本文主要是介绍【CS231n】斯坦福大学李飞飞视觉识别课程笔记(一):Python Numpy教程(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近开了一个新坑——【CS231n】斯坦福大学李飞飞视觉识别课程,准备认真学习并记录自己的学习历程。
【CS231n】斯坦福大学李飞飞视觉识别课程笔记
由官方授权的CS231n课程笔记翻译知乎专栏——智能单元,比较详细地翻译了课程笔记,我这里就是参考和总结。

【CS231n】斯坦福大学李飞飞视觉识别课程笔记(一):Python Numpy教程
这个课程将使用Python编程语言来完成课程的所有作业。Python是一门伟大的通用编程语言,在一些常用库(numpy, scipy, matplotlib)的帮助下,它又会变成一个强大的科学计算环境。
对于没有Python经验的同学,这篇教程可以帮助你们快速了解Python编程环境和如何使用Python作为科学计算工具。
Python
Python是一种高级的,动态类型的多范型编程语言。很多时候,大家会说Python看起来简直和伪代码一样,这是因为你能够通过很少行数的代码表达出很有力的思想。举个例子,下面是用Python实现的经典的quicksort算法例子:
def quicksort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quicksort(left) + middle + quicksort(right)print(quicksort([3,6,8,10,1,2,1]))
# Prints "[1, 1, 2, 3, 6, 8, 10]"
解析:
arr = [3,6,8,10,1,2,1]
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
print('left:',left)
print('middle:',middle)
print('right:',right)
> left: [3, 6, 8, 1, 2, 1]
> middle: [10]
> right: []
Python版本
目前有两种不同的Python支持版本,2.7和3.5。有点令人困惑的是,Python 3.0对该语言引入了许多向后不兼容的更改,因此为2.7编写的代码在3.5以下可能无法工作,反之亦然。对于这个类,所有代码都将使用Python 3.5。
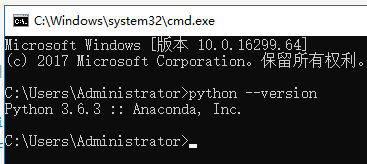
如何查看版本呢?使用python --version命令。
基本数据类型
和大多数编程语言一样,Python拥有一系列的基本数据类型,比如整型、浮点型、布尔型和字符串等。这些类型的使用方式和在其他语言中的使用方式是类似的。
数字:整型和浮点型的使用与其他语言类似。
x = 3
print(type(x)) # Prints "<class 'int'>"
print(x) # Prints "3"
print(x + 1) # Addition; prints "4"
print(x - 1) # Subtraction; prints "2"
print(x * 2) # Multiplication; prints "6"
print(x ** 2) # Exponentiation; prints "9"
x += 1
print(x) # Prints "4"
x *= 2
print(x) # Prints "8"
y = 2.5
print(type(y)) # Prints "<class 'float'>"
print(y, y + 1, y * 2, y ** 2) # Prints "2.5 3.5 5.0 6.25"
需要注意的是,Python中没有 x++ 和 x-- 的操作符。
Python还有复杂数字的内置类型,具体细节可以查看文档。
布尔型:Python实现了所有的布尔逻辑,但用的是英语,而不是我们习惯的操作符(比如&&和||等)。
t = True
f = False
print(type(t)) # Prints "<class 'bool'>"
print(t and f) # Logical AND; prints "False"
print(t or f) # Logical OR; prints "True"
print(not t) # Logical NOT; prints "False"
print(t != f) # Logical XOR; prints "True"
字符串:Python对字符串的支持非常棒。
hello = 'hello' # String literals can use single quotes
world = "world" # or double quotes; it does not matter.
print(hello) # Prints "hello"
print(len(hello)) # String length; prints "5"
hw = hello + ' ' + world # String concatenation
print(hw) # prints "hello world"
hw12 = '%s %s %d' % (hello, world, 12) # sprintf style string formatting
print(hw12) # prints "hello world 12"
字符串对象有一系列有用的方法,比如:
s = "hello"
print(s.capitalize()) # Capitalize a string; prints "Hello"
print(s.upper()) # Convert a string to uppercase; prints "HELLO"
print(s.rjust(7)) # Right-justify a string, padding with spaces; prints " hello"
print(s.center(7)) # Center a string, padding with spaces; prints " hello "
print(s.replace('l', '(ell)')) # Replace all instances of one substring with another;# prints "he(ell)(ell)o"
print(' world '.strip()) # Strip leading and trailing whitespace; prints "world"
如果想详细查看字符串方法,请看文档。
容器Containers
译者注:有知友建议container翻译为复合数据类型,供读者参考。
Python有以下几种容器类型:列表(lists)、字典(dictionaries)、集合(sets)和元组(tuples)。
列表Lists
列表就是Python中的数组,但是列表长度可变,且能包含不同类型元素。
xs = [3, 1, 2] # Create a list
print(xs, xs[2]) # Prints "[3, 1, 2] 2"
print(xs[-1]) # Negative indices count from the end of the list; prints "2"
xs[2] = 'foo' # Lists can contain elements of different types
print(xs) # Prints "[3, 1, 'foo']"
xs.append('bar') # Add a new element to the end of the list
print(xs) # Prints "[3, 1, 'foo', 'bar']"
x = xs.pop() # Remove and return the last element of the list
print(x, xs) # Prints "bar [3, 1, 'foo']"
列表的细节,同样可以查阅文档。
切片Slicing:为了一次性地获取列表中的元素,Python提供了一种简洁的语法,这就是切片。
nums = list(range(5)) # range is a built-in function that creates a list of integers
print(nums) # Prints "[0, 1, 2, 3, 4]"
print(nums[2:4]) # Get a slice from index 2 to 4 (exclusive); prints "[2, 3]"
print(nums[2:]) # Get a slice from index 2 to the end; prints "[2, 3, 4]"
print(nums[:2]) # Get a slice from the start to index 2 (exclusive); prints "[0, 1]"
print(nums[:]) # Get a slice of the whole list; prints "[0, 1, 2, 3, 4]"
print(nums[:-1]) # Slice indices can be negative; prints "[0, 1, 2, 3]"
nums[2:4] = [8, 9] # Assign a new sublist to a slice
print(nums) # Prints "[0, 1, 8, 9, 4]"
在Numpy数组的内容中,我们会再次看到切片语法。
循环Loops:我们可以这样遍历列表中的每一个元素:
animals = ['cat', 'dog', 'monkey']
for animal in animals:print(animal)
# Prints "cat", "dog", "monkey", each on its own line.
如果想要在循环体内访问每个元素的指针,可以使用内置的**enumerate**函数
animals = ['cat', 'dog', 'monkey']
for idx, animal in enumerate(animals):print('#%d: %s' % (idx + 1, animal))
# Prints "#1: cat", "#2: dog", "#3: monkey", each on its own line
列表推导List comprehensions:在编程的时候,我们常常想要将一种数据类型转换为另一种。下面是一个简单例子,将列表中的每个元素变成它的平方。
nums = [0, 1, 2, 3, 4]
squares = []
for x in nums:squares.append(x ** 2)
print(squares) # Prints [0, 1, 4, 9, 16]
使用列表推导,你就可以让代码简化很多:
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print(squares) # Prints [0, 1, 4, 9, 16]
列表推导还可以包含条件:
nums = [0, 1, 2, 3, 4]
even_squares = [x ** 2 for x in nums if x % 2 == 0]
print(even_squares) # Prints "[0, 4, 16]"
字典Dictionaries
字典用来储存(键, 值)对,这和Java中的Map差不多。你可以这样使用它:
d = {'cat': 'cute', 'dog': 'furry'} # Create a new dictionary with some data
print(d['cat']) # Get an entry from a dictionary; prints "cute"
print('cat' in d) # Check if a dictionary has a given key; prints "True"
d['fish'] = 'wet' # Set an entry in a dictionary
print(d['fish']) # Prints "wet"
# print(d['monkey']) # KeyError: 'monkey' not a key of d
print(d.get('monkey', 'N/A')) # Get an element with a default; prints "N/A"
print(d.get('fish', 'N/A')) # Get an element with a default; prints "wet"
del d['fish'] # Remove an element from a dictionary
print(d.get('fish', 'N/A')) # "fish" is no longer a key; prints "N/A"
想要知道字典的其他特性,请查阅文档。
循环Loops:在字典中,用键来迭代更加容易。
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d:legs = d[animal]print('A %s has %d legs' % (animal, legs))
# Prints "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"
如果你想要访问键和对应的值,那就使用 items 方法:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal, legs in d.items():print('A %s has %d legs' % (animal, legs))
# Prints "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"
字典推导Dictionary comprehensions:和列表推导类似,但是允许你方便地构建字典。
nums = [0, 1, 2, 3, 4]
even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}
print(even_num_to_square) # Prints "{0: 0, 2: 4, 4: 16}"
集合Sets
集合是独立不同个体的无序集合。示例如下:
animals = {'cat', 'dog'}
print('cat' in animals) # Check if an element is in a set; prints "True"
print('fish' in animals) # prints "False"
animals.add('fish') # Add an element to a set
print('fish' in animals) # Prints "True"
print(len(animals)) # Number of elements in a set; prints "3"
animals.add('cat') # Adding an element that is already in the set does nothing
print(len(animals)) # Prints "3"
animals.remove('cat') # Remove an element from a set
print(len(animals)) # Prints "2"
和前面一样,要知道更详细的,查看文档。
循环Loops:在集合中循环的语法和在列表中一样,但是集合是无序的,所以你在访问集合的元素的时候,不能做关于顺序的假设。
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):print('#%d: %s' % (idx + 1, animal))
# Prints "#1: fish", "#2: dog", "#3: cat"
集合推导Set comprehensions:和字典推导一样,可以很方便地构建集合:
from math import sqrt
nums = {int(sqrt(x)) for x in range(30)}
print(nums) # Prints "{0, 1, 2, 3, 4, 5}"
元组Tuples
元组是一个值的有序列表(不可改变)。从很多方面来说,元组和列表都很相似。和列表最重要的不同在于,元组可以在字典中用作键,还可以作为集合的元素,而列表不行。例子如下:
d = {(x, x + 1): x for x in range(10)} # Create a dictionary with tuple keys
t = (5, 6) # Create a tuple
print(type(t)) # Prints "<class 'tuple'>"
print(d[t]) # Prints "5"
print(d[(1, 2)]) # Prints "1"
文档有更多元组的信息。
函数Functions
Python函数使用def来定义函数:
def sign(x):if x > 0:return 'positive'elif x < 0:return 'negative'else:return 'zero'for x in [-1, 0, 1]:print(sign(x))
# Prints "negative", "zero", "positive"
我们常常使用可选参数来定义函数:
def hello(name, loud=False):if loud:print('HELLO, %s!' % name.upper())else:print('Hello, %s' % name)hello('Bob') # Prints "Hello, Bob"
hello('Fred', loud=True) # Prints "HELLO, FRED!"
函数还有很多内容,可以查看文档。
类Classes
Python对于类的定义是简单直接的:
class Greeter(object):# Constructordef __init__(self, name):self.name = name # Create an instance variable# Instance methoddef greet(self, loud=False):if loud:print('HELLO, %s!' % self.name.upper())else:print('Hello, %s' % self.name)g = Greeter('Fred') # Construct an instance of the Greeter class
g.greet() # Call an instance method; prints "Hello, Fred"
g.greet(loud=True) # Call an instance method; prints "HELLO, FRED!"
更多类的信息请查阅文档。
【CS231n】斯坦福大学李飞飞视觉识别课程笔记(一):Python Numpy教程(1)
【CS231n】斯坦福大学李飞飞视觉识别课程笔记(二):Python Numpy教程(2)
【CS231n】斯坦福大学李飞飞视觉识别课程笔记(三):Python Numpy教程(3)
这篇关于【CS231n】斯坦福大学李飞飞视觉识别课程笔记(一):Python Numpy教程(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





