本文主要是介绍深度学习论文笔记(六)--- FCN-2015年(Fully Convolutional Networks for Semantic Segmentation),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

深度学习论文笔记(六)--- FCN 全卷积网络
FullyConvolutional Networks for Semantic Segmentation
Author:J Long , E Shelhamer, T Darrell
Year: 2015
1、 导引
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述(概率),比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。
而要做SemanticSegmentation(语义分割),希望能够直接输出一幅分割图像结果,所以就有了本篇FCN网络的提出。
2、模型解读
①FCN将传统CNN中的全连接层转化成一个个的卷积层。如下图所示,在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率。FCN将这3层表示为卷积层,卷积核的大小(宽,高,通道数)分别为(1,1,4096)、(1,1,4096)、(1,1,1000)。所有的层都是卷积层,故称为全卷积网络。
②但是,经过多次卷积(还有pooling)以后,得到的图像越来越小,分辨率越来越低。为了从这个分辨率低的粗略图像恢复到原图的分辨率,FCN使用了增采样操作。这个增采样是通过反卷积来实现的(deconvolution),文中用的反卷积操作很简单,后来有其他人就在反卷积这一步上做了进一步优化,使得分割结果更为准确。
③对第5层的输出(32倍放大)反卷积到原图大小,得到的结果还是不够精确,还是有细节内容丢失了。于是作者采用skiplayer的方法,将第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,结果就精细一些了。下图是这个卷积和反卷积上采样的过程:
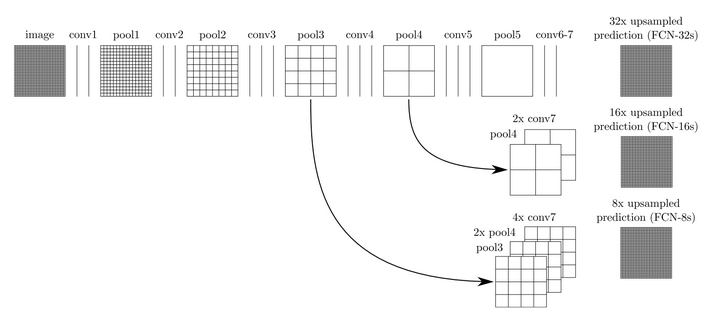
我们来把位置稍微调整一下利于理解:
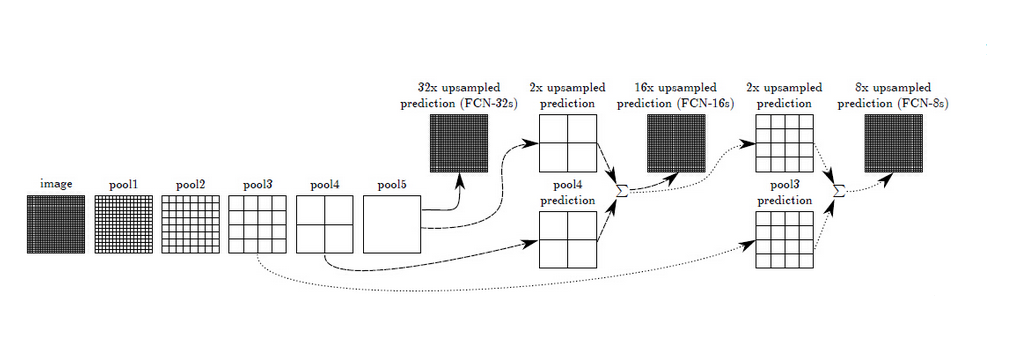
在浅层处减小upsampling的步长,得到的finelayer 和 高层得到的coarselayer做融合,然后再upsampling得到输出。这种做法兼顾local和global信息,即文中说的combiningwhat and where,取得了不错的效果提升。FCN-32s为59.4,FCN-16s提升到了62.4,FCN-8s提升到62.7。可以看出效果还是很明显的。
3、 创新点分析
①由于没有全连接层的存在,所以输入图像的尺寸要求并不固定了。这个原因是因为全连接层是一个矩阵乘法的操作,可以自己去想一想。
②实现的是对每个像素点的分类预测:
Pixel-wiseprediction
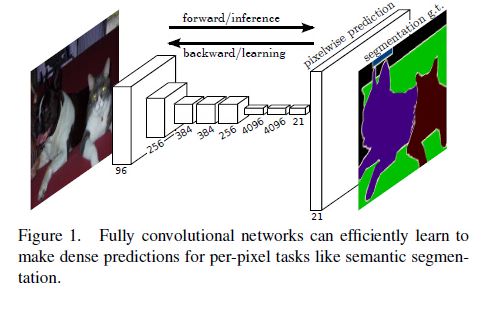
之所以能做到这样,是因为卷积层的输出的结果是datamap,而不是一个向量!经过反卷积后得到与原图一样大小的1000层heatmap,每一层代表一个类,然后观察每个位置的像素,在哪一层它这个点对应的值最大,就认为这个像素点属于这一层的类,
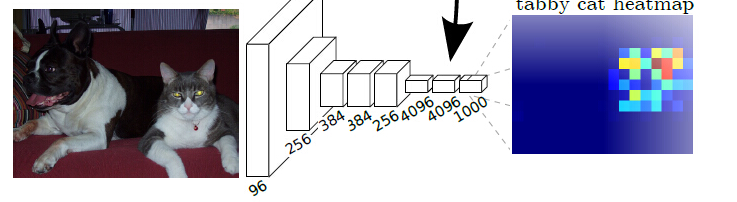
就比如图中点猫那个位置的点,在tabby cat这个类的heatmap上表现的值很高,所以认为那一坨像素点是属于tabby cat这个类的。
从而这样对每个像素点进行分类,最后输出的就是分割好的图像。
这篇关于深度学习论文笔记(六)--- FCN-2015年(Fully Convolutional Networks for Semantic Segmentation)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




