark 根据上下文提示该 DNS 响应数据包所对应的请求在 No.7 数据包;[Time:0.037583000 seconds]Wireshark 根据上下文计算出该 DNS 响应数据包和请求数据包之间的时间间隔为 0.037583000 秒。
分析
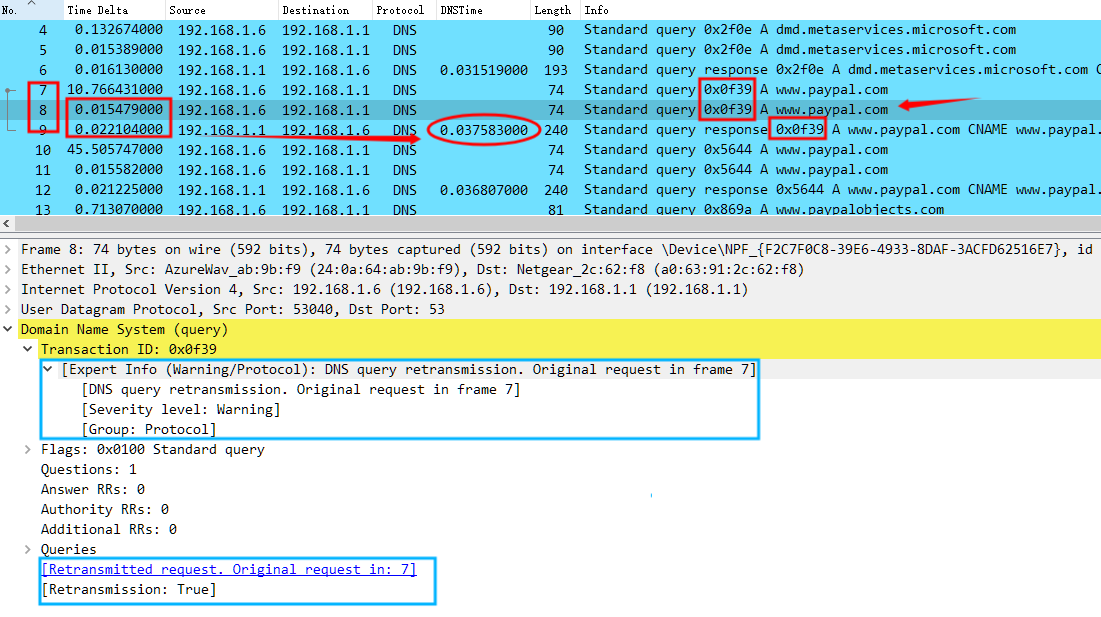
再回到 DNS 这个案例上,Wireshark 根据 Transaction ID 值 0x0f39 对应出 No.7-9 为一组 DNS 请求和响应,其中 No.7 为第一次查询,No.8 为第二次查询(也就是重传,Wireshark 会标记提示为 DNS 查询重传,原始请求在 No.7),No.9 为查询响应。
Wireshark 对于 dns.time的取值是 0.037583000 秒,这个是 No.9 和 No.7 的时间间隔,也就是 0.015479000 加上 0.022104000 的结果,因此 Wireshark dns.time 的算法是第一次查询以及响应数据包之间的间隔时间。
其次根据显示过滤表达式,可过滤出和域名相关的所有 DNS 请求和响应,如下。
dns.qry.name == "www.paypal.com"
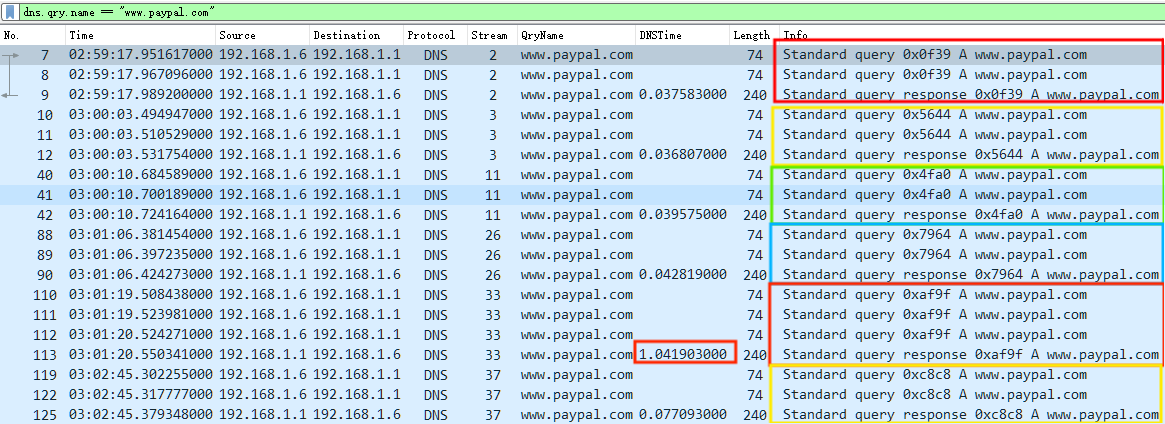
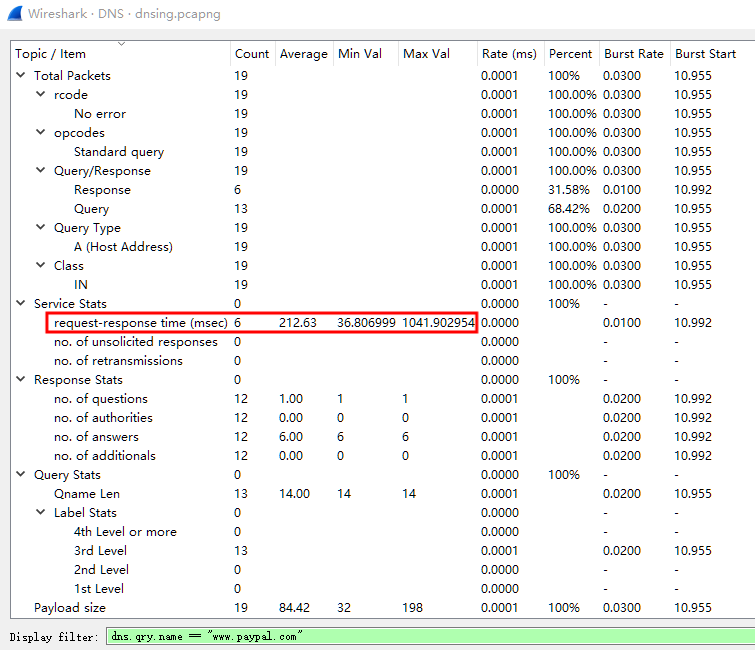
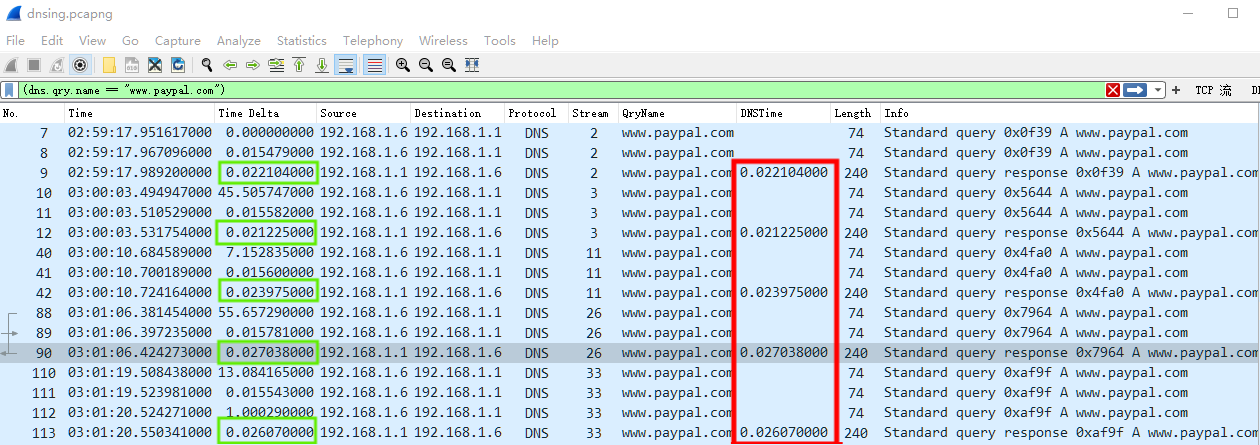
包括 6 次完整请求和响应,且每次均有重传请求,其中第 5 次还包含有两次请求重传,因此 dns.time 时间较长,超过了 1 秒。
在 Statistics -> DNS 中,也可以看到相关请求-响应时间,最小 36.8ms 至最长 1041.9ms,平均 212.63ms。
通过 tshark 也可以输出相关 dns 字段值。
λ tshark -r dnsing.pcapng -Y 'dns.qry.name == "www.paypal.com"' -T fields -e frame.number -e dns.id -e dns.flags.response -e dns.time
7 0x0f39 0
8 0x0f39 0
9 0x0f39 1 0.037583000
10 0x5644 0
11 0x5644 0
12 0x5644 1 0.036807000
40 0x4fa0 0
41 0x4fa0 0
42 0x4fa0 1 0.039575000
88 0x7964 0
89 0x7964 0
90 0x7964 1 0.042819000
110 0xaf9f 0
111 0xaf9f 0
112 0xaf9f 0
113 0xaf9f 1 1.041903000
119 0xc8c8 0
122 0xc8c8 0
125 0xc8c8 1 0.077093000
深入
实际上,对于 DNS 请求和响应的关联,我更愿理解是最后一次 DNS 重传请求和响应之间是对应关系,这样所计算出来的 dns.time 会更小,理论上应该也更精确。
因此对于 DNS Transaction ID 值 0x0f39 的一组,计算 No.8 和 No.9 的间隔时间,也就是 dns.time 的值 22ms。

以上都是手工计算,那么对于整个数据包跟踪文件中,存在很多 DNS 请求响应对的,如何得出所有的 dns.time,可通过如下方式输出相关过滤后的数据包。
tshark -r dnsing.pcapng -w test1.pcapng -Y `tshark -r dnsing.pcapng -Y 'dns.qry.name == "www.paypal.com"' -T fields -e frame.number -e dns.id -e dns.flags.response | sort -rn | uniq -f 1 | sort -n | awk '{printf("%sframe.number==%d",sep,$1);sep="||"}'`
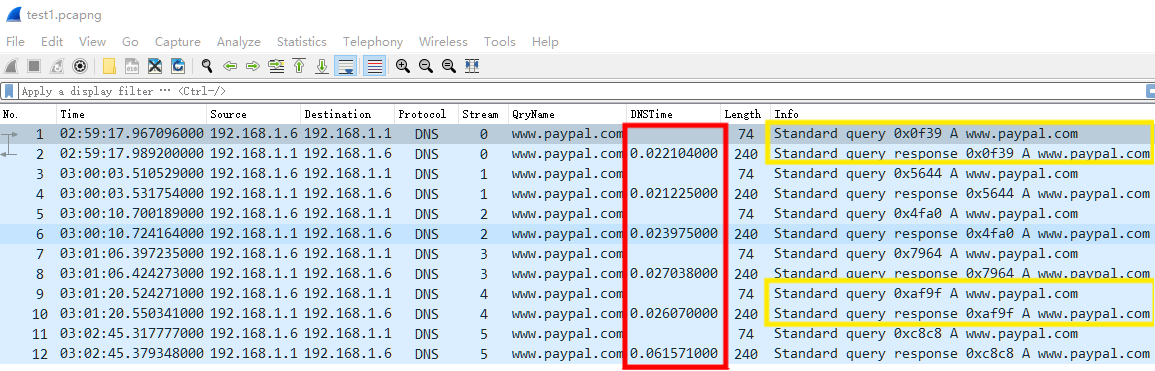
通过 tshark 也可以输出相关 dns 字段值。
λ tshark -r test1.pcapng -T fields -e frame.number -e dns.id -e dns.flags.response -e dns.time
1 0x0f39 0
2 0x0f39 1 0.022104000
3 0x5644 0
4 0x5644 1 0.021225000
5 0x4fa0 0
6 0x4fa0 1 0.023975000
7 0x7964 0
8 0x7964 1 0.027038000
9 0xaf9f 0
10 0xaf9f 1 0.026070000
11 0xc8c8 0
12 0xc8c8 1 0.061571000
进阶
在上述分析章节中说到,Wireshark dns.time 的算法是第一次查询以及响应数据包之间的间隔时间,也就是说默认没有考虑有重传请求的存在。
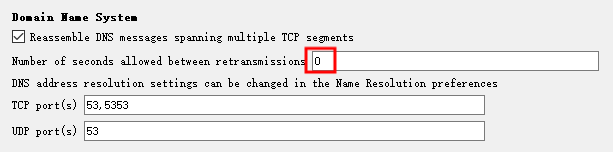
但终究 Wireshark 还是考虑到了这样的场景,在 Perferences -> Protocols -> DNS 中,有如下的选项可以使用:
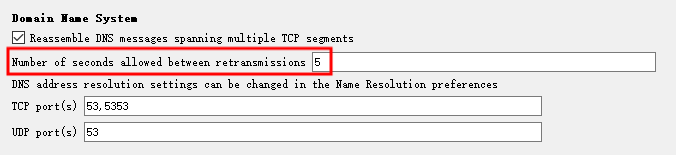
也就是说重传之间允许的秒数,该选项默认是 5s,也就是 5s 以内的相同请求,都算成是重传请求,而如果全是重传请求的话,则 dns.time 就是第一次查询以及响应数据包之间的间隔时间。
如下,默认 5s 的情况,No.112 在 2s 之内,所以仍是重传请求,dns.time 值 No.113 和 No.110 的间隔时间为 1.041s。
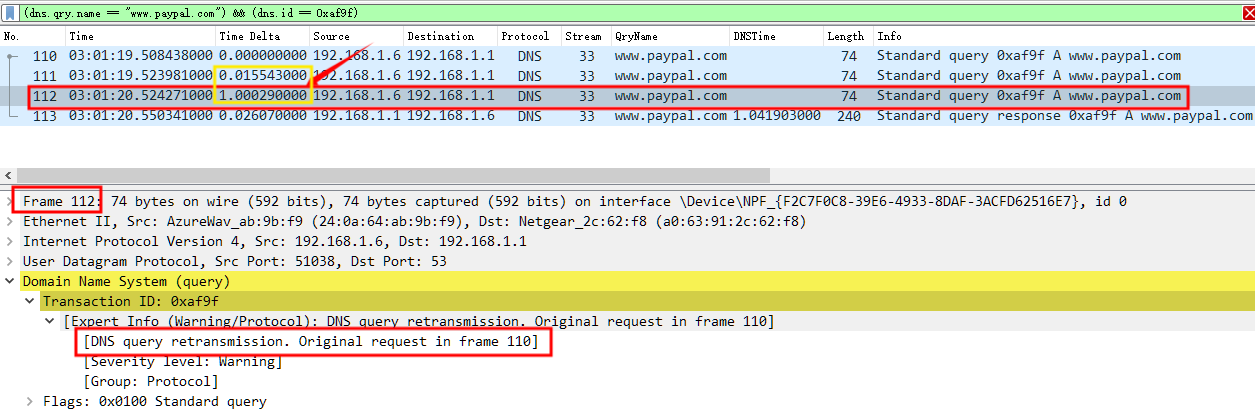
如果选项 Number of seconds allowed between retransmissions 值改为 1s 呢,那么结果如下,No.112 在 1s 之外,所以不再是重传请求,因此 dns.time 值就变成 No.113 和 No.112 的间隔时间为 0.026s。
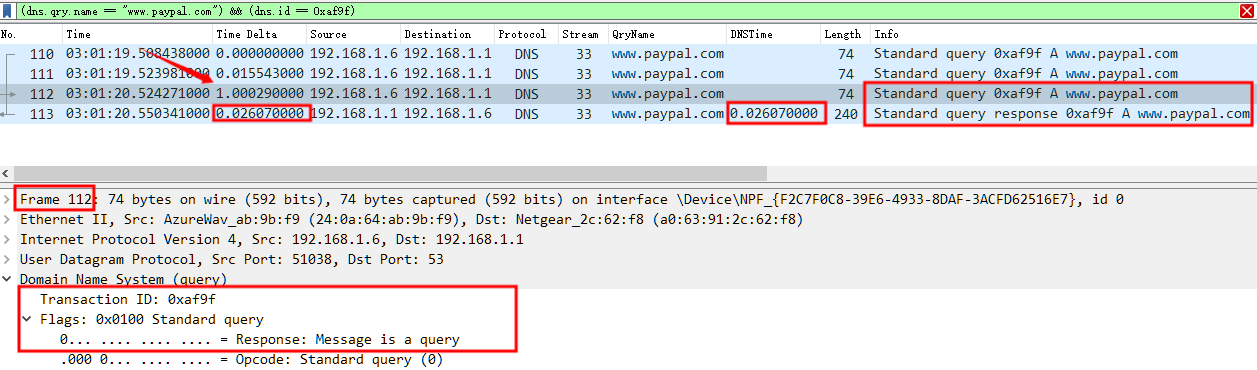
那么再如果选项 Number of seconds allowed between retransmissions 值改为 0 呢,那么结果如下,自然也就不存在所谓的重传请求,这样也就直接达到了深入章节中的脚本效果。
总结
以上就是在之前 DNS 案例分析中延伸出来的一点思考,选项 Number of seconds allowed between retransmissions 供参考使用。
这篇关于Wireshark TS | DNS 案例分析之外的思考的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





