本文主要是介绍手撕LRU 最近最少使用缓存淘汰策略 + LinkedHashMap,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LRU 最近最少使用缓存淘汰策略
- 1 LRU 算法就是一种缓存淘汰策略
- 2 手撕LRU
- 3 LinkedHashMap 常见面试题
1 LRU 算法就是一种缓存淘汰策略
计算机的缓存容量有限,如果缓存满了就要删除一些内容,给新内容腾位置。但问题是,删除哪些内容呢?我们肯定希望删掉哪些没什么用的缓存,而把有用的数据继续留在缓存里,方便之后继续使用。那么,什么样的数据,我们判定为「有用的」的数据呢?
LRU 缓存淘汰算法就是一种常用策略。LRU 的全称是 Least Recently Used,也就是说认为最近使用过的数据应该是是「有用的」,很久都没用过的数据应该是无用的,内存满了就优先删那些很久没用过的数据。
ps:数据库采用改进的LRU 为了解决select *这种只使用一次,但是会把热数据:真正频率较高的挤到后面的问题。
2 手撕LRU
=========参考题解=========
设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构
实现LRUCache类:
LRUCache(int capacity)以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key)如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。void put(int key, int value)- 如果关键字 key 已经存在,则变更其数据值 value ;
- 如果不存在,则向缓存中插入该组 key-value 。
- 如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入:
[“LRUCache”, “put”, “put”, “get”, “put”, “get”, “put”, “get”, “get”, “get”]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出:
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释:
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
⭐️要点👿
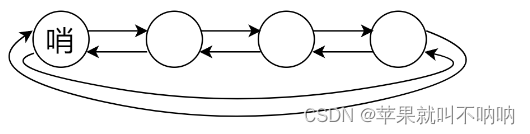
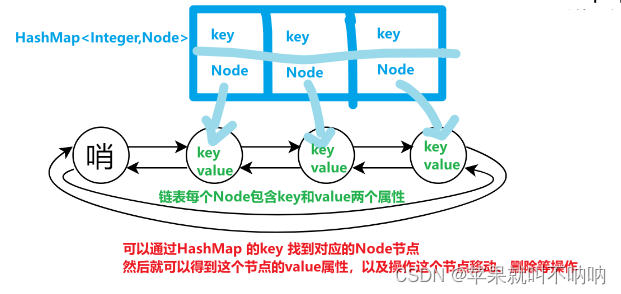
- 定义一个双向链表:链表中的每个Node 包括:key value两个属性。双向链表+dummy节点+形成一个环结构
public static class Node{ //定义一个双向链表静态内部类 每个节点有key+value,还有prev指针 next指针(实现双向)int key;int value;Node prev;Node next;Node(int key, int value){ // 构造器this.key = key;this.value = value;}}
- 定义一个Hashmap:<key, Node>,为了方便根据 key 查找到对应的Node
capacity: 这是LRUCache类中存储缓存容量的变量,应该在对象创建后不可更改,因此使用 private final 来确保其值在对象创建后不会被修改。
dummy 节点: 哨兵节点是双向链表中的一个特殊节点,它不存储任何实际的数据,仅用于简化链表操作。因为哨兵节点在整个对象生命周期中不会改变,所以将其声明为 private final。
myhashmap哈希表: 这是LRUCache类中存储键值对的哈希表,也应该在对象创建后不可更改。使用 private final 可以确保在对象创建后,哈希表的引用不会指向其他对象。
总的来说,使用 private final 可以增强代码的安全性和稳定性,防止意外的修改或赋值操作,确保这些重要的成员变量在对象创建后保持不变。private final int capacity; // 存储上限 private final Node dummy = new Node(0,0); // 新建一个dummy节点 private final HashMap<Integer, Node> myhashmap = new HashMap<>(); // 声明一个hashmap用于存储key-Node
int get(int key)如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
🔴 先去Hashmap中寻找有无存在key 【调用getNode(key)】
a. 若有则返回对应的Node,再返回Node.value 。与此同时,由于操作了该节点,因此将该节点移动到链表头部。
b. 若无则返回-1。
void put(int key, int value)
- 如果关键字 key 已经存在,则变更其数据值 value ;
- 如果不存在,则向缓存中插入该组 key-value 。
- 如果插入操作导致关键字数量超过 capacity,则应该 逐出 最久未使用的关键字。
🔴先去Hashmap中寻找有无存在key 【调用getNode(key)】
a. 若有则返回对应的Node,修改Node.value属性,即可实现更改值的目的。与此同时,由于操作了该节点,因此将该节点移动到链表头部。
b. 如果没有,则新建一个Node节点包含key-Node,并将这个新建的节点放进链表头部。与此同时,在Hashmap中也添加这个<key,Node>
// 最近最少使用 用于页面置换算法,淘汰最近最少使用的页面
class LRUCache {public static class Node{ //定义一个双向链表静态内部类 每个节点有key+value,还有prev指针 next指针(实现双向)int key;int value;Node prev;Node next;Node(int key, int value){ // 构造器this.key = key;this.value = value;}}private final int capacity; // 存储上限private final Node dummy = new Node(0,0); // 新建一个dummy节点private final HashMap<Integer, Node> myhashmap = new HashMap<>(); // 声明一个hashmap用于存储key-Node// 【初始化】LRUCache的构造方法// 参数capacity用来指定LRU缓存的容量,即缓存可以存储的key-value对的数量上限public LRUCache(int capacity) { this.capacity = capacity;// 构造环 放在这里的原因:在Java中,类字段初始化必须在构造方法内或者直接初始化字段时进行,不能在类的主体外进行语句级别的初始化操作,所以不能把下面两行放到构造器外面。dummy.prev = dummy;dummy.next = dummy;}// 如果有对应的key,则返回key对应的value。如果没有就返回-1public int get(int key) {Node node = getNode(key); // 去尝试拿到这个nodeif(node != null) return node.value;else return -1;}// 如果key已经存在,则变更其数据值value // 如果key不存在,则向缓存中插入该组 key-value// 如果插入操作导致键值对数量超过 capacity ,则应该 逐出 最久未使用的关键字public void put(int key, int value) { Node node = getNode(key); // 去尝试拿到这个nodeif(node == null) { // 如果没拿到,即key不存在,则向缓存中插入该组 key-valueNode newNode = new Node(key,value);pushFront(newNode); // 添加到顶部myhashmap.put(key,newNode); // 添加到hashmapif(myhashmap.size() > capacity){ // 如果插入操作导致键值对数量超过 capacity ,则应该 逐出 最久未使用的关键字Node backNode = dummy.prev;remove(backNode); // 从链表移走最后一个节点myhashmap.remove(backNode.key); // 从hashmap移走最后一个节点对应的key-Node键值对}}else{ // 如果拿到,即key已经存在,则变更其数据值value node.value = value;}}// 【辅助方法】// 1.在hashmap中根据key拿到Nodeprivate Node getNode(int key){if(!myhashmap.containsKey(key)){ // 如果没有返回nullreturn null; }Node node = myhashmap.get(key); // 如果有就把这个Node找出来remove(node); // 1.把他从原来的链表中删了pushFront(node); // 2.把他放到链表最开始return node; // 3.返回这个节点}// 2.把节点从链表中删了 ——前后节点跳跃过node连接即可private void remove(Node node){node.prev.next = node.next;node.next.prev = node.prev;}// 3.把节点放到链表最开始private void pushFront(Node node){node.next = dummy.next;dummy.next.prev = node;node.prev = dummy;dummy.next = node;}
}/*** Your LRUCache object will be instantiated and called as such:* LRUCache obj = new LRUCache(capacity);* int param_1 = obj.get(key);* obj.put(key,value);*/
3 LinkedHashMap 常见面试题
LinkedHashMap 常见面试题

这篇关于手撕LRU 最近最少使用缓存淘汰策略 + LinkedHashMap的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




